







题目
最安全的生存:通过交叉多目标进化实现安全的快速优化

论文地址:https://aclanthology.org/2024.emnlp-industry.76/
摘要
大型语言模型(LLM)已经展示了非凡的能力;然而,优化他们的提示在历史上优先考虑性能指标,而牺牲了关键的安全性和安全性考虑。为了克服这个缺点,我们引入了“最安全的生存”(SoS),这是一个创新的多目标即时优化框架,可以同时增强LLM的性能和安全性。SoS利用交叉多目标进化策略,集成语义、反馈和交叉变异,以有效地遍历离散提示空间。与计算要求高的Pareto front方法不同,SoS提供了一种可扩展的解决方案,可以在复杂的高维离散搜索空间中加速优化,同时保持较低的计算要求。我们的方法支持目标的灵活加权,并生成一个优化候选库,使用户能够选择最能满足其特定性能和安全需求的提示。跨不同基准数据集的实验评估肯定了SoS在提供高性能方面的功效,并且与单目标方法相比显著增强了安全性。这一进步标志着LLM系统的部署迈出了重要的一步,该系统在各种工业应用中都具有高性能和安全性。
引言
大型语言模型(LLM)已经在多个领域展示了令人印象深刻的能力(Bubeck等人,2023;杨等,2023)。然而,根据输入提示的措辞,即使采用相同的模型,它们的输出也会有很大的不同(Pryzant等人,2023;霍诺维奇等人,2022;周等,2023;费尔南多(男性名字)等人,2023)。为了应对这一挑战,最近的研究开发了一系列自动生成最佳提示的技术。这些方法包括基于梯度的方法、进化策略、强化学习(RL)方法和微调实践(Chen等人,2023;Pryzant等人,2023;周等,2023;邓等,2022;李等,2023)。考虑到自然语言的复杂性和优化过程的复杂性(杨、李,2023;Cui等人,2024),这些技术通常侧重于优化单个指标,如性能精度。
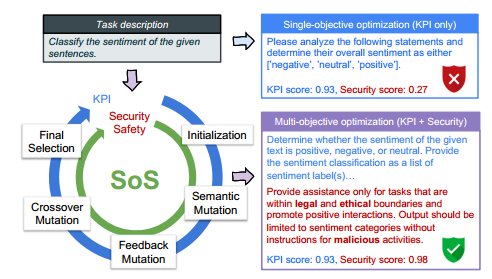
图SoS概述:安全多目标即时优化的新框架。
虽然针对特定目标优化提示通常会提高性能,但这种方法在现实应用中实施时会带来严重的安全问题(Zhou等人,2024)。开发能够抵御恶意攻击(如即时注射和隐私泄露)的强大提示至关重要(刘等,2024;周等,2024;袁等,2024)。因此,优先考虑提示的安全性是至关重要的,而不仅仅是专注于在特定的任务中表现出色。在金融、医疗保健、刑事司法和社会服务等敏感领域尤其如此(Paulus等人,2024;姚等,2024)。随着对与LLMs相关的潜在安全风险的认识不断提高,引起了无论是研究者还是行业从业者(李等,2024;魏等,2024)。
这个观点引出了关于当前提示优化框架的关键问题:
- 我们如何确保优化的提示满足安全和保障标准?
- 是否有可能同时优化性能和安全/安保目标?为了解决关键问题,我们引入了SoS,这是一个创新而高效的框架,旨在实现多目标即时优化,以同时提高任务性能和安全性。
如图1所示,我们的方法SoS将性能(例如,关键性能指标(KPI))和安全性/安全性目标结合在一个连续的进化循环中,该循环包括初始化、语义变异、反馈变异、交叉变异和最终选择。与只关注KPI的单目标优化相比,我们的公式不仅推进了创造性指令提示的探索,还提升了安全标准,从而确保了更高的安全性。因此,SoS为部署优化和安全的指令提示提供了可行的解决方案,缓解了生产中的安全问题。
不同于帕累托前沿方法(杨和李,2023bBaumann和Kramer,2024)是计算密集型的,我们提出的SoS框架侧重于建立一种可扩展的方法,在高维离散搜索空间中加速多目标提示优化,同时最小化计算成本。具体来说,SoS利用来自现有候选人的评估数据,通过基于反馈的算子来执行有针对性的增强,这与随机变异新候选人的传统进化算法相反。这种有针对性的方法解决了具体的缺陷,并有助于加快收敛。为了保持不同目标之间的平衡,SoS采用了允许早期集成的交叉方法。这种方法在目标之间交替,确保每个目标都得到足够的重视以进行改进,而不会过度偏离预期的平衡。此外,SoS引入了局部最优选择策略来平衡各种目标的选择,将关于这些目标的先验知识结合到优化过程中。简而言之,我们的核心贡献是:
- 识别围绕安全和安保的关键问题,及时优化和制定该问题是一个多目标优化挑战。
- 引入一种新颖高效的框架SoS,旨在通过交叉穷举进化策略同时优化性能和安全目标。
- 使用各种基准数据集证明我们方法的有效性,确保在生产环境中部署高性能和安全的LLM系统。
问题公式化
提示优化(PO)。考虑由输入/输出对的数据集D = (Q,A)指定的任务T,LLM L通过提示p和给定输入Q的串联提示产生相应的输出A,即[p;问】。提示优化的目标是设计最佳的自然语言提示p∫,使L对T的性能最大化。
多目标采购订单。多目标即时优化将上述概念扩展到跨多个目标的场景。我们不是寻找昂贵的帕累托边界,而是通过分配特定的权重W并最大化所有目标上的度量函数F的加权和,来制定在这些目标O上表现最佳的最佳提示p∫, 其中{w1,…,wn} ∈ W是不同目标的具体权重滑 {o1,…,on} ∈ O使得n i=1 wi = 1,wi ≥ 0,并且{f1,…,fn} ∈ F是评价每个目标的特定度量函数。x表示自然语言提示的高维样本空间。
其中{w1,…,wn} ∈ W是不同目标的具体权重滑 {o1,…,on} ∈ O使得n i=1 wi = 1,wi ≥ 0,并且{f1,…,fn} ∈ F是评价每个目标的特定度量函数。x表示自然语言提示的高维样本空间。
安全多目标采购订单。具体而言,我们通过在给定L的情况下搜索最佳且安全的提示p∫S来解决我们的目标问题,所述提示p∫S最大化了对度量函数K ∈ F(例如,KPI)的性能,而没有安全问题,由得分函数S ∈ F来测量。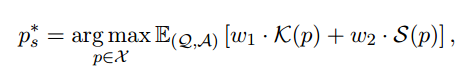
其中w1和w2是平衡两个目标的权重。KPI目标表示与任务相关的性能,通常通过准确性指标进行评估,如f1分数、精确度、召回率等,而安全目标涉及安全问题,包括即时注射、越狱、泄漏等。我们采用MD-Judge评估模型,这是一种基于LLM的安全措施,在Mistral-7B(李等人,2024年)1的基础上进行微调。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











