







特征过多造成方案难以选定,训练非常缓慢,所以可以选择大量减少特征数量——数据降维
数据降维能加速训练,滤掉噪声和不必要细节,有利于数据可视化,但流水线更复杂 ,维护难度更高。
本章将介绍两种主要的数据降维方法(投影和流形学习),学习三种数据降维技术(PCA、Kernel PCA、LLE)
The Curse of Dimensionality(维度的诅咒)
高位超立方体大多数点更接近边界,高位数据集很大可能非常稀疏。即训练集维度越高,过度拟合风险越大,且不能通过增加训练集数量解决。
Main Approaches for Dimensionality Reduction
Projection(投影)
训练实例在许多维度并不均匀分布,许多特征高度关联,高位空间训练实例受低维子空间影响。如图:所有训练实例挨着一个平面,将每个训练实例垂直投射于子空间(短线所示),进行投影降维。

降到如图所示二维,对应新特征为 z1、z2。

但投影在很多情况下子空间会弯曲或转动,如图所示瑞士卷玩具数据集:

简单降维(如放弃x3),会直接将瑞士卷不同层叠加挤压。

Manifold Learning(流形学习)
瑞士卷是二维流形例子:2D流形是能够在更高维度弯曲扭转的2D形状——d维流形是n维空间一部分,局部类似于d维超平面(瑞士卷2维超平面)
基于训练实例进行流行建模的降维算法称为流形学习,依赖于流形假设(假说):认为大多数高维能用低维流形重新表示。
MNIST数据集也是这种情况,即创造任意图像的自由度限制倾向于将数据集挤成更低维度的流形。
流形假设的隐含假设:如果能用低维流形表示,则分类或回归将变得更简单:


如上图所示决策边界在二维上是一条直线,在三维上就很复杂。
但不总是成立有时候更复杂:

即决策边界并不总是维度越低越简单。下面将介绍流行降维算法。
PCA
PCA(主成分分析法)是目前最流行的降维算法,先识别出最接近数据超平面,然后将数据投影其上。
Preserving the Variance(保留差异性)
选择正确超平面投影数据集很重要,如图所示实线投影保留最大差异性,虚线适中,点线最少。
保留最大差异性比其他两种投影丢信息更少:原始数据集与轴上投影均方距离更小。

Principal Components
PCA可以在训练集上识别哪条轴对差异性贡献度最高(上图中为实线表示),同时也能找出第二条轴对剩余差异性贡献最高(与第一条轴垂直),n维能找出n条这样的轴。
定义第i条轴的单位向量叫做第i个主成分,如上图中的c1,c2。
主成分方向不稳定:稍微打乱训练集重新运行PCA,有些主成分甚至会截然相反(通常还在一条轴上,两条主成分旋转后定义平面不变)
Singular Value Decomposition (SVD)奇异值分解法能够找到训练集主成分,这是一种标准矩阵分解技术,将训练集矩阵X分解为 U· Σ · VT,而这个VT中包含所有主成分。
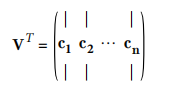
下面将用NumPy中的svd()获取训练集中所有主成分,提取前两个。
构建数据:
#Build 3D dataset:
np.random.seed(4)
m = 60
w1, w2 = 0.1, 0.3
noise = 0.1
angles = np.random.rand(m) * 3 * np.pi / 2 - 0.5
X = np.empty((m, 3))#返回m行3列随机值
X[:, 0] = np.cos(angles) + np.sin(angles)/2 + noise * np.random.randn(m) / 2
X[:, 1] = np.sin(angles) * 0.7 + noise * np.random.randn(m) / 2
X[:, 2] = X[:, 0] * w1 + X[:, 1] * w2 + noise * np.random.randn(m)
获取提取
#PCA using SVD decomposition
X_centered = X - X.mean(axis=0)#数据集中
U, s, Vt = np.linalg.svd(X_centered)
c1 = Vt.T[:, 0]
c2 = Vt.T[:, 1]
PCA假设数据集围绕原点集中,Scikit-Learn的PCA将会替你处理数据集中,其他库时要先数据集中。
Projecting Down to d Dimensions(低维度投影)
确定所有主成分后,就可以将数据降到d个主成分的超平面,且能确保保留更多差异性。
将训练集投影到低维度: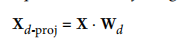
code实现投影到两个主成分定义平面:
#projecting down to d dimensions
W2 = Vt.T[:, :2]
X2D = X_centered.dot(W2)
Using Scikit-Learn
Scikit-Learn的PCA类会使用SVD分解实现主成分分析,以下代码将PCA降到二维(自动数据集中):
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
X2D = pca.fit_transform(X)
将其应用到数据集后可通过components_访问主成分(水平向量,第一个主成分pca.components_.T[:,0]).
Explained Variance Ratio(方差解释率)
通过explained_variance_ratio_ variable获取,表示每个主成分轴对整个数据集方差贡献率pca.explained_variance_ratio_得到:array([0.84248607, 0.14631839])
第一条轴贡献84.2%,第二条轴贡献14.6%,第三条轴不到1.2%。
Choosing the Right Number of Dimensions(选择正确数量维度)
除了直接选择要降维度,更好的方法是将靠前的主成分方差解释率以此增加至足够大方差,这时维度数量就是很好的选择(除非可视化——直接降到二维或三维)
以下代码计算PCA没有降维,而是计算要保留方差的95%所需要的最低维度数量:
数据准备:
#MNIST compression
from six.moves import urllib
try:
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
mnist.target = mnist.target.astype(np.int64)
except ImportError:
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
from sklearn.model_selection import train_test_split
X = mnist["data"]
y = mnist["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y)
保留最低维度:
pca = PCA()
pca.fit(X_train)
cumsum = np.cumsum(pca.explained_variance_ratio_)
d = np.argmax(cumsum >= 0.95) + 1
如此一来,设置n_components= d,再次运行PCA,更好的做法:直接将n_components设置为希望保留的方差比(0-1).
pca = PCA(n_components=0.95)
X_reduced = pca.fit_transform(X_train)
还可以将解释方差绘制成关于维度数量函数(cumsum),找到拐点,作为最小维度。

PCA for Compression(PCA压缩)
降维后的训练集所占空间小得多,将MNIST应用PCA后(95%方差),保留绝大差异性的同时,数据集大小降到不到原始的20%。合理的压缩比可以极大提高分类算法速度。
PCA投影上运行逆变换可以解压缩回原始维度数据,不可避免地会丢掉一部分信息(5%解释方差),但依然非常接近原始数据。原始数据与重建数据之间的均方距离称为重建方差(reconstruction error)。
下面代码将MNIST压缩再解压缩(inverse_transform()):
pca = PCA(n_components = 154)
X_reduced = pca.fit_transform(X_train)
X_recovered = pca.inverse_transform(X_reduced)

图像代码见jupyter,逆转换公式:Xrecovered = Xd‐proj · WdT
Incremental PCA(增量PCA)
主成分分析问题在于整个数据集进入内存才能运行SVD算法。但IPCA(增量主成分分析)可以将训练集分小批量训练,还可以在线应用PCA。
以下代码将MNIST分成100个小批量(Numpy的array_split()函数),将其提供给Scikit-Learn的Incremental PCA函数,将数据降到154维,为每个小批量调用partial_fit方法,而不是之前的fit()。
#Incremental PCA array_split
from sklearn.decomposition import IncrementalPCA
n_batches = 100
inc_pca = IncrementalPCA(n_components=154)
for X_batch in np.array_split(X_train, n_batches):
print(".", end="") # not shown in the book
inc_pca.partial_fit(X_batch)
X_reduced = inc_pca.transform(X_train)
或者可以使用Numpy的memmap,仅在需要时加载内存所需数据。这时IncrementalPCA可以用fit()
#Using memmap() create the memmap()
X_mm = np.memmap(filename, dtype="float32", mode="readonly", shape=(m, n))
batch_size = m // n_batches
inc_pca = IncrementalPCA(n_components=154, batch_size=batch_size)
inc_pca.fit(X_mm)
Randomized PCA(随机PCA)
随机PCA可以快速找到前d个主成分近似值:
rnd_pca = PCA(n_components=154, svd_solver="randomized", random_state=42)
X_reduced = rnd_pca.fit_transform(X_train)
Kernel PCA(核主成分分析)
核技巧可以隐性将实例映射到高维空间(空间向量),从而使SVM能够进行非线性分类和回归。
而核技巧也可以应用于PCA,使复杂非线性降维称为可能,这就是核主成分分析(kPCA),擅长投影保留实例的集群,甚至展开扭曲流形的数据集。
下列代码使用 Scikit-Learn’s KernelPCA,执行带有RBF核函数的kPCA:
X, t = make_swiss_roll(n_samples=1000, noise=0.2, random_state=42)
from sklearn.decomposition import KernelPCA
rbf_pca = KernelPCA(n_components = 2, kernel="rbf", gamma=0.04)
X_reduced = rbf_pca.fit_transform(X)
如图展示不同函数降到二维的瑞士卷(线性核函数:直接使用PCA,RBF核函数,sigmoid核函数Logistic):
from sklearn.decomposition import KernelPCA
lin_pca = KernelPCA(n_components = 2, kernel="linear", fit_inverse_transform=True)
rbf_pca = KernelPCA(n_components = 2, kernel="rbf", gamma=0.0433, fit_inverse_transform=True)
sig_pca = KernelPCA(n_components = 2, kernel="sigmoid", gamma=0.001, coef0=1, fit_inverse_transform=True)
y = t > 6.9
plt.figure(figsize=(11, 4))
for subplot, pca, title in ((131, lin_pca, "Linear kernel"), (132, rbf_pca, "RBF kernel, $\gamma=0.04$"), (133, sig_pca, "Sigmoid kernel, $\gamma=10^{-3}, r=1$")):
X_reduced = pca.fit_transform(X)
if subplot == 132:
X_reduced_rbf = X_reduced
plt.subplot(subplot)
#plt.plot(X_reduced[y, 0], X_reduced[y, 1], "gs")
#plt.plot(X_reduced[~y, 0], X_reduced[~y, 1], "y^")
plt.title(title, fontsize=14)
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=t, cmap=plt.cm.hot)
plt.xlabel("$z_1$", fontsize=18)
if subplot == 131:
plt.ylabel("$z_2$", fontsize=18, rotation=0)
plt.grid(True)

Selecting a Kernel and Tuning Hyperparameters
kPCA是一种无监督学习,没有明显性能指标来选择最佳核函数和超参数值,而降维通常是监督式学习,可以使用网格搜索来确定上述参数。
下列代码创造一个两步流水线:先用kPCA降至二维,再用逻辑回归分类;接下来再用GridSearchCV为kPCA找到最佳核和gamma值,从而获取最准确分类。
#Selecting a Kernel and Tuning Hyperparameters
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
clf = Pipeline([
("kpca", KernelPCA(n_components=2)),
("log_reg", LogisticRegression(solver="liblinear"))
])
param_grid = [{
"kpca__gamma": np.linspace(0.03, 0.05, 10),
"kpca__kernel": ["rbf", "sigmoid"]
}]
grid_search = GridSearchCV(clf, param_grid, cv=3)
grid_search.fit(X, y)
最佳核超参数:grid_search.best_params
另一种完全不受监督方法是选择重建误差最低的核、超参数,但这个重建要比线性PCA重建困难得多
如图所示,左上为原始3D瑞士卷,右上应用RBF核的kPCA得到的2D数据集。数学上等同,通过特征映射函数φ,将训练集映射到无限维度特征空间,再用线性PCA将转换后的训练集投影到2D平面。
但是如果我们对一个已经降维的实例进行线性PCA逆变换,重建点在特征空间,所以无法计算重建误差,只能在原始空间找到近似的重建原像,再用来计算平方距离,选取最小的重建原像误差核和超参数。
执行方法是训练一个监督式回归,以投影后的实例作为训练集,以原始实例作为目标,设置 fit_inverse_transform=True(默认为Flase,只有设置为True才有inverse_transform方法),Scikit-Learn就会自动执行。
rbf_pca = KernelPCA(n_components = 2, kernel="rbf", gamma=0.0433,
fit_inverse_transform=True)
X_reduced = rbf_pca.fit_transform(X)
X_preimage = rbf_pca.inverse_transform(X_reduced)
计算重建原像误差:
from sklearn.metrics import mean_squared_error
mean_squared_error(X, X_preimage)
选用交叉验证的网格搜索来寻找使原想重建误差最小的核和超参数。
LLE(局部线性嵌入)
LLE是另一种很强大的非线性降维(NLDR)技术,是一种流形学习技术,首先测量每个算法与其最近邻居线性相关,接着为训练集寻找最大程度上保留局部关系的低维表示,尤其适合展开没有太多噪音的弯曲流形。
下面代码使用Scikit-Learn的LocallyLinearEmbedding类来展开瑞士卷:如图整体保存不够好,左侧被挤压,右侧被拉长,但还是做得很不错了。

#LLE
X, t = make_swiss_roll(n_samples=1000, noise=0.2, random_state=41)
from sklearn.manifold import LocallyLinearEmbedding
lle = LocallyLinearEmbedding(n_components=2, n_neighbors=10, random_state=42)
X_reduced = lle.fit_transform(X)
plt.title("Unrolled swiss roll using LLE", fontsize=14)
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=t, cmap=plt.cm.hot)
plt.xlabel("$z_1$", fontsize=18)
plt.ylabel("$z_2$", fontsize=18)
plt.axis([-0.065, 0.055, -0.1, 0.12])
plt.grid(True)
下面说下原理:对于每个训练实例xi,识别最近的k个邻居,将xi重建为这些邻居的线性函数,找到权重w_i_j使xi与sum(w_i_j与xi)距离平方最小,若xi不是实例xi的最近k个邻居则w_i_j=0.
LLE第一步对局部关系线性建模
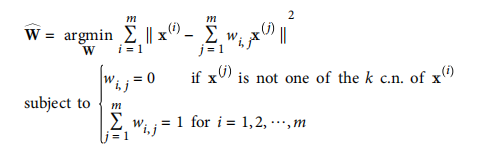
W是包含权重w_i_j的权重矩阵。完成后W_hat对训练实例局部线性关系编码。
将训练实例映射到d维空间,尽可能保留局部关系。
第二个约束:保留关系并降维,保持固定权重,在低维中找到每个实例印象最佳位置。
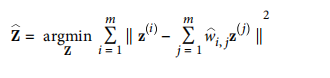
时间复杂度:
- 寻找k近邻O(m log(m)n log(k))
- 优化权重O(mnk^3)
- 低维表示O(dm^2)
此算法无法应用在大型数据集。
Other Dimensionality Reduction Techniques
Multidimensional Scaling (MDS)
多维度缩放:保持实例距离,降低维度:
from sklearn.manifold import MDS
mds = MDS(n_components=2, random_state=42)
X_reduced_mds = mds.fit_transform(X)
Isomap
等度量映射,将每个实例与最近邻居链接,创建连接图形,保留实例间的测地距离,降低维度。
from sklearn.manifold import Isomap
isomap = Isomap(n_components=2)
X_reduced_isomap = isomap.fit_transform(X)
t-Distributed
t-分布随机紧邻嵌入(t-SNE),主要用于可视化,尤其高维实例集群。在降维时使实例彼此靠近,不相似远离。
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_reduced_tsne = tsne.fit_transform(X)
Linear Discriminant Analysis (LDA)
线性判别(LDA)是一种分类算法,学习类别间最有区别轴,定义投影超平面,好处是投影类别尽可能分开,尤其适用其他分类算法
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
X_mnist = mnist["data"]
y_mnist = mnist["target"]
lda.fit(X_mnist, y_mnist)
X_reduced_lda = lda.transform(X_mnist)
画图展示:
titles = ["MDS", "Isomap", "t-SNE"]
plt.figure(figsize=(11,4))
for subplot, title, X_reduced in zip((131, 132, 133), titles,
(X_reduced_mds, X_reduced_isomap, X_reduced_tsne)):
plt.subplot(subplot)
plt.title(title, fontsize=14)
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=t, cmap=plt.cm.hot)
plt.xlabel("$z_1$", fontsize=18)
if subplot == 131:
plt.ylabel("$z_2$", fontsize=18, rotation=0)
plt.grid(True)
















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









