







一、实验目的
1.学习和掌握将NFA转为DFA的子集构造法。
2.学会编程实现等价划分法最小化DFA。
二、实验任务
1.存储NFA与DFA;
2.编程实现子集构造法将NFA转换成DFA。
3.先完善DFA,再最小化DFA。
三、实验内容
1.NFA确定化
1.1.确定NFA与DFA的存储格式。
要求为3个以上测试NFA准备好相应有限自动机的存储文件。
1.2.用C或JAVA语言编写将NFA转换成DFA的子集构造法的程序。
1.3.测试验证程序的正确性。
可求出NFA与DFA的语言集合的某个子集(如长度小于某个N),再证实两个语言集合完全相同!
测试用例参考:将下列语言用RE表示,再转换成NFA使用:
(a) 以a开头和结尾的小字字母串;a (a|b|…|z)a | a
(b) 不包含三个连续的b的,由字母a与b组成的字符串;(e | b | bb) (a | ab | abb)
© (aa|b)(a|bb)
2.DFA最小化
2.1.准备3个以上测试DFA文件。(其中一定要有没有最小化的DFA)
2.2.用C或C++语言编写用等价划分法最小化DFA的程序。
2.3.经测试无误。测试不易。可求出两个DFA的语言集合的某个子集,再证实两个语言集合完全相同!
四、实验准备
1.NFA、DFA的存储格式
1.1.NFA的存储格式

因为NFA的状态转移并不固定,也就是每一个状态对每一个输入符号可能有不同的下一状态,因此这里对每一个符号的下一状态使用stl中的set集存储,好处是不会有重复状态,并且加入删除等操作较为简单。
另外使用示性函数来进行集合状态内部表示:
①含有单个状态的状态集合用2的幂次表示。即状态1 ~ N分别用数21 ~ 2N 表示。
这里的i即为nfa状态下标的2的幂次;
②数的存储:若用32位整型(__int32)、64位整型(__int64)存储,可分别表示32个或64个状态。更多的状态表示需要使用整型数组。
③含有多个状态的状态集合也用数来表示。若两个状态集合A与B用数表示为m和n,则状态集合AB与AB的数可用“位运算”表示,分别为m|n和m&n。
④若想知道某个状态集合A(用数m表示)中是否包含原先的第i个状态,也可使用基于“位运算”来判断:若(m | 2i )> 0,则包含,否则不包含。
1.2.DFA存储格式

正如上面所述,使用32位int Q来存储NFA集合,关于集合的判断和运算如上述③④所示;
因为DFA是确定性的,对任意输入字符下一状态唯一,那么只需要用整数数组nextq存储下一状态即可;
此外,我们还需要知道DFA的状态是接收状态或是非接收状态,在这里直接用isjs进行标志,isjs为1则表示是接收状态,为0则是非接收状态,isjs的计算过程位于NFA确定的过程,当集合包含NFA结束状态时,将isjs置1。
1.3.最小化DFA的存储格式

因为最小化后的DFA依然是DFA,所以格式与上述DFA格式相似,但是为了方便最小化过程并且这里存储的集合是DFA状态而非NFA状态,因此这里对状态集的存储使用的依然是set,确保集合中无重复的元素;
2.测试样例的选择
直接使用三个测试样例:
(a) 以a开头和结尾的小字母串;a (a|b|…|z)*a | a
NFA:
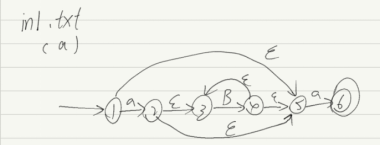
(b) 不包含三个连续的b的,由字母a与b组成的字符串;(e | b | bb) (a | ab | abb)*
NFA:
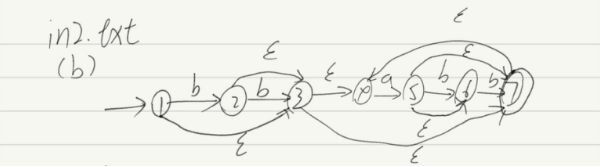
DFA:

最小化DFA:
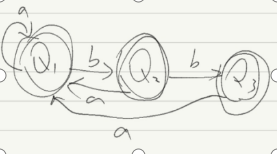
(C) (aa|b)(a|bb)
NFA:
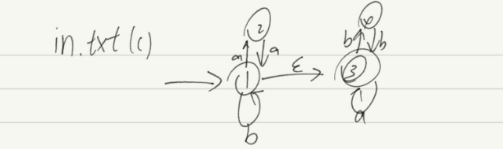
3.文件存储格式(以第三个样例为例)
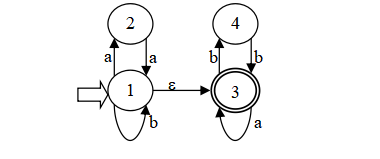
3.1.NFA的存储格式

3.2.DFA的存储格式

因为我将NFA确定化、最小化DFA分成了两个程序来写,因此这里需要对最小化DFA程序有一个输入文件nfatodfa.txt,文件名称表示该文件是通过NFA确定化程序经过将NFA转化为DFA后输出的文件。
对DFA的最小化需要知道DFA是否为接受状态,因此用*号、!号分别表示接收状态与非接受状态。
3.3.最小化DFA后的输出文件

因为最小化DFA后的输出不需要作为任何程序的输入,因此直接将状态转移、状态数、开始状态打印出来。
五、实验设计
正如我所提到的,我将NFA的确定化、DFA的最小化分为了两个程序,下面对这两个程序的设计进行分析;
1.NFA确定化程序
1.1.init( )——NFA的初始化(从in.txt文件中读取数据)
init( )函数完全NFA存储文件的格式进行读入状态数、符号数、符号、转移状态;
根据NFA文件存储格式将文件中的NFA读取到程序中,并构造好整个NFA转换图;
这里值得注意的是下一状态可能为多个(用逗号分开),因此读取这一部分的程序略微复杂,我专门写了srfx函数来进行处理:

我通过读取string的方式将下一状态字符串读入,通过srfx函数对其进行读取;
算法步骤:
①如果字符串长度为1且字符为‘0’,那么说明无下一状态,直接返回即可。
②否则使用一个整数n存储读入的数,当遇到‘,’时说明一个数读取结束,将n插入对应的下一状态set集,再将n清零;
③若遇到的是数字,那么将n*10后加上该数字即可。
1.2. count_closure(T) – 状态T的闭包的计算
因为后面会NFA转为DFA的过程会多次用到各个状态的闭包(即从该状态出发经过空符所能到达的状态集和),因此我直接在主函数中调用该函数将所有状态的闭包计算并保存在整数数组中,因为这里使用的位的方式表示状态,因此一个整数int(32位)最多可以表示32个状态的集合。

【算法步骤】
计算方法较为简单,使用队列的方式实现;
①以要计算闭包的状态为第一个状态,将该状态加入到闭包集合中并入队;
②若队列为空,则计算结束,否则继续计算过程;
③读取队首元素(表示状态)出来,对该状态经过空符所能到达的状态进行遍历,如果该状态已经位于闭包集合中则不做处理,否则加入到闭包集合并入队;
④循环②③步骤;
【伪代码】
count_closure(int T){
将T状态写入队列中
将closure(T)初始化为T,即需要包含自身状态
while(队列不为空){
将队首状态t弹出
for(每个满足如下条件的u:从t出发有一个标号为空的转换到达u){
if(u不在closure(T)中){
将u加入closure(T)中;
将u插入队列中;
}
}
}
1.3.todfa( ds )—— NFA转为DFA最主要的函数
该部分严格按照子集构造算法来进行构造;
【算法思想】
为DFA构造一个状态转换表Dtran。DFA的每个状态是一个NFA的状态集合。在构造Dtran的过程中,使得DFA模拟NFA在遇到一个给定输入串时可能执行的所有动作。
①以NFA开始状态的闭包(状态的集合)作为DFA的开始状态。
②如果DFA的状态集中存在一个状态T,T还没有模拟NFA构造过Dtran,那么对于该状态T,依次检查输入符号表。T在输入符号a下,所包含的所有NFA的状态可以到达的状态集合构成DFA状态U。
③检查U是否为DFA的某一个状态。如果不是,那么就将该状态U加入到DFA的状态集合中。如果是,直接进入下一步。
④构造DFA的状态转换表Dtran,即对于当前状态T,经过输入符号为a的转换后可以到达状态U。
⑤回到②步骤,直到DFA中所有状态都在任意一个输入符号下找到了目标状态,说明DFA的状态转换表Dtran构造完成。与此同时,DFA的集合也构造完成。
【伪代码】
void todfa(T){
给T加标记,说明T要作为出发状态去查找输入符号的跳转状态
对于状态集合T,在输入符号为x下,跳转到的状态集合U
for(对于任意一个输入符号a){
U = closure_T(move(T,a));
if(U不在Dstate状态集合中){
if(U包含NFA中的接受状态){
将U设置为接受状态
}
将U加入DFA的状态集合,DFA状态数目加1
}
对当前状态T和输入符号a构造状态转换到达状态U
}
}
注意:todfa()函数即为步骤②③④的过程,循环控制位于主函数中,即 :
当todfa中生成一个新的DFA状态时,numq状态数会增大,因此可以遍历到所有的DFA的转移。
1.4.jcdfa( ) ——检查程序得到的DFA是否正确
【算法思想】
验证两种自动机描述的语言是十分困难的。所以采用打印一定的长度范围内的语言集列表并进行对比。如果输出的语言集是相同的,那么说明NFA到DFA是正确的,反之则是错误的。
采用深度优先算法,使用递归方法,以深度d作为需要输出的字符串的下标。每次递归依次尝试字符集中所有字符,如果当前状态在当前输入符号下到达的状态不为0,那么说明没有错误,将当前符号添加到字符串集合中,可以进行第d+1层的递归。如果当前状态为接受状态,那么说明目前字符串[0:dep]符合DFA规则,打印字符即可。结束条件为递归深度大于N时,说明递归完成,直接返回。
【伪代码】
void jcdfa(int curIndex,int dep,int limit){
if(dep>=limit)return;//遍历结束
检查当前状态是否为接受状态,如果是,则输出sen[0:dep]
for(遍历字符集合){
int nxtIndex = 当前状态下当前输入符号下可以到达的状态;
if(下一状态不为0){
将当前字符串中第dep个字符设为当前输入符号
jcdfa(nxtIndex,dep+1,limit);//进行深度遍历
}
}
}
1.5.pathnfa( )——通过NFA打印出一定长度的字符串
与上面通过DFA来进行字符串的打印类似;
采用深度优先算法,使用递归方法,以深度d作为需要输出的字符串的下标。每次递归依次尝试字符集中所有字符,如果当前状态在当前输入符号下到达的状态不为0,那么说明没有错误,将当前符号添加到字符串集合中,可以进行第d+1层的递归。此外还需要考虑空符可到达的状态,即转移到该状态但是深度d不变,因为没有加入字符到字符串中。
如果当前状态为终止状态,那么说明目前字符串[0:dep]符合DFA规则,打印字符即可。注意:
对于最终的这一层d,已经读入了dep个字符但是却没有到达终止状态,此时需要进行空符的转移,即判断它的空符闭包是否包含终止状态,如果包含则可以打印;
即:

通过最后一个状态的闭包是否包含终止状态进行打印;
1.6.print( )——将DFA打印到nfatodfa.txt文件中以便DFA最小化程序使用
根据最小化DFA程序所需要的输入格式,将NFA转为DFA的结果输出到文件nfatodfa.txt中,并且在屏幕上打印出DFA的Dtran转移图,以及每一个状态包含的NFA状态集合。
2.DFA最小化
DFA的最小化通过mindfa.cpp实现对其进行分析:
2.1.init( )函数——将NFA转DFA的输出文件nfatodfa.txt作为输入进行DFA的读入
在NFA确定化DFA程序中,将生成的DFA通过print函数写入到了nfatodfa.txt文件中,在DFA最小化程序中作为输入文件;
init函数根据文件中的DFA存储格式将数据读取出来;这里的文件读取比NFA确定化的读取更加简单,因为DFA的下一状态是确定的并且没有空符号,因此这里不需要srfx函数来辅助读取;
同时在读入的过程中根据 “*、!”来判断是否为DFA的接收状态,如果是则同时加入到接收状态集,不是则加入非接收状态集,也就是在init过程中就完成等价划分算法初始的两个集合的确定,即:

此外,接收状态集和非接收状态集可能为空,为空的话对后面的集合处理过程来说是没有意义的,因此需要进行处理:
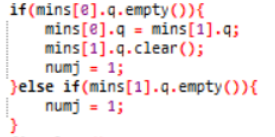
将空的集合删掉,留下一个下标为0的集合,并将初始的集合数置为1;
2.2.mindfa( )函数——DFA确定化的关键函数
【算法思想】
将一个DFA的状态集合划分成多个组,每个组中的各个状态之间互相不可区分。然后将每个组中的状态合并成minDFA的一个状态。算法在执行过程中维护了状态集合的一个划分,划分中每个组内各个状态尚不能区分,但是来自任意两个集合的不同状态是可以区分的。当任意一个组都不能被分解为更小的组的时候,这个划分就不能再一步精化,这样就可以得到minDFA。
【算法步骤】
①将DFA的所有状态划分为两个集合:不包含接受状态的集合T1,包含接受状态的集合T2;以这两个为基础,进行集合划分。
②对于现有状态集合中任意一个状态集合T,对于一个输入符号a。新建状态集合数组U,数组对应长度为当前DFA状态个数。设立flag标识,为0表示不需要再划分。
③记录T中第一个状态经过a到达的状态x。依次检查T中第二个、第三个状态…;如果第i个状态经过a到的状态不为x而为y,那么表示当前划分集合仍需要划分,将flag设置为1,同时将第i个状态从状态集合T中删除。同时将状态i加入一个y对应的U数组中的集合。如果第j个状态进过a到达的状态也为y,就将状态j也加入到y对应的U数组中的集合。
④将新产生的划分U加入到原来的划分T中;
⑤回到第二步执行,直到flag为0,说明不需要再进行划分,mindfa状态集合构造完毕。
【伪代码】
void mindfa(){
初始化分为接受状态组和非接受状态组
对于当前每一组进行划分
while(flag){
flag = 0;
newset记录组别对应产生的新组
for(对于当前分组中的所有状态){
for(对于每一个输入符号){
if(i为组内第一个状态){
记录i经过符号j到达状态组T
}
else if(如果i经过符号j到达的状态组为Q){
flag=1;
将i从状态组T中删除,将i加入到Q对应的newset中
}
}
}
将newset中不为空的组并入旧组
当前minDFA状态数目等于原本状态数目+新状态数目
}
划分结束,构造状态转换表
}
【实现细节】
算法步骤描述较为简单,但是实现过程需要注意一些细节,如下:
对于一个状态集和,它对某一符号a的划分标准第一个状态的下一状态集和剩余状态的下一状态集比较,不同则划分,但是这里需要考虑的是第一个状态对于符号a的下一状态可能不存在,也就是说下一状态集不存在,那么后面的状态要怎么判断划分呢?
我的处理是:

对第一个状态的转移做判断,如果是无下一状态则做一个标记;后面处理剩余状态的时候根据此标志进行处理;
如果标记为真,且状态s也无下一状态,那么不需要进行划分;如果标记为真但状态s有下一状态,那么说明需要进行划分;如果标志为假,那么直接进行下一状态集是否相同的判断就可以;
另外因为我使用的是set来存储DFA状态集合,所以遍历set的方式是使用iterator指针,那么这里对将i从状态组T中删除的操作无法直接在便利的过程中完成,我是在遍历结束后根据新的newset中的状态将原来的状态集中对应的状态删除,即:

遍历原来的所有集合,如果集合中出现了newset中的状态,那么需要删除。
2.3.jcmin( )——检查最小化后的DFA的正确性
与检查上面NFA确定化后的DFA的方式相同,采用深度优先搜索算法进行搜索,。每次递归依次尝试字符集中所有字符,如果当前状态在当前输入符号下到达的状态不为-1,那么说明没有错误,将当前符号添加到字符串集合中,可以进行第d+1层的递归。如果当前状态为接受状态,那么说明目前字符串[0:dep]符合DFA规则,打印字符即可。结束条件为递归深度大于N时,说明递归完成,直接返回。
2.4.print( )——打印出最小化后的DFA
打印格式如图:

同时将最小化DFA输出到mindfa.txt文件中,便于查看;
3.文件结构
文件较多,所以这里列份清单:

六、实验测试
1.样例1((aa|b)(a|bb))

1.1.NFA确定化测试
运行结果如下:

根据结果画出DFA图:
DFA:
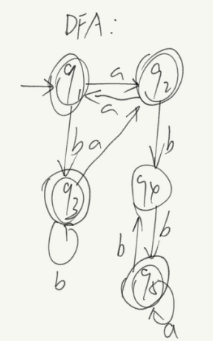
1.2.DFA最小化测试
测试结果:

画出最小化DFA:
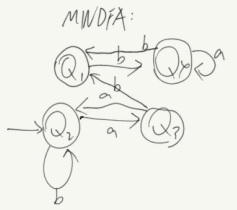
1.3.打印长度为3的字符串对比三个状态机描述语言相同:

NFA中包含空符,因此简单的深度优先搜索会出现重复字符串,但总的来说三者相同。
2.样例2(以a开头和结尾的小字母串;a (a|b|…|z)*a | a)
NFA:
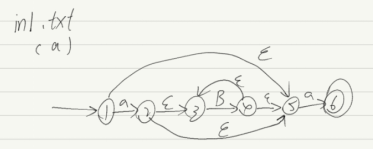
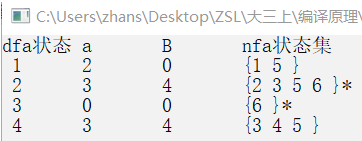
2.1.NFA确定化测试
程序结果:
画出DFA:
![[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(imblogWdi7Psnimg.cn/20210516840905(t97.pngts://img-log.csdnimg.cn/20210516223849597.png)]](https://img-blog.csdnimg.cn/20210516223857223.png)
2.2.DFA最小化测试
程序结果:
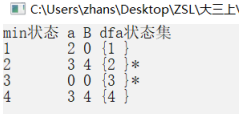
画出最小化DFA:
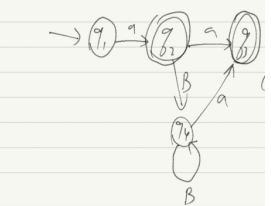
最小化DFA与DFA相同,即NFA确定化后的DFA就是最小的。
2.3.打印长度为3的字符串对比三个状态机描述语言相同:

3.样例3(不包含三个连续的b的,由字母a与b组成的字符串;(e | b | bb) (a | ab | abb)*)
NFA:
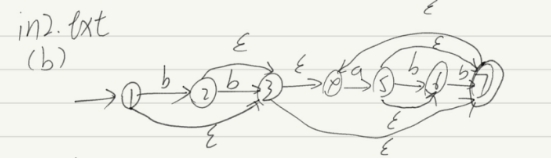
3.1.NFA确定化测试
程序结果:
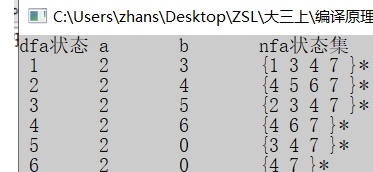
画出DFA:
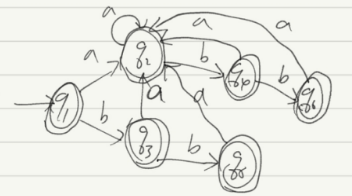
3.2.DFA最小化测试
程序结果:
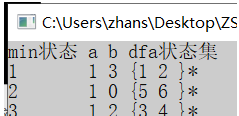
画出最小化DFA:
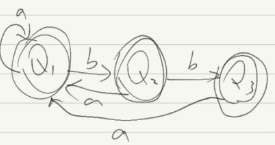
3.3.打印长度为3的字符串对比三个状态机描述语言相同:

NFA中包含多个重复串,但结果相同;
七、总结
此次实验通过用代码实现NFA转化为DFA和DFA最小化,让我去思考如何实现教材上提供到的子集构造算法和最小化DFA算法,了解其实现的过程。
前前后后一共花了三四天的时间把整个代码从零敲出来,这一过程非常的艰辛,遇到了很多的问题,也一一解决了它们。在写NFA确定化的过程中遇到了无法根据NFA状态图输出定长字符串的问题,查了很久的bug才发现在递归里复用了全局的iterator指针,这样在递归返回时原来的iterator指向已经变了,所以会陷入死循环。所以只要在循环中重新定义局部的iterator即可。另外就是DFA最小化的过程中因为初始的接收状态集与非接收状态集可能有一个为空,因此需要进行一个判断,否则在最小化DFA后会多出一个包含0个DFA状态的集合。
这次实验结束后感觉收获良多,相对于第一个实验,这次实验更加倾向于实现代码,也更有可能出错。
代码链接:
https://download.csdn.net/download/weixin_43973089/18785386
仅供参考















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









