







题目
信心v.s .批判:LLM自我修正能力的分解

论文地址:https://arxiv.org/abs/2412.19513
项目地址:https://github.com/Zhe-Young/SelfCorrectDecompose
摘要
大型语言模型(LLM)可以纠正其自生成的响应,但自纠正后的准确性也有所下降。为了对自我纠错有更深入的理解,我们试图对LLM的自我纠错行为进行分解、评估和分析。通过列举和分析自我纠错前后的答案正确性,我们将自我纠错能力分解为自信(有信心纠正答案)和批判(将错误答案转为正确答案)能力,并从概率的角度提出了两个度量这两种能力的指标,以及另一个度量整体自我纠错能力的指标。基于我们的分解和评估指标,我们进行了大量的实验,并得出了一些经验结论。例如,我们发现不同的模型可以表现出不同的行为:一些模型是自信的,而另一些则更挑剔。我们还发现,当通过提示或情境学习操纵模型自我纠正行为时,这两种能力之间存在权衡(即提高一种能力会导致另一种能力下降)。此外,我们发现了一种简单而有效的策略,通过转换监督微调(SFT)数据格式来提高自校正能力,并且我们的策略在这两种能力上都优于香草SFT,并且在自校正后实现了更高的准确度。我们的代码将在GitHub上公开。
介绍
随着训练语料和参数数量的增加(拉德福德等,2018,2019;Brown et al,2020),LLM在各种任务中表现出色,但避免产生错误答案仍然具有挑战性。提高性能的一种方法是内在自校正(Kamoi等人,2024;潘等,2024),这允许模型在没有外部反馈的情况下检查和修改其自生成的答案(Wu等人,2024;Xi等人,2023),这个过程与人类的思维非常相似。Madaan等人(2024);刘等(2024)发现,自我纠正可以导致更好的反应,但代价是增加推理时间(曲等,2024),从而显著提高模型性能。但对自我纠错的否定意见也是存在的(黄等,2024;姜等,2024;Valmeekam等人,2023年),以及Stechly等人(2023年);Tyen等人(2024年);蒋等(2024)发现逻辑推理硕士甚至不能确定答案的正确性,因为他们经常把正确的答案变成错误的,或者不能纠正错误的答案。先前工作中的争论表明对自我纠正缺乏更深入的理解。为了缩小这一差距,我们提出了一种方法来分解、评估、分析和改进LLMs的自校正能力。
自我修正分解。在2中,我们列举了自纠错前后答案的正确性并分析了四种场景,在此基础上我们将自纠错能力分解为:1。信心能力(保持对正确答案的信心)和2。批判能力(将错误答案纠正过来)。自我纠错评价。为了测量这两种能力,在3中,我们从概率的角度引入了置信水平(CL)和批判分数(CS ),它们分别表示在给定初始答案是正确/不正确的情况下,模型在自我纠正后生成正确答案的条件概率。我们还从数学上证明了自校正后的精度本质上可以看作是这两个度量的加权和,这进一步验证了我们分解的合理性。通过分析CL和CS的上下界,我们提出了相对自我修正分数来衡量整体自我修正能力。建议指标的计算依赖于事件概率,因此我们进一步提供分类和生成任务的概率估计方法。
自我修正分析。基于我们提出的度量,在4中,我们对各种模型进行了广泛的实验,并发现:
- 自我修正通常但不一定导致更高的性能;
- 对大多数模型来说,置信能力通常比评论能力更好;
- 不同的模型可以表现出不同的行为;有的车型“保守”(高CL、低CS),有的车型更“自由”(低CL、高CS);
- 来自相同系列的模型倾向于表现相似,这可能是因为它们相似的预训练语料库。
在5中,我们试图通过提示来操纵LLMs的自我纠正行为(李等,2024;黄等,2024)和语境学习(),董等,2024),发现两种能力的同时提高很难在没有微调的情况下实现,而提高一种能力往往导致另一种能力的下降。
自我纠错改进。基于上述发现和分析,在6中,我们提出了信心和批判改进调优(CCT),一种简单而有效的训练策略,以提高LLM的自我纠正能力。与香草SFT不同,香草将问题作为上下文直接教导模型正确答案,CCT利用问题以及初始正确/不正确答案作为上下文,并教导模型最终答案,使模型能够保持正确答案并提炼错误答案。实验结果表明,CCT在自校正后的准确率上大大优于SFT,打破了折衷,实现了更高的CL和CS。
我们的贡献可以总结如下:
- 我们将自我修正能力分解为信心和批判能力,并引入两个度量来衡量它们,以及另一个度量来衡量整体自我修正能力。
- 基于我们提出的度量和概率估计方法,我们对各种LLM进行了广泛的实验,并得出了一些经验结论。
- 我们还发现,通过提示或ICL很难同时提高自信和批判能力,并进一步分析了它们之间的权衡。
- 我们提出了CCT,一种简单而有效的提高自我纠错能力的训练方法,在这两个方面都优于SFT。
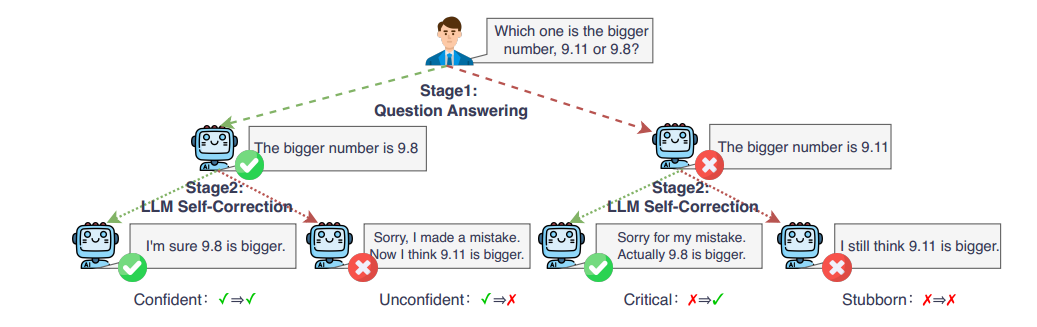
图1:自我纠正的四种情况的例子。对于正确的初始答案,LLM可以(1)。自信地维护它或(2)。不自信的改成错误答案。对于一个错误的初始答案,LLM可以(3)。批判并使之正确或④。固执地坚持错误的答案。
自我纠正分解根据Kamoi et al (2024)中讨论的不同设置,我们研究的自我纠正可以归类为事后内在自我纠正,其中LLM可以在没有外部反馈的情况下审查和细化其生成的响应,然后输出修改后的最终答案。由于在这个过程中没有标准的验证者来确定一个生成答案的正确性,所以模型应该首先自己确定答案是否正确。如果被认为是正确的,模型坚持输出它;如果认为不正确,该模型然后调整并输出修改的答案。我们将自校正前后的过程分为两个阶段:
- 阶段1(问题回答):将一个问题输入到模型中,并生成一个可能正确或不正确的答案。
- 阶段2(自我修正):模型被指示修正其答案,并输出修正的答案,该答案也可以是正确的或不正确的。
与Zhang等人(2024a)类似,通过考虑这两个阶段的结果的笛卡儿积,我们将四种情况进行了分类(如图1所示):
- 自信(!→ !):模型最初生成一个正确答案,并自信地维护这个正确答案。
- 不自信(!→):模型最初产生正确的答案,但对其正确性缺乏信心,随后在自我纠正后产生错误的答案。
- 危急(%→!):该模型最初产生一个错误的答案,但通过有效的反射得到一个正确的答案。
- 固执(%→ %):模型最初产生一个错误的答案,并且固执地坚持这个不正确的答案。
本质上,正确答案中的模型信心(情况1)和缺乏信心(情况2)是反向相关的;同样,错误答案中的反思能力(情况3)和固执性(情况4)也是相反等价的。因此,这四个自我纠正案例可以提炼为两个关键能力:自信能力(对正确答案的信心)和批判能力(纠正错误答案的能力)。
评估指标
为了进一步研究2中的两个分解能力,我们首先将问题形式化并引入相关的数学符号(3.1)。然后,我们从概率的角度提出了两个度量来衡量这两种能力,并证明了自校正后的模型性能(即准确性)本质上是这两个度量的加权和(3.2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











