







将数据从高维映射到低维。
PCA算法:主成分分析
-
Principal Component Analysis
-
其为无监督问题,基于方差提取最有价值的信息。
-
目的:对于 N N N维的数据,寻找 K K K个单位正交基,将原始数据投影到这些基上面,则可以将原始数据从 N N N维降到 K K K维。寻找这些基的原则为:1.希望投影后的投影值尽可能分散,使得所有数据变换为这个基上的坐标表示后,方差值最大;2.选择第二个基时只能在与第一个基正交的方向上选择,因此最终选择的两个方向一定是正交的。
- 基变换:
- 基是正交的(即内积为0,或直观说相互垂直),基之间是线性无关的。
- 如下图所示,设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度,则该长度表示数据A投影到一维基B上的坐标值。

- 变换:数据与一个基做内积运算,结果作为第一个新的坐标分量;然后与第二个基做内积运算,结果作为第二个新坐标的分量 ;…
- 方差:
- V a r ( a ) = 1 m ∑ i = 1 m ( a i − μ ) 2 Var(a)=\frac{1}{m}\sum_{i=1}^{m}(a_{i}-\mu)^{2} Var(a)=m1∑i=1m(ai−μ)2
- 协方差:
- 可以用两个字段的协方差表示其相关性,当协方差为0时,表示两个字段完全独立。
- C o v ( a , b ) = 1 m ∑ i = 1 m ( a i b i ) Cov(a,b)=\frac{1}{m}\sum_{i=1}^{m}(a_{i}b_{i}) Cov(a,b)=m1∑i=1m(aibi)
- 基变换:
-
优化目标:将一组N维向量降为K维(K大于0,小于N),目标是选择K个单位正交基,使原始数据变换到这组基上后,各字段两两间协方差为0,字段的方差则尽可能大 。
- 协方差矩阵: 矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。
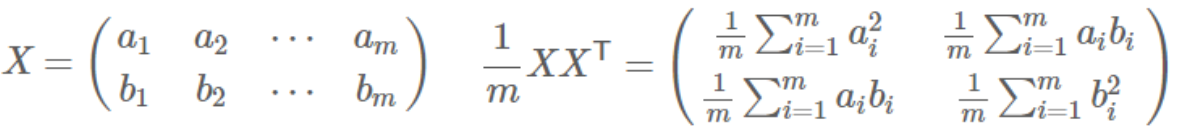
- 协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列 。

- 实对称矩阵:一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量:
E
=
(
e
1
,
e
2
,
.
.
.
,
e
n
)
E=(e_{1} , e_{2},...,e_{n})
E=(e1,e2,...,en) 。实对称阵可进行对角化:

- 根据特征值的从大到小,将特征向量从上到下排列,则用前K行组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y。
- 协方差矩阵: 矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。
-
PCA实例:

LDA算法:线性判别分析
- Linear Discriminant Analysis
- 用于分类任务中,数据预处理时的降维,它属于有监督学习。















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









