







 本文介绍了如何在Kubernetes上利用ET-Operator实现弹性深度学习训练。ET-Operator通过TrainingJob和ScaleOut/ScaleIn CRD提供训练任务的创建、扩容和缩容,支持Horovod等分布式框架的弹性训练,提高资源利用率和训练效率。
本文介绍了如何在Kubernetes上利用ET-Operator实现弹性深度学习训练。ET-Operator通过TrainingJob和ScaleOut/ScaleIn CRD提供训练任务的创建、扩容和缩容,支持Horovod等分布式框架的弹性训练,提高资源利用率和训练效率。

背景
由于云计算在资源成本和弹性扩容方面的天然优势,越来越多客户愿意在云上构建 AI 系统,而以容器、Kubernetes 为代表的云原生技术,已经成为释放云价值的最短路径, 在云上基于 Kubernetes 构建 AI 平台已经成为趋势。
当面临较复杂的模型训练或者数据量大时,单机的计算能力往往无法满足算力要求。通过使用阿里的 AiACC 或者社区的 horovod 等分布式训练框架,仅需修改几行代码,就能将一个单机的训练任务扩展为支持分布式的训练任务。在 Kubernetes 上常见的是 kubeflow 社区的 tf-operator 支持 Tensorflow PS 模式,或者 mpi-operator 支持 horovod 的 mpi allreduce 模式。
现状
Kubernetes 和云计算提供敏捷性和伸缩性,我们可以通过 cluster-AutoScaler 等组件为训练任务设置弹性策略,利用 Kubernetes 的弹性能力,按需创建,减少 GPU 设备空转。
但这种伸缩模式面对训练这种离线任务还是略有不足:
- 不支持容错,当部分 Worker 由于设备原因失败,整个任务需要停止重来。
- 训练任务一般时间较长,占用算力大,任务缺少弹性能力。当资源不足时,除非任务终止,无法按需为其他业务腾出资源。
- 训练任务时间较长,不支持 worker 动态配置, 无法安全地使用抢占实例,发挥云上最大性价比
如何给训练任务赋予弹性能力,是提高性价比的关键路径。近期 horovod 等分布式框架逐渐支持了 Elastic Training,即弹性训练能力。也就是允许一个训练任务在执行的过程中动态的扩容或者缩容训练 worker, 从不会引起训练任务的中断。需要在代码中做少量修改适配,可参考:https://horovod.readthedocs.io/en/stable/elastic_include.html。
对 Elastic training 的实现原理感兴趣可以看这篇 Elastic Horovod 设计文档, 本文不详细介绍。
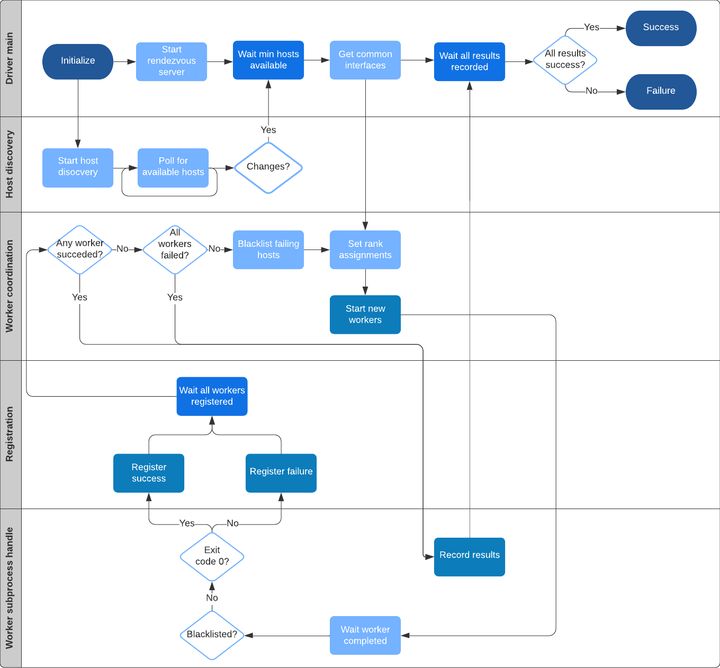
在 mpi-operator 中,参与训练的 Worker 都是作为静态资源设计和维护,支持弹性训练模式后,给任务增加了灵活性,同时也给运维层带来了挑战,例如:
- 必须通过 horovod 提供的 horovordrun 作为入口,horovod 中 launcher 通过 ssh 登陆 worker,需要打通 launcher 和 worker 之间的登陆隧道。
- 负责计算弹性的 Elastic Driver 模块通过指定 discover_host 脚本获取最新 worker 拓扑信息,从而拉起或停止 worker 实例。当 worker 变化时,首先要更新 discover_host 脚本的返回值。
- 在抢占或价格计算等场景中,有时需要指定 worker 缩容,K8s 原生的编排元语 deployment,statefulset 无法满足指定缩容的场景。
解决方法
针对以上问题,我们设计开发了 et-operator,提供 TrainingJob CRD 描述训练任务, ScaleOut 和 ScaleIn CRD 描述扩容和缩容操作, 通过它们的组合,使我们的训练任务更具有弹性。将这个方案开源,欢迎大家提需求、交流、吐槽。
开源方案地
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









