







前言
本期会讲解到 Spark 开发中大部分常见的操作算子,内容比较常用,建议大家先收藏。
学习目标
- 向Spark 传递函数
- RDD 的转换算子
- RDD 的行动算子
1. 向Spark 传递函数
Spark API 依赖 Driver 程序中的传递函数完成在集群上执行 RDD 转换并完成数据计算。在 Java API 中,函数所在的类需要实现 org.apache.spark.api.java.function 包中的接口。
Spark 提供了 lambda 表达式和 自定义 Function 类两种创建函数的方式。前者语法简洁、方便使用;后者可以在一些复杂应用场景中自定义需要的 Function 功能。
举个栗子,求 RDD 中数据的平方,并只保留不为0的数据。
可以用 lambda 表达式简明地定义 Function 实现,代码如下:
val input = sc.parallelize(List(-2,-1,0,1,2))
val rdd1 = input.map(x => x * x)
val rdd2 = rdd1.filter(x => x != 0 )
首先用 map() 对 RDD 中所有的数据进行求平方,然后用到 filter() 来筛选不为0的数据。
其中,map() 和 filter() 就是我们最常用的转换算子,map() 接收了 一个 lambda 表达式定义的函数,并把这个函数运用到 input 中的每一个元素,最后把函数计算后的返回结果作为结果 rdd1 中对应元素的值。
同样, filter() 也接收了一个 lambda 表达式定义的函数,并将 rdd1 中满足该函数的数据放入到了新的 rdd2 中返回。

Spark 提供了很丰富的处理 RDD 数据的操作算子,比如使用 distinct() 还可以继续对 rdd2 进行去重处理。
如果需要对 RDD 中每一个元素处理后生成多个输出,也有相应的算子,比如 flatMap(),它和 map() 类似,也是将输入函数应用到 RDD 中的每个元素,不过返回的不是一个元素了,而是一个返回值序列的迭代器。
最终得到的输出是一个包含各个迭代器可访问的所有元素的 RDD,flatMap() 最经典的一个用法就是把输入的一行字符串切分为一个个的单词。
举个栗子,将行数据切分成单词,对比下 map() 与 flat() 的不同。
val lines = sc.parallelize(List("hello spark","hi,flink"))
val rdd1 = lines.map(line => line.split(","))
val rdd2 = lines.flatMap(line => line.split(","))
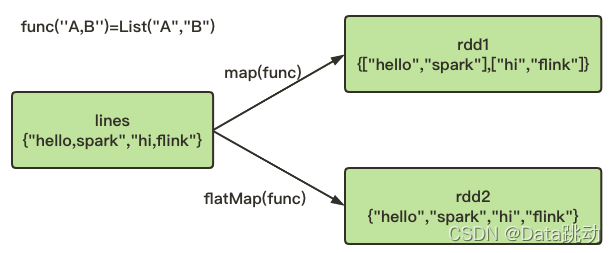
可以看到,把 lines 中的每一个 line,使用所提供的函数执行一遍,map() 输出的 rdd1 中仍然只有两个元素;而 flatMap() 输出的 rdd2 则是将原 RDD 中的数据“拍扁”了,这样就得到了一个由各列表中元素组成的 RDD,而不是一个由列表组成的 RDD。
2. RDD 的转换算子
Spark 中的转换算子主要用于 RDD 之间的转化和数据处理,常见的转换算子具体如下:
| 转换算子 | 含义 |
|---|---|
| map(func) | 返回每一个元素经过 func 方法处理后生成的新元素所组成的数据集合 |
| filter(func) | 返回一个通过 func 方法计算返回 true 的元素所组成的数据集合 |
| flatMap(func) | 与 map 操作类似,但是每一个输入项都能被映射为 0 个或者多个输出项 |
| mapPartitions(func) | 与 map 操作类似,但是 mapPartitions 单独运行在 RDD 的一个分区上 |
| mapPartitionsWithIndex(func) | 与 mapPartitions 操作类似,但是该操作提供一个整数值代表分区的下表 |
| union(otherDataset) | 对两个数据集执行合并操作 |
| intersection(otherDataset) | 对两个数据集执行求交集运算 |
| distinct([numTasks]) | 对数据集执行去重操作 |
| groupByKey([numTasks]) | 返回一个根据 Key 分组的数据集 |
| reduceByKey(func,[numTasks]) | 返回一个在不同 Key 上进行了聚合 Value 的新的 <Key, Value> 数据集,聚合方式由 func 方法指定 |
| sortByKey([ascending],[numTasks]) | 返回排序后的键值对 |
| join(otherDataset,[numTasks]) | 按照 Key 将源数据集合与另一数据集合进行 join 操作,<Key, Value1> 和 <Key, Value2> 的 join 结果就是 <Key, <Value1,Value2>> |
| repatition(numPartitions) | 通过修改 Partiton 的个数对 RDD 中的数据重新进行分区平衡 |
3. RDD 的行动算子
Spark 中行动算子主要用于对分布式环境中 RDD 的转化操作结果进行统一地执行处理,比如结果收集、数据保存等,常用的行动算子具体如下:
| 行动算子 | 含义 |
|---|---|
| reduce(func) | 使用一个 func 方法来聚合一个数据集 |
| collect() | 以数组的形式返回在驱动器上的数据集的所有元素 |
| collectByKey() | 按照数据集中的 Key 进行分组,计算各个 Key 对应的个数 |
| foreach(func) | 在数据集的每个元素上都遍历执行 func 方法 |
| first() | 返回数据集行的第一个元素 |
| take(n) | 以数组的形式返回数据集上的前 n 个元素 |
| takeOrdered(n,[ordering]) | 返回 RDD 排序后的前 n 个元素。排序方式要么使用原生的排序方式,要么使用自定义的比较器排序 |
| saveAsTextFile(path) | 将数据集中的元素写成一个或多个文本文件。参数就是文件路径,可以写在本地文件系统、HDFS,或者其他 Hadoop 支持的文件系统 |
| saveAsSequenceFile(path) | 将 RDD 中的元素写成 Hadoop SequenceFile 保存到本地文件系统、HDFS,或者其他 Hadoop 支持的文件系统,并且 RDD 中可用的键值对必须实现 Hadoop 的 Writable 接口 |
| saveAsObjectFile(path) | 使用 Java 序列化方式将 RDD 中的元素进行序列化并存储到文件系统中,可以使用 SparkContext.objectFile() 方法来加载该数据 |
以上是本期分享,如有帮助请 点赞+关注+收藏 支持下哦~
下期继续讲解 RDD 内容。
往期精彩内容回顾:
1 - Spark 概述(入门必看)
2 - Spark 的模块组成
3 - Spark 的运行原理
4 - RDD 概念以及核心结构
5 - Spark RDD 的宽窄依赖关系
6 - 详解 Spark RDD 的转换操作与行动操作
7 - Spark RDD 中常用的操作算子
可扫码关注
大家可以加我微信(备注spark):Abox_0226,一起组队学习 Spark~
















 4340
4340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









