








过去十年,语音AI从实验室走向应用,语音搜索、交互早已融入日常。本文将带你一览达摩院语音AI技术创新全景,一起感受能听、会说、懂你的语音AI。
当你在家中与智能音箱进行交互对话,当你使用天猫超市或菜鸟裹裹,接到机器人打来的配送确认及回访电话,当你利用淘宝高德优酷等App进行语音搜索,当你听到数字人动听的话语及各种悦耳的视频配音……这些背后,都是语音 AI 技术的应用。
AI的很多研究方向,都和人的感知相关。如果说计算机视觉对应的是眼睛,语音AI做的就是耳朵和嘴巴——耳朵是语音识别,把语音转成文字,嘴就是语音合成,把文字转成语音。语音 AI 作为人工智能应用的核心技术之一,在过去十年的时间里持续进步,从实验室研究走向了实际应用和价值创造阶段,并不断解锁新场景,将此前做不了、做不好的技术变得能做,且体验越来越好。
不仅如此,语音 AI 技术已经开始挑战并解决一系列更难的应用课题。正如 Google voice search 解锁了手机上的语音搜索;Apple Siri 解锁了语音助理;Amazon Echo 解锁了远场语音交互……达摩院语音实验室判断,下一个语音技术解锁的场景将会是用更多“人-人”交流替代当前“人-机”交互模式的会议场景。
今天,恰逢图灵诞辰110周年,我们与大家一起来分享下达摩院语音 AI 技术创新全景,包括语音识别声学模型和基础框架、说话人区分、语音合成声学模型和声码器、口语语言处理、联合优化的声学前端等多方面的研究和应用进展。一起感受能听、会说、懂你的语音AI。
能听:技术创新之语音识别基础算法研究
在语音识别的场景下,拾音质量是一个很关键的因素。当年IBM的Via Voice,要带一个耳麦讲话,现在手机可以在稍远距离准确识别,智能音箱又可以做到更大距离。但这些的前提是,周边不会有太多的噪声,而且这些场景都是单人的,都是跟机器去完成一个单独的任务——要么是听写,要么是想点一首歌。但如果加了很多别的因素,准确率就会逐渐下降,说话场所的不同、空间大小的差异、说话人的多寡、情绪语种语速的交杂,各种声音在空间内不断反射产生混响,再加上环境本身带来的噪音,对机器识别来说是极大的挑战。
对我们人类来说,“谁在什么时间说了什么话”非常好识别,因为我们不仅能靠灵敏的耳朵区分不同音色、判断声音方位,还能看到说话人的肢体在动,同时大脑不断用知识储备分析着话语,但对于语音识别而言,如何使机器也具备这些智能呢?
1.1 语音识别基础框架
UNIVERSAL-ASR语音识别基础框架
过去几十年,基于混合框架的语音识别系统一直是学术界和工业界主导框架,其系统包括独立优化的声学模型(Acoustic Model,AM)、语言模型(Language Model,LM)、发音词典(Lexicon)和解码器,系统构建流程复杂。
近几年,端到端语音识别(End-to-End,E2E)成为了学术研究热点。端到端语音识别通过一个网络建模语音识别系统,不仅简化了系统构建复杂度,而且通过联合优化预期可以获得更好的建模效果。阿里巴巴语音实验室结合上一代 DFSMN 网络结构和学术界流行的 Transformer 创新性提出了 SAN-M 网络结构,并且提出了 Streaming Chunk-Aware Multihead Attention(SCAMA)流式 Attention 机制构建了新一代的端到端语音识别框架,显著提升语音识别系统性能。
日益丰富的业务需求,不仅要求识别效果精度高,而且要求能够实时地进行识别。一方面,离线语音识别系统具有较高的识别准确率,但无法实时的返回解码文字结果,并且,在处理长语音时,容易发生解码重复,且高并发解码超时等问题;另一方面,流式系统能够低延时实时进行语音识别,但由于缺少下文信息,流式语音识别系统的准确率不如离线系统,在流式业务场景中,为了更好的折中实时性与准确率,往往采用多个不同时延的模型系统。
为了满足差异化业务场景对计算复杂度、实时性和准确率的要求,常用的做法是维护多种语音识别系统,例如,CTC 系统、E2E 离线系统、SCAMA 流式系统等。在不同的业务场景使用不同的模型和系统,不仅会增加模型生产成本和迭代周期,而且会增加引擎以及服务部署的维护成本。
因此,阿里巴巴语音实验室创新性地提出和设计了离线流式一体化语音识别系统--UNIVERSAL ASR,同时具有高精度和低延时的特点,不仅能够实时输出语音识别结果,还可在说话句尾用高精度的解码结果修正输出,与此同时,UNIVERSAL ASR 采用动态延时训练的方式,替代了之前维护多套延时流式系统的做法。通过设计 UNIVERSAL ASR 语音识别系统,我们将之前多套语音识别系统架构统一为一套系统架构,一个模型满足所有业务场景,显著的降低了模型生产和维护成本。
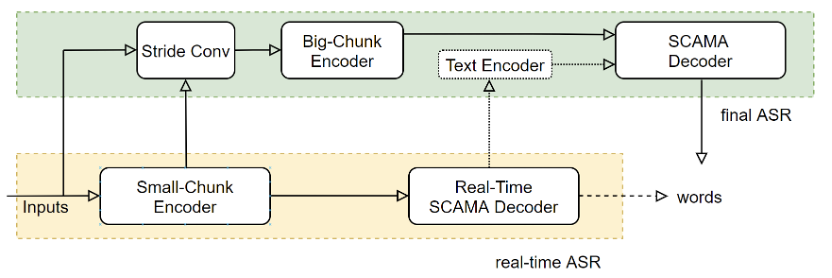
图1 UNIVERSAL-ASR语音识别基础框架
UNIVERSAL ASR 模型结构如上图所示,包含离线语音识别部分和流式语音识别部分。其中,离线与流式部分通过共享一个动态编码器(Encoder)结构来降低计算量。流式语音识别部分是由动态时延 Encoder 与流式解码器(Decoder)构成。动态时延 Encoder 采用时延受限可控记忆单元的自注意力(LC-SAN-M)结构;流式 Decoder 采用动态 SCAMA 结构。离线语音识别部分包含了降采样层(Sride Conv)、Big-Chunk Encoder、文本 Encoder 与 SCAMA Decoder。为了降低刷新输出结果的尾点延时,离线识别部分采用大 Chunk 流式结构。其中,Stride Conv 结构是为了降低计算量。文本 Encoder 增加了离线识别的语义信息。为了让模型能够具有不同延时下进行语音识别的能力,我们创新性地设计了动态时延训练机制,使得模型能够同时满足不同业务场景对延时和准确率的要求。
根据业务场景特征,我们将语音识别需求大致分为3类:
- 低延迟实时听写:如电话客服,IOT语音交互等,该场景对于尾点延迟非常敏感,通常需要用户说完以后立马可以得到识别结果。
- 流式实时听写:如会议实时字幕,语音输入法等,该场景不仅要求能够实时返回语音识别结果,以便实时显示到屏幕上,而且还需要能够在说话句尾用高精度识别结果刷新输出。
- 离线文件转写:如音频转写,视频字幕生成等,该场景不对实时性有要求,要求在高识别准确率情况下,尽可能快的转录文字。
为了同时满足上面3种业务场景需求,我们将模型分成3种解码模式,分别对应为:fast、normal 和 offline 模式,在模型部署阶段,通过发包指定该次语音识别服务的场景模式和延时配置。这样,通过 UNIVERSAL ASR 系统,我们统一了离线流式语音识别系统架构,提高模型识别效果的同时,不仅缩小了模型生产成本和迭代周期,还降低了引擎以及服务部署维护成本。更多技术细节可以参考我们的技术论文:
https://arxiv.org/pdf/2010.14099.pdf
中英自由说
近几年来,端到端语音识别 (End-to-End ASR) 技术在单语种任务上已经取得了比较好的效果,通过UNIVERSAL ASR 统一离线和流式识别系统架构进一步提升了流式场景的识别率,但在多语种混说 (Code-Switch) 场景下效果还不是很理想,比如中英文混说——“借你的ipad给我看下paper”,当突然切换到另一个语种时识别率会发生大幅下降,比如中文 ASR 突然遇到纯英文识别。
拿中英文识别来说,效果不理想的很大原因是中英文混说数据比较稀缺,标注成本也比较高,中/英单语数据的直接混合训练对纯中文和纯英文的识别效果会产生一定的负面影响。如何利用海量的中/英文单语种数据和少量的中英文混说数据提升中英自由说免切换识别效果成为工业界和学术界的研究热点。
针对中英文自由说识别问题,我们借鉴了混合专家系统 (Mixture of Experts) 的思想。在端到端语音识别模型中,对中文和英文分别设计了一个子网络,每个子网络被称为专家,最后通过门控模块对每个专家网络的输出进行加权。同时为了减少模型参数量,中、英文子网络采用底层共享,高层独立的方式。通过这样的方式,使模型在中文、英文、中英文混说场景下都能取得比较好的效果。进一步我们结合达摩院语音实验室自研的 SAN-M 网络,打造了达摩院语音实验室新一代的端到端中英自由说语音识别系统。在不需要语种信息的前提下,用一个模型保证纯中文和纯英文相对于单语模型的识别性能基本不降,并且大幅度提升中英文混说场景下的识别性能。
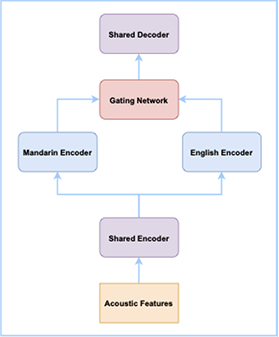
图2 中英自由说系统框架图
方言自由说
通用的中文语音识别系统对普通话的识别准确率已接近人类水平。但当一个中文识别系统遇到重口音或者方言的时候,识别效果会产生灾难性地下降。主要的原因是方言的发音和普通话有差异,会出现同音异字的情况。所以针对每一种方言,我们都会单独训练一个方言模型,这样又会导致我们需要维护多个方言模型,同时无法通过一个模型识别多种方言,且有的方言数据量稀疏,不利用其他方言数据中的共有信息而单独训练这个方言模型的效果不尽人意。
针对这个问题,我们借鉴了中英文自由说模型的方案,对每一种方言设计一个专家网络,同时考虑到每种方言的发音相似性,我们增加了一个共享的专家网络来学习方言之间的共性。和中英文自由说模型类似,最后通过一个门控模块对每个专家网络的输出进行加权。
考虑到方言种类比较多,每个专家网络通过简单的两层线性层来建模。进一步我们结合达摩院语音实验室自研的 SAN-M 网络,打造了达摩院语音实验室新一代的端到端方言自由说语音识别系统。在不需要提供方言id的情况下,用一个模型识别十四种常用方言,并且保证纯中文相对于单语模型的识别性能基本不降。
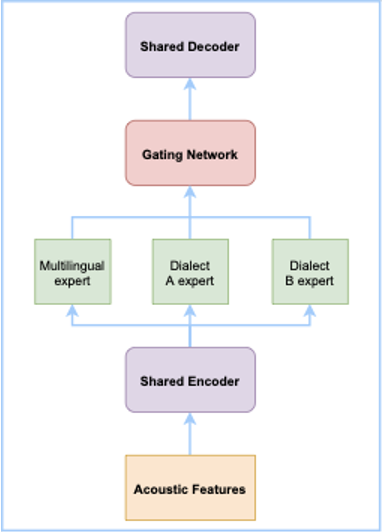
图3 方言自由说系统框架图
1.2 鸡尾酒会问题
“鸡尾酒会问题”(cocktail party problem)是语音识别领域困扰人已久的学术难题。鸡尾酒会问题是指在多人自由交谈的场景,需要高精度识别出每个说话人所讲的内容。当前通用的语音识别系统可以高精度的识别单个说话人的语音,但是当场景中同时存在多个说话人自由交谈时候,语音识别系统识别性能就会出现明显的下降。
会议场景是一个典型的多人自由交谈的场景。探索鸡尾酒会问题的工业级解决方案,对于解锁会议场景的语音AI具有重要作用。针对鸡尾酒会问题,语音团队从语音识别基础框架(上文已阐述),M2MeT 国际挑战赛,混叠语音检测技术和说话人日志技术等方面展开了技术
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









