







题目
提取、定义、规范化:基于 LLM 的知识图谱构建框架

论文地址:https://arxiv.org/abs/2308.00081
摘要
在这项工作中,我们对从输入文本创建知识图谱 (KGC) 的自动化方法感兴趣。大型语言模型 (LLM) 的进展促使最近有一系列研究将它们应用于 KGC,例如通过零样本/少样本提示。尽管这些模型在小型领域特定数据集上取得了成功,但它们在扩展到许多实际应用中常见的文本时仍面临困难。一个主要问题是,在先前的方法中,必须将 KG 模式包含在 LLM 提示中才能生成有效的三元组;更大更复杂的模式很容易超出 LLM 的上下文窗口长度。为了解决这个问题,我们提出了一个名为提取-定义-规范化 (EDC) 的三阶段框架:开放信息提取,然后是模式定义和事后规范化。EDC 的灵活性在于它可以应用于预定义目标模式可用的设置和不可用的设置;在后一种情况下,它会自动构建模式并应用自我规范化。为了进一步提高性能,我们引入了一个经过训练的组件来检索与输入文本相关的模式元素;这以类似于检索增强生成的方式提高了 LLM 的提取性能。我们在三个 KGC 基准上证明,EDC 能够在不进行任何参数调整的情况下提取高质量的三元组,并且与以前的工作相比,其模式明显更大。
简介
知识图谱 (KG) (Ji et al, 2021) 是一种结构化的知识表示,它通过图结构组织相互连接的信息,其中实体和关系表示为节点和边。它们广泛应用于各种下游任务,例如决策 (Guo et al, 2021; Lan et al, 2020)、问答 (Huang et al, 2019; Yasunaga et al, 2021) 和推荐 (Guo et al, 2020; Wang et al, 2019)。然而,知识图谱构建 (KGC) 本身就具有挑战性:这项任务需要能够理解语法和语义,以生成一致、简洁且有意义的知识图谱。因此,KGC 主要依赖于大量的人力劳动 (Ye et al, 2022)。
最近,为了实现 KGC 的自动化 (Zhong et al, 2023; Ye et al, 2022),人们尝试使用大型语言模型 (LLM),因为它们具有出色的自然语言理解能力。基于 LLM 的 KGC 方法采用各种创新的基于提示的技术,例如多轮对话 (Wei et al, 2023) 和代码生成 (Bi et al, 2024),来生成表示知识图谱的实体关系三元组。然而,这些方法目前仅限于小型和特定领域的场景——为了确保生成的三元组的有效性,必须在提示中包含模式信息(例如,可能的实体和关系类型)。复杂数据集(例如维基百科)通常需要超过上下文窗口长度的大型模式,或者可以被 LLM 忽略(Wadhwa 等人,2023 年)。
在本研究中,我们提出了 Extract-DefineCanonicalize (EDC),一种 KGC 的结构化方法:其关键思想是将 KGC 分解为三个主要阶段,分别对应三个子任务(图 1):1.
- 开放信息提取:从输入文本中自由提取实体-关系三元组列表。
- 模式定义:为模式的每个组成部分生成定义,例如由提取阶段获得的三元组诱导的实体类型和关系类型。
- 模式规范化:使用模式定义来标准化三元组,使得语义上等价的实体/关系类型具有相同的名词/关系短语。
每个阶段都利用了 LLM 的优势:提取子任务利用了最近的发现,即 LLM 是有效的开放信息提取器(Li et al, 2023; Han et al, 2023)——它们可以提取语义正确且有意义的三元组。然而,生成的三元组通常包含冗余和模糊信息,例如多个语义上等价的关系短语,如“职业”、“工作”和“职业”(Kamp 等人,2023 年;Putri 等人,2019 年;Vashishth 等人,2018 年)。第 2 和第 3 阶段(定义和规范化)将三元组标准化,使其可用于下游任务。我们将 EDC 设计为灵活的:它可以发现与可能很大的预先存在的模式一致的三元组(目标对齐),也可以自行生成模式(自我规范化)。为了实现这一点,我们使用 LLM 来定义模式组件,利用它们的解释生成功能——LLM 可以通过人类专家同意的解释来证明其提取的合理性(Li 等人,2023 年)。这些定义用于查找最接近的实体/关系类型候选(通过向量相似性搜索),然后 LLM 可以引用这些候选来规范化组件。如果现有模式中没有等效对应项,我们可以选择添加它来丰富模式。
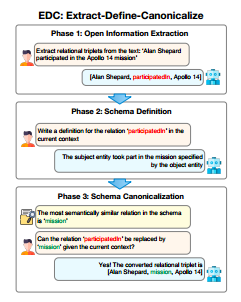
图 1:知识图谱构建的提取-定义-规范化 (EDC) 的高级说明。
为了进一步提高性能,上述三个步骤之后可以进行额外的细化阶段:我们重复 EDC,但在初始提取期间在提示中提供先前提取的三元组和模式的相关部分。我们提出了一种经过训练的模式检索器,它可以检索与输入文本相关的模式组件(类似于检索增强生成(Lewis 等人,2020 年)),我们发现这可以改进生成的三元组。在目标对齐和自规范化设置中对三个 KGC 数据集进行的实验表明,与最先进的方法相比,EDC 能够通过自动和手动评估提取更高质量的 KG。此外,使用 Schema Retriever 可以显著且持续地提高 EDC 的性能。
总之,本文做出了以下贡献:
- EDC 是一个灵活且高性能的基于 LLM 的知识图谱构建框架,能够提取具有大尺寸模式或没有任何预定义模式的高质量 KG。
- Schema Retriever 是一个经过训练的模型,用于提取与输入文本相关的模式组件,与信息检索类似。
- 经验证据表明 EDC 和 Schema Retriever 的有效性。
背景
在本节中,我们提供了知识图谱构建(KGC)、开放信息提取(OIE)和规范化的相关背景。 知识图谱构建。传统方法通常使用“管道”解决 KGC,包括实体发现(ˇZukov-Gregoric et al, 2018; Martins ˇ et al, 2019)、实体类型(Choi et al, 2018; Onoe & Durrett, 2020)和关系分类(Zeng et al, 2014; 2015)等子任务。得益于预训练生成语言模型(例如 T5(Raffel 等人,2020 年)和 BERT(Lewis 等人,2019 年))的进步,最近的研究将 KGC 定义为序列到序列问题,并通过微调这些中等大小的语言模型(Ye 等人,2022 年)以端到端的方式生成关系三元组。大型语言模型 (
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











