






官方文档:

columns配置:
const columns = [
{
title: 'Path',
dataIndex: 'path',
align: 'center',
render: (text: string, record: TransAnalysisCaseItem) => ({
children: text,
props: { rowSpan: record.spanObj.path }, // 关键点
}),
},
{
title: 'Identity',
dataIndex: 'identity',
align: 'center',
render: (text: string, record: TransAnalysisCaseItem) => ({
children: text,
props: { rowSpan: record.spanObj.identity },
}),
},
{
title: 'Entrance',
dataIndex: 'entrance',
align: 'center',
render: (text: string, record: TransAnalysisCaseItem) => ({
children: text,
props: { rowSpan: record.spanObj.entrance },
}),
},
];
如果后端传给我们的数据格式长这样子:
[
{
analysis_task_id: 1,
entrance_identity_list: ['entrance1', 'entrance2'], // 这里
identity: 'identity', // 这里
path_list: ['path'], // 这里
task_history_id: 1,
total_failed_no: 1,
},
];
entrance_identity_list 和 path_list 字段是一个字符串数组(两者对应关系为:1:n 或者 n:1,identity为单个的字符串,需要对这三个字段进行排列组合,将数据扁平化处理成如下格式:
[
{
analysis_task_id: 1,
entrance: 'entrance1',
identity: 'identity',
path: 'path1',
task_history_id: 1,
total_failed_no: 1,
spanObj: { // 记录rowSpan的值
path: 2,
identity: 2,
entrance: 1,
},
},
{
analysis_task_id: 1,
entrance: 'entrance2',
identity: 'identity',
path: 'path1',
task_history_id: 1,
total_failed_no: 1,
spanObj: { // 记录rowSpan的值
path:0,
identity: 0,
entrance: 1,
},
},
];
同理,
// 处理前
[
{
analysis_task_id: 1,
entrance_identity_list: ['entrance1'],
identity: 'identity',
path_list: ['path1','path2'],
task_history_id: 1,
total_failed_no: 1,
},
];
// 处理后
[
{
analysis_task_id: 1,
entrance: 'entrance1',
identity: 'identity',
path: 'path1',
task_history_id: 1,
total_failed_no: 1,
spanObj: {
path: 1,
identity: 2,
entrance: 2,
},
},
{
analysis_task_id: 1,
entrance: 'entrance1',
identity: 'identity',
path: 'path2',
task_history_id: 1,
total_failed_no: 1,
spanObj: {
path:1,
identity: 0,
entrance: 0,
},
},
];
转换函数:
function transformData(data) {
const transData = [];
// 对 data 扁平化处理,并计算单元格的 rowSpan 值
data?.forEach((analysisItem) => {
analysisItem?.path_list?.forEach((pathItem, pathIndex) => {
analysisItem?.entrance_identity_list?.forEach((entraceItem, entranceIndex) => {
const pathLen = analysisItem?.path_list?.length;
const entranceLen = analysisItem?.entrance_identity_list?.length;
let pathSpan = 1; // 默认值
let entranceSpan = 1; // 默认值
let identitySpan = 1; // 默认值
if (pathLen === 1) {
// path:entrance 1:n
pathSpan = entranceIndex === 0 ? analysisItem?.entrance_identity_list?.length : 0;
identitySpan = pathSpan; // identitySpan 始终跟较少的一边保持一致
}
if (entranceLen === 1) {
// path:entrance n:1
entranceSpan = pathIndex === 0 ? analysisItem?.path_list?.length : 0;
identitySpan = entranceSpan; // identitySpan 始终跟较少的一边保持一致
}
transData.push({
analysis_task_id: analysisItem.analysis_task_id,
entrance: entraceItem,
task_history_id: analysisItem.task_history_id,
total_failed_no: analysisItem.total_failed_no,
path: pathItem,
identity: analysisItem.identity,
spanObj: { // 记录rowSpan的值
path: pathSpan,
identity: identitySpan,
entrance: entranceSpan,
},
});
});
});
});
return transData;
}
console.log(
transformData([
{
analysis_task_id: 1,
entrance_identity_list: ['entrance1'],
identity: 'identity',
path_list: ['path1', 'path2'],
task_history_id: 1,
total_failed_no: 1,
},
]),
);
转换结果:
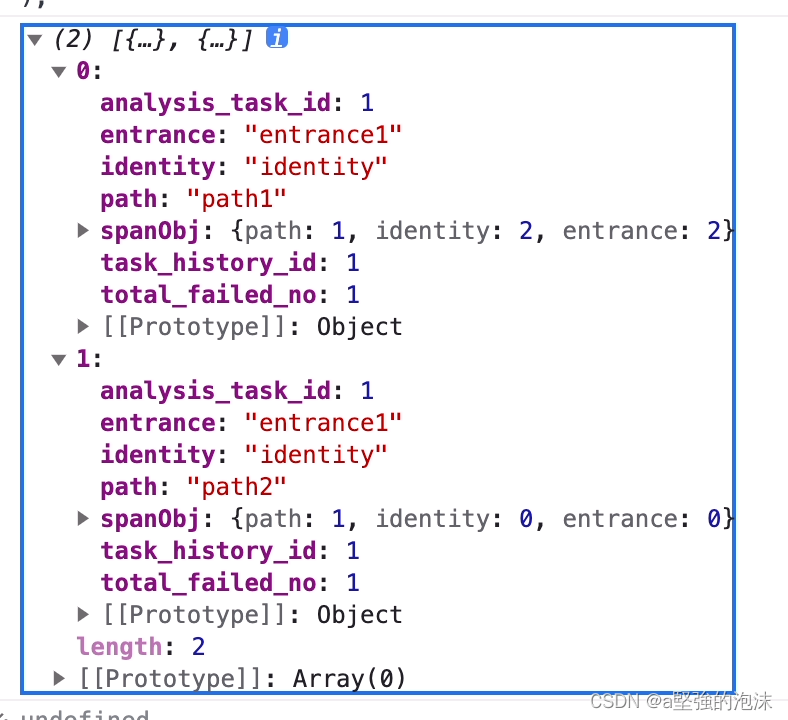
效果图:

总结:
- columns配置:使用render里的单元格属性rowSpan(此处跟antd官方给出的事例有点不太一样)。
- data数据:如果后端的数据是直接聚类后的,其实不太实用,还需要前端转换一下,转换成单行的数据,并计算每一行数据的rowSpan值。















 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









