







句向量的产生
我们需要找到一种方法,将离散的词向量,加工成句向量。有一种简单粗暴的方法,直接将所有词向量相加。不过我们依旧是在词向量的空间上理解句子,如果句子和词语是有本质区别的事物,那么他们所属的空间应该也不同。直接使用加法,没有办法创造出一个全新的空间。
如何来表达句子含义
1.TF-IDF -----非学习方式
将文章向量化,忽略了词语之间顺序的信息
2.CBOW训练的词向量相机得到句向量 ------学习词向量方式
3.Skip-Gram训练的词向量相加得到句向量 ------学习词向量方式
4.Sequence to Sequence方式 ------学习句向量方式
Encoder和Decoder
Seq2Seq,一个把句子转化为向量的encoder过程,再将向量用于其他目的的decoder过程(如图片生成,对话,感情判断,翻译等应用)
Seq2Seq
中英文翻译项目
给出一系列中英文对照样本,训练一个Seq2Seq模型,来进行英文到中文的翻译,这是一个输入输出不定长的问题,所以用Seq2Seq解决
各国语言翻译的数据集可以从www.manything.org/ankl获取
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
batch_size = 64 # Batch size for training.
epochs = 100 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 10000 # Number of samples to train on.
data_path = r'D:\NLP\cmn.txt'
# Vectorize the data.
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n') # 从文本提取的语料库
print("一共有%d条文本" %len(lines))
lines:

lines一共21117条文本
for line in lines[: min(num_samples, len(lines) - 1)]:
# 两者取最小值,如果训练样本大于10000,我们只要10000条作为训练样本,否则,选取总条数数目-1条样本作为训练数据
input_text, target_text = line.split('\t')
print(input_text)
print(target_text)
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
#得到了文本的列表,输入文本列表,目标文本列表(翻译成中文的文本列表),输入文本里的字节集合,目标文本里的字节集合



input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
# 编码器解码器的输入输出序列,应该满足至少大于所有样本里面最大长度,不然输入出错,或者输出长度不够
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
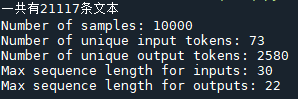
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
作tokenlization
可以以words作tokenlization (数据集大的时候)
也可以以character作tokenlization (小规模数据集)
# mapping token to index, easily to vectors
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
对输入输出的所有不同字符标上索引

# np.zeros(shape, dtype, order)
# shape is an tuple, in here 3D
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
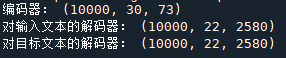
print("编码器:",encoder_input_data.shape)
print("对输入文本的解码器:",decoder_input_data.shape)
print("对目标文本的解码器:",decoder_target_data.shape)
# input_texts contain all english sentences
# output_texts contain all chinese sentences
# zip('ABC','xyz') ==> Ax By Cz, looks like that
# the aim is: vectorilize text, 3D
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
# 3D vector only z-index has char its value equals 1.0
encoder_input_data[i, t, input_token_index[char]] = 1.
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
# igone t=0 and start t=1, means
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
创建encoder-decoder的大表,为三维表,每个样本的一句话对应里面一个二维向量,在每个样本对应的位置上每个字符位置上,在索引所对应的地方填上1
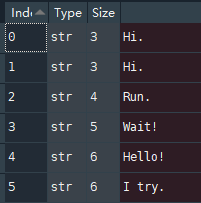
比如说第一个样本是:
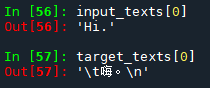
那么输入三个字符H i . 依次的索引是28,54,8
那么在第一行的索引28处为1,第二行的索引54处为1,第三行的索引8处为1。
对输入文本的解码器同理,但是对于目标文本的解码器是不包含第一个字符的。
目标文本四个字符:\t 嗨 。\n,索引分别为0,495,54,1,那么对于目标文本的解码器只有三行,1的位置索引分别别问495,54,1
这样被句话就被一个矩阵表示了
encoder_input_data和decoder_input_data作为模型训练的data,target_input_data作为模型训练的label。
训练模型
# Define an input sequence and process it.
# input prodocts keras tensor, to fit keras model!
# 1x73 vector
# encoder_inputs is a 1x73 tensor!
encoder_inputs = Input(shape=(None, num_encoder_tokens))
# units=256, return the last state in addition to the output
encoder_lstm = LSTM((latent_dim), return_state=True)
# LSTM(tensor) return output, state-history, state-current
encoder_outputs, state_h, state_c = encoder_lstm(encoder_inputs)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
# ============above: one RNN/LSTM input to output and state==============
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM((latent_dim), return_sequences=True, return_state=True)
# obtain output
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,initial_state=encoder_states)
# ============above: another RNN/LSTM decoder parts====================
# dense 2580x1 units full connented layer
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
# why let decoder_outputs go through dense ?
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn, groups layers into an object
# with training and inference features
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
# model(input, output)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Run training
# compile -> configure model for training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# model optimizsm
model.fit([encoder_input_data, decoder_input_data], # 输入
decoder_target_data, # 输出
batch_size=batch_size, # batch_size = 64
epochs=epochs, # epochs = 100
validation_split=0.2) # 每次拿20%数据作为验证数据
# Save model
model.save('seq2seq.h5')
10000个数据,每次取不同80%作为train_data,20%作为val_data,那么8000个训练数据,按照每批64个训练,一共有125批,所以训练完
8000个数据一轮是125批。
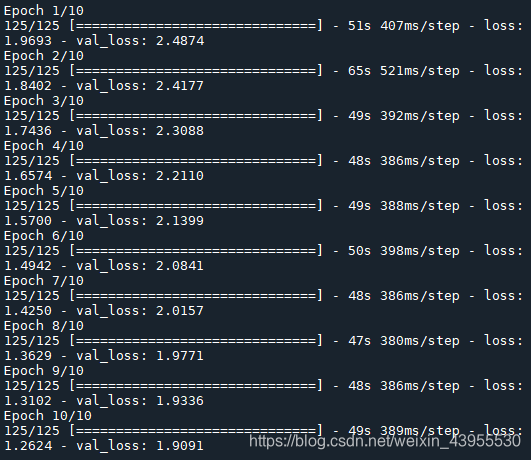
Seq2Seq中的encoder是一个LSTM模型用来对输入的英文语句提取特征,state_h 存放的是最后一个时间步的 hidden state,state_c 存放的是最后一个时间步的 cell state。前一个LSTM将最后一个状态的h和c输出,扔掉了decoder,加一个分类器softmax,完成了对特征的提取,作为第二个LSTM的输入。
这个还没有收敛,可以加大训练轮数epoch = 100
# Next: inference mode (sampling).
# Here's the drill:
# 1) encode input and retrieve initial decoder state
# 2) run one step of decoder with this initial state
# and a "start of sequence" token as target.
# Output will be the next target token
# 3) Repeat with the current target token and current states
# Define sampling models
encoder_model = Model(encoder_inputs, encoder_states)
# tensor 73x1
decoder_state_input_h = Input(shape=(latent_dim,))
# tensor 73x1
decoder_state_input_c = Input(shape=(latent_dim,))
# tensor 146x1
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
# lstm
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
#
decoder_states = [state_h, state_c]
#
decoder_outputs = decoder_dense(decoder_outputs)
#
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# Reverse-lookup token index to decode sequences back to
# something readable.
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index['\t']] = 1.
# this target_seq you can treat as initial state
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ''
while not stop_condition: # 如果不到终止符,就一直生成中文语句
# 把上一个状态不断输入,得到后面的状态不断输出
output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
# Sample a token
# argmax: Returns the indices of the maximum values along an axis
# just like find the most possible char
sampled_token_index = np.argmax(output_tokens[0, -1, :])
# find char using index
sampled_char = reverse_target_char_index[sampled_token_index]
# and append sentence
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if (sampled_char == '\n' or len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
# append then ?
# creating another new target_seq
# and this time assume sampled_token_index to 1.0
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
# update states, frome the front parts
states_value = [h, c]
return decoded_sentence
for seq_index in range(100,200):
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
得到索引对应的中文和英文分别是多少
然后对输入的句子再进行编码,解码得到其对应的中文应该是啥
实现日期的翻译
从31-04-26翻译成英文日期表示:26/Apr/1931
# -*- coding: utf-8 -*-
"""
Created on Mon May 17 17:04:48 2021
@author: zhongxi
"""
# [Sequence to Sequence Learning with Neural Networks](https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf)
import tensorflow as tf
from tensorflow import keras
import numpy as np
import tensorflow_addons as tfa
import datetime
PAD_ID = 0
class DateData:
def __init__(self, n):
np.random.seed(1)
self.date_cn = []
self.date_en = []
for timestamp in np.random.randint(143835585, 2043835585, n):
date = datetime.datetime.fromtimestamp(timestamp)
self.date_cn.append(date.strftime("%y-%m-%d"))
self.date_en.append(date.strftime("%d/%b/%Y"))
self.vocab = set(
[str(i) for i in range(0, 10)] + ["-", "/", "<GO>", "<EOS>"] + [
i.split("/")[1] for i in self.date_en])
self.v2i = {v: i for i, v in enumerate(sorted(list(self.vocab)), start=1)}
self.v2i["<PAD>"] = PAD_ID
self.vocab.add("<PAD>")
self.i2v = {i: v for v, i in self.v2i.items()}
self.x, self.y = [], []
for cn, en in zip(self.date_cn, self.date_en):
self.x.append([self.v2i[v] for v in cn])
self.y.append(
[self.v2i["<GO>"], ] + [self.v2i[v] for v in en[:3]] + [
self.v2i[en[3:6]], ] + [self.v2i[v] for v in en[6:]] + [
self.v2i["<EOS>"], ])
self.x, self.y = np.array(self.x), np.array(self.y)
self.start_token = self.v2i["<GO>"]
self.end_token = self.v2i["<EOS>"]
def sample(self, n=64):
bi = np.random.randint(0, len(self.x), size=n)
bx, by = self.x[bi], self.y[bi]
decoder_len = np.full((len(bx),), by.shape[1] - 1, dtype=np.int32)
return bx, by, decoder_len
def idx2str(self, idx):
x = []
for i in idx:
x.append(self.i2v[i])
if i == self.end_token:
break
return "".join(x)
@property
def num_word(self):
return len(self.vocab)
class Seq2Seq(keras.Model):
def __init__(self, enc_v_dim, dec_v_dim, emb_dim, units, max_pred_len, start_token, end_token):
super().__init__()
self.units = units
# encoder
self.enc_embeddings = keras.layers.Embedding(
input_dim=enc_v_dim, output_dim=emb_dim, # [enc_n_vocab, emb_dim]
embeddings_initializer=tf.initializers.RandomNormal(0., 0.1),
)
self.encoder = keras.layers.LSTM(units=units, return_sequences=True, return_state=True)
# decoder
self.dec_embeddings = keras.layers.Embedding(
input_dim=dec_v_dim, output_dim=emb_dim, # [dec_n_vocab, emb_dim]
embeddings_initializer=tf.initializers.RandomNormal(0., 0.1),
)
self.decoder_cell = keras.layers.LSTMCell(units=units)
decoder_dense = keras.layers.Dense(dec_v_dim)
# train decoder
self.decoder_train = tfa.seq2seq.BasicDecoder(
cell=self.decoder_cell,
sampler=tfa.seq2seq.sampler.TrainingSampler(), # sampler for train
output_layer=decoder_dense
)
# predict decoder
self.decoder_eval = tfa.seq2seq.BasicDecoder(
cell=self.decoder_cell,
sampler=tfa.seq2seq.sampler.GreedyEmbeddingSampler(), # sampler for predict
output_layer=decoder_dense
)
self.cross_entropy = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.opt = keras.optimizers.Adam(0.01)
self.max_pred_len = max_pred_len
self.start_token = start_token
self.end_token = end_token
def encode(self, x):
embedded = self.enc_embeddings(x)
init_s = [tf.zeros((x.shape[0], self.units)), tf.zeros((x.shape[0], self.units))]
o, h, c = self.encoder(embedded, initial_state=init_s)
return [h, c]
def inference(self, x):
s = self.encode(x)
done, i, s = self.decoder_eval.initialize(
self.dec_embeddings.variables[0],
start_tokens=tf.fill([x.shape[0], ], self.start_token),
end_token=self.end_token,
initial_state=s,
)
pred_id = np.zeros((x.shape[0], self.max_pred_len), dtype=np.int32)
for l in range(self.max_pred_len):
o, s, i, done = self.decoder_eval.step(
time=l, inputs=i, state=s, training=False)
pred_id[:, l] = o.sample_id
return pred_id
def train_logits(self, x, y, seq_len):
s = self.encode(x)
dec_in = y[:, :-1] # ignore <EOS>
dec_emb_in = self.dec_embeddings(dec_in)
o, _, _ = self.decoder_train(dec_emb_in, s, sequence_length=seq_len)
logits = o.rnn_output
return logits
def step(self, x, y, seq_len):
with tf.GradientTape() as tape:
logits = self.train_logits(x, y, seq_len)
dec_out = y[:, 1:] # ignore <GO>
loss = self.cross_entropy(dec_out, logits)
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss.numpy()
def train():
# get and process data
data = DateData(4000)
print("Chinese time order: yy/mm/dd ", data.date_cn[:3], "\nEnglish time order: dd/M/yyyy ", data.date_en[:3])
print("vocabularies: ", data.vocab)
print("x index sample: \n{}\n{}".format(data.idx2str(data.x[0]), data.x[0]),
"\ny index sample: \n{}\n{}".format(data.idx2str(data.y[0]), data.y[0]))
model = Seq2Seq(
data.num_word, data.num_word, emb_dim=16, units=32,
max_pred_len=11, start_token=data.start_token, end_token=data.end_token)
# training
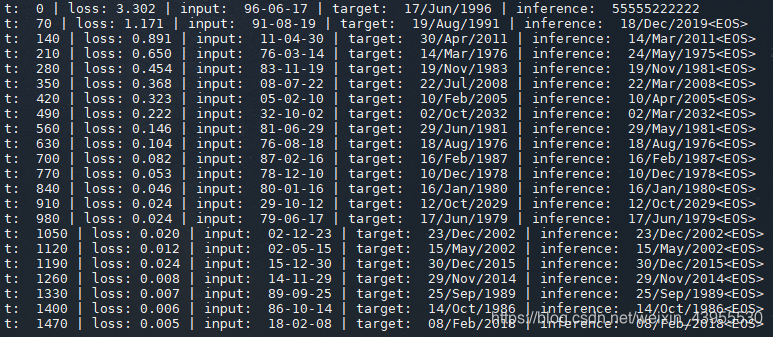
for t in range(1500):
bx, by, decoder_len = data.sample(32)
loss = model.step(bx, by, decoder_len)
if t % 70 == 0:
target = data.idx2str(by[0, 1:-1])
pred = model.inference(bx[0:1])
res = data.idx2str(pred[0])
src = data.idx2str(bx[0])
print(
"t: ", t,
"| loss: %.3f" % loss,
"| input: ", src,
"| target: ", target,
"| inference: ", res,
)
if __name__ == "__main__":
train()














 3025
3025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









