







SDU项目实训记录2.2——分箱并计算WOE&IV
一、概念与机理
- 离散化:把无限空间中有限的个体映射到有限的空间中去,以此提高算法的时空效率。它是把连续的数据进行分组,使其变成离散化的区间的过程
- 分箱:把一段连续的值切分成若干段,每一段的值看成一个分类。分箱是离散化的重要手段之一。
- 离散化的优点:
-
- 离散化特征的增加和减少都很容易,有利于模型的快速迭代
-
- 可以减少过拟合的风险
-
- 增加稀疏数据的概率,减少计算量
-
- 有效避免一些异常数据的干扰,降低数据波动影响,抗噪声能力提高
-
- 分类树、朴素贝叶斯方法等是基于离散数据展开的
-
- 方便特征衍生,因为数据离散化后就可以把特征直接相互做内积提升特征维度
二、流程方法&技术实现
主要方法有等宽法、等频法、卡方分箱、K-Means聚类算法、二值化处理等;
具体见SDU项目实训记录1.4——数据预处理基础(7.1)第五部分“离散化和分箱处理”。
三、在项目中的实际应用
错误1:分箱个数过少
dis_quantile_uniform = KBinsDiscretizer(n_bins=n, encode='ordinal', strategy='quantile')
等频法:(分箱个数n=5) 观察对各特征等频分箱后得到的边界:红色标记的只有2个边界,即全部数据在同一箱中;橙色标记的边界也不足6个。说明在n_bins=5的情况下这些属性分箱失败了。

原因: 观察训练集的特征统计结果可以发现红色标记的如NumberOfTime30-59DaysPastDueNotWorse(逾期30-59天笔数)在75%处(即上四分位点)还是为0,说明至多有25%的数据不为0,根本无法跟0所在箱达到同样频数。
其他标记特征同理。

错误2:分箱不合适
“uniform”:表示等宽分箱;
“quantile”:表示等位分箱,即每个特征中的每个箱内的样本数量都相同;
“kmeans”:表示按聚类分箱,每个箱中的值到最近的一维k均值聚类的簇心得距离都相同。
等宽法/聚类法:在1基础上将代码中的strategy参数改为uniform或kmeans,分别运行,并计算各维度及各箱的woe和iv值。
问题: 以RevolvingUtilizationOfUnsecuredLines(可用额度比值)为例,计算结果中出现inf,如下图所示:

原因: 由表可见,后三箱坏客户数为0,由于woe证据权重需要每箱中同时包含好、坏两个类别,由公式就可以看出若分子或分母中存在0,则woe=log0,即负无穷大。说明该分箱方法不合适。
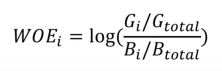
方法:决策树分箱
1、思路
- 利用sklearn决策树,DecisionTreeClassifier的.tree_属性获得决策树的节点划分值;
- 基于上述得到的划分值,利用pandas.cut函数对变量进行分箱;
- 计算各个分箱的WOE、IV值。
2、代码实现
(1)获得最优分箱边界值:
def optimal_binning_boundary(x: pd.Series, y: pd< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1116
1116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











