







思路及创新点
提出了一种用于 UDA person re-ID 的三重对抗学习和多视角想象推理网络(TAL-MIRN),它由一个多视角想象推理模块(IRM)和一个三重对抗学习模块(TALM)组成。TALM由三个子模块DIFE、JDAID和FDRI组成。DIFE 在相机级别提取域不变特征, JDAID实现身份和域的联合分布对齐,FDRI保证模糊外观特征的可辨别性和鲁棒性。也提出了一种称为交叉归一化(CN)的简单归一化。
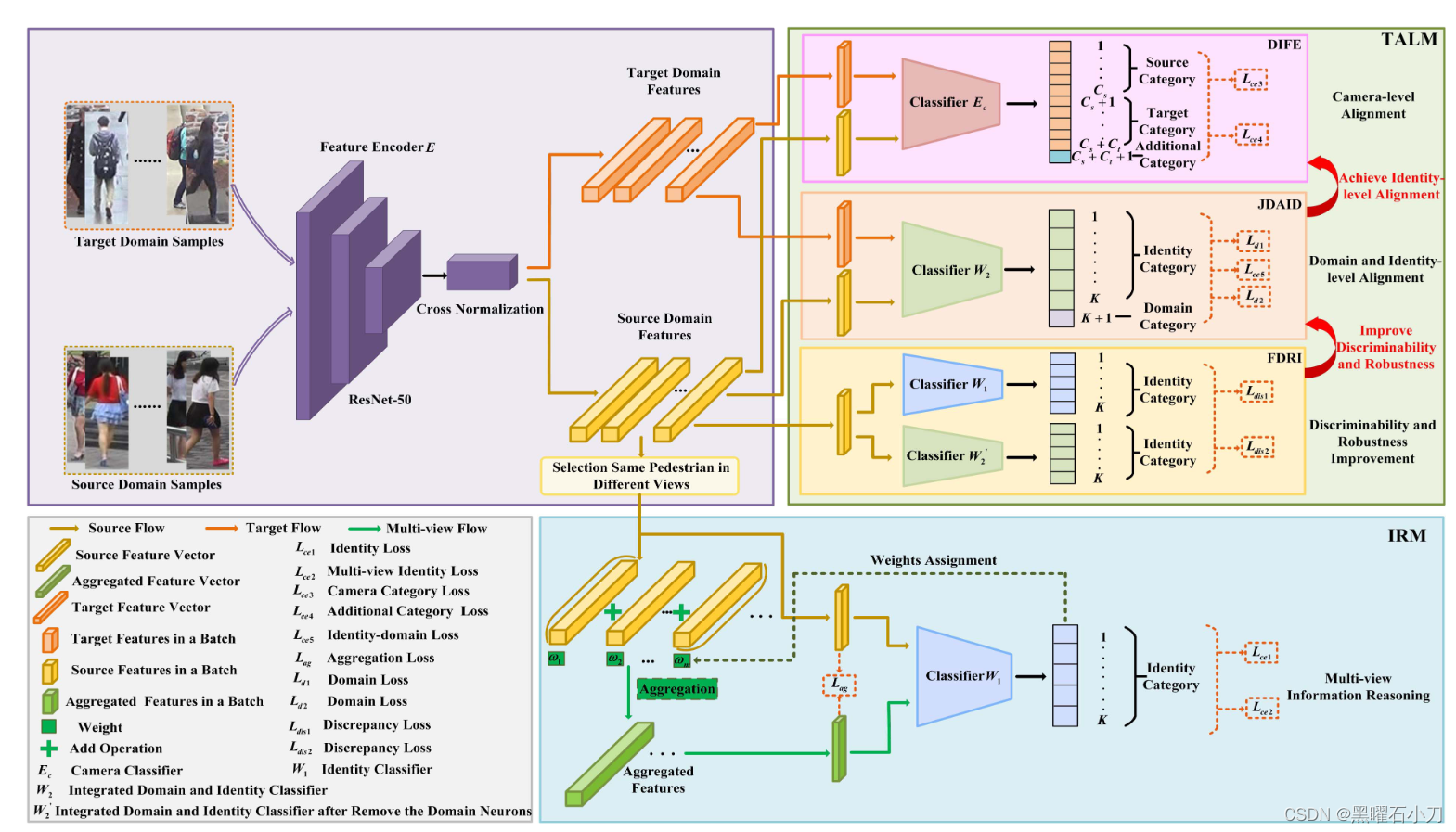
IRM
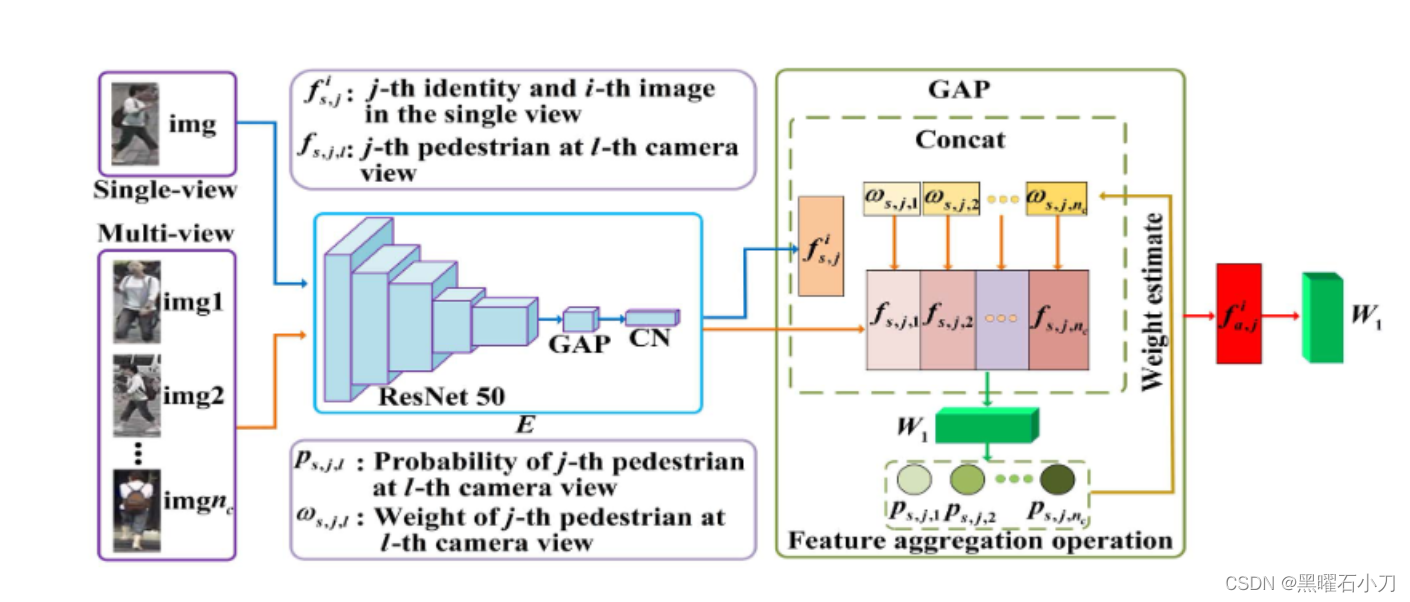
原理:行人外貌的全面描述有利于提高识别性能。从单视图行人图像中推断出聚合的多视图特征。
使用标记的源样本进行训练,这可以从单视图行人图像中想象性地推断聚合特征。
同一行人在不同视角下的特征具有不同的辨别能力。对于同一行人在不同摄像机视图下,共享信息越少,身份相关信息可能存在较大差异。在特征聚合中,对同一行人在不同摄像机视图下差异较大的特征赋予较高的权重,有利于提高IRM的性能。 根据每张图像的可辨别性自适应地为其分配相应的权重。
运行过程: 具有身份标签 j 的第 i 个图像特征 f i,s,j只包含当前视图中显示的行人信息。将第 j 个行人在第 l 个摄像机视图的任意图像的特征 f s,j,l 发送到身份分类器,然后得到属于该行人的概率 ps,j,l。具有高置信概率 p s, j,l 的特征 f s, j,l 往往意味着它具有很强的辨别能力,携带的互补信息较少,所以为它分配较小的权重。根据学习到的权重 ωs, j,l ,得到多视角行人图像的平均加权特征,然后与一个单视角图像特征 f i s, j 连接。再进行GAP得到f i,a,j。
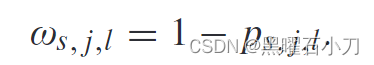
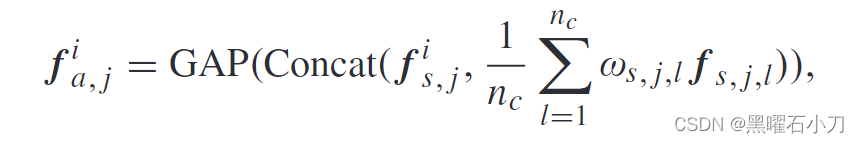
训练模型E和分类器W1用的损失函数为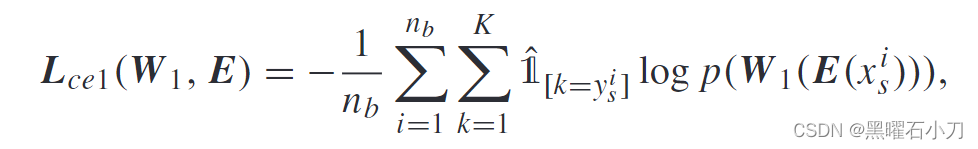
同时,为消除过拟合,指示函数定义为:
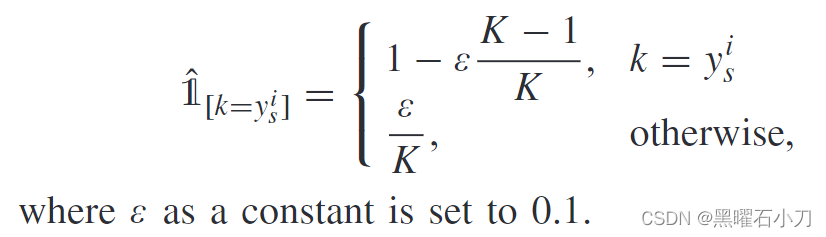
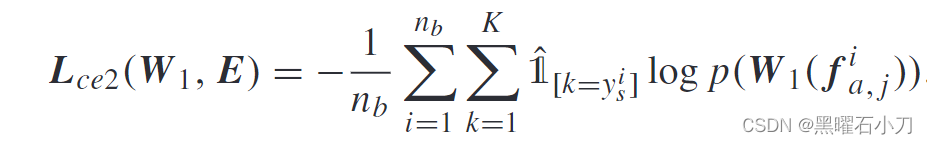
为了进一步促进多视图图像特征的提取,模型通过最小化以下聚合(l2)损失来优化。
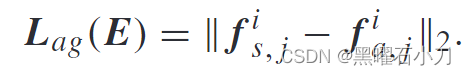
Triple Adversarial Learning Strategy
DIFE 和 JDAID 子模块学习域不变特征,FDRI 子模块提高了学习特征的可辨别性和鲁棒性。
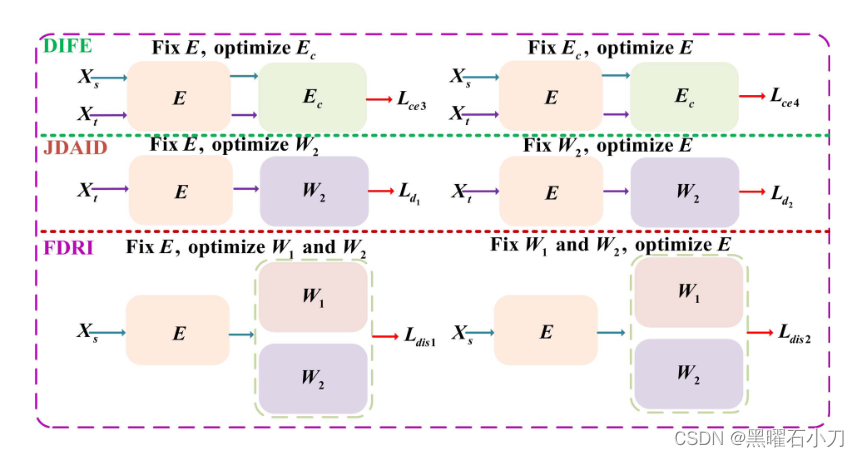
TALM 模块示意图。第一个对抗学习过程是在 DIFE 中的 E 和 Ec 之间执行的,这确保了提取的特征是域不变的。第二个对抗学习过程在 E 和 W 2 之间进行,以实现身份和域的联合分布对齐。第三个对抗性学习过程在 E 和 W1、W2 之间进行,以提高学习特征的可辨别性和鲁棒性。同时处理三个对抗性学习子模块。
DIFE Sub-Module:
每个相机都有自己的成像风格,为了获得域不变的特征,首先将相机风格的网络 Ec 应用于特征编码器 E 提取的特征。然后,在 Ec 和 E 之间进行对抗学习,以对齐来自不同相机视图的特征。该方法通过将训练样本分类到相同的附加类别,可以在域级别实现更有效的特征对齐。作为新增的类别,新增的类别与之前的所有类别不同。域对齐后,所有特征都归入这个附加类别。将全连接层的维度设置为 C s + C t + 1,其中 C s 和 C t 分别表示源域和目标域中的摄像机数量
给定源域图像 x i s 和目标域图像 x i t ,训练 Ec 以最小化以下损失,因此 Ec 可以正确识别 x i s 和 x i t 对应的相机 ID。
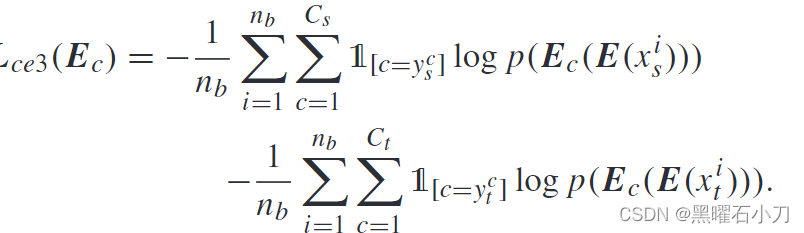
当 E 固定时,Ec 需要区分 E(x i t ) 和 E(x i s ) 的相机 ID。然而,当更新Ec时,更新E以确保通过Ec后,E提取的特征E(x i t )和E(x i s )可以分类到第(C s + C t + 1)个类别中。给定 y c c = C s + C t + 1,专门用于更新 E 的损失函数如下所示: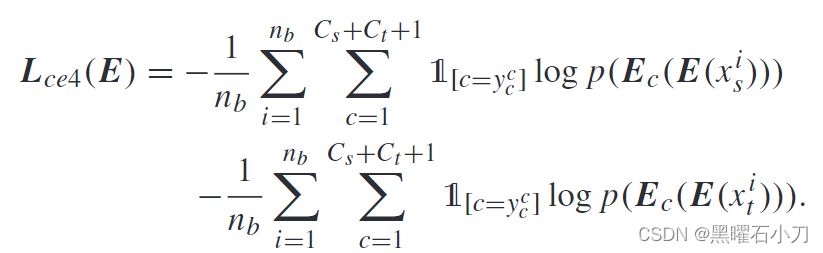
JDAID Sub-Module:
除了相机风格的差异外,其他因素也可能导致域差异。域和身份分类器是集成的。因此,在所提出的对抗性学习中,可以同时实现身份和域的联合分布对齐。
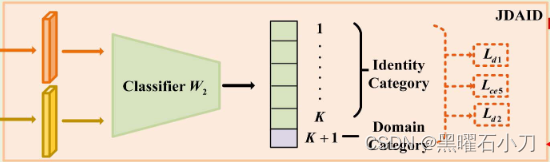
W 2 作为集成分类器由一个具有 (K + 1) 维的全连接层组成,第 (K + 1) 维是域类别。本文假设 W2 将第 i 个图像特征分类到相应的身份类别的概率为 θ,将第 i 个图像的域信息分类到第 K + 1 个类别的概率为 1 - θ 。
第i个图像的联合标签为
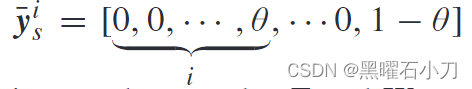
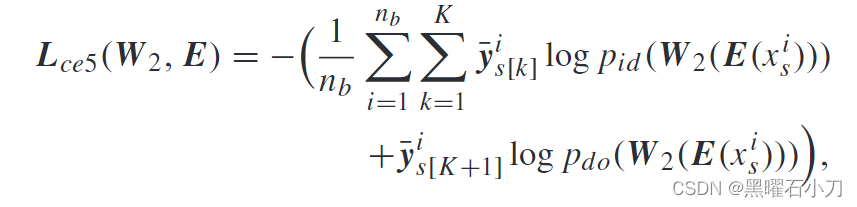
Y s = [ ̄y1 s , ̄y2 s , . . . , ̄yK s ]̄,yi s[k] 表示 ̄yi s 中的第 k 个元素,p id 是 x i s 属于特定身份的概率,p do 是 x i s 属于域类别的概率。
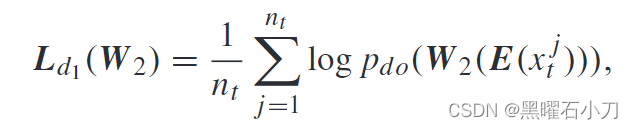
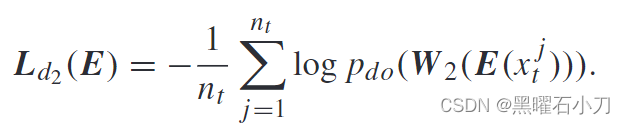
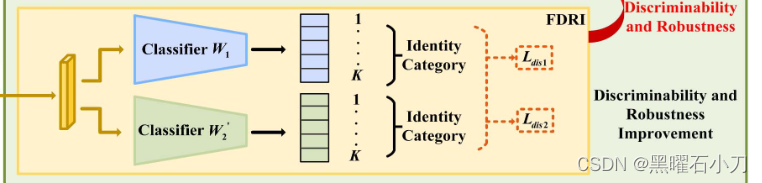
FDRI Sub-Module:
同时使用两个不同的分类器 W1 和 W2 来识别行人身份。这两个分类器是通过不同的方式学习的,因此可以从不同的角度来提高学习到的特征的可辨别性。当两个分类器对同一图像给出一致的分类结果时,学习到的特征具有鲁棒性和判别性。但是,由于两个分类器的输出维度不同,不能直接一起使用。为此,首先将域神经元从W2中移出,然后得到分类器W2‘。之后,分类器 W 1 和 W 2’ 可以通过对抗学习进行优化。在更新编码器E之后,更新两个分类器W1和W2‘,根据两个分类器关注的不同,将同一身份的行人图像分类为不同的个体类。同时,W1 和W 2’ 可以正确识别具有相同身份的行人图像。在更新W1和W 2‘ 之后,编码器E依次更新。
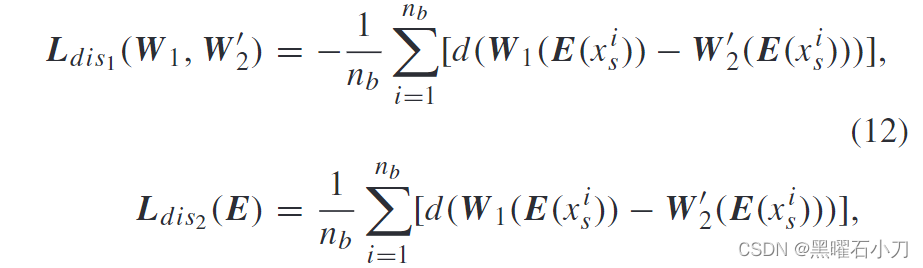
CN
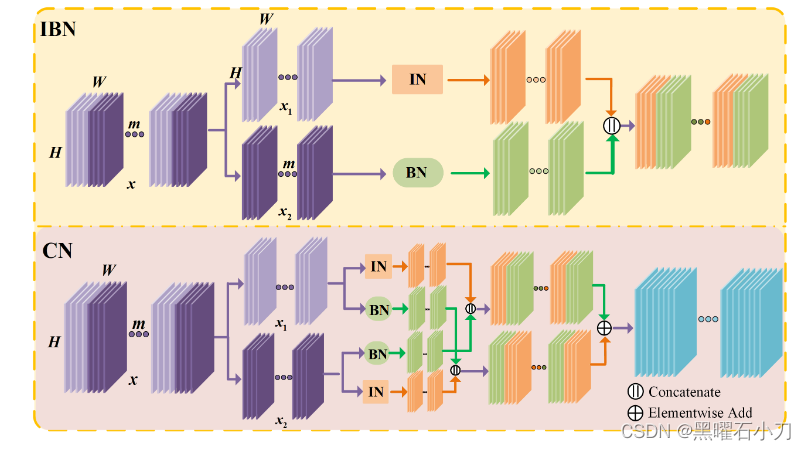
特征图首先被分成两个相等的部分(即 x1 和 x2 )。与 IBN 不同的是,本文提出的解决方案首先分别对 x1 和 x2 执行 IN 和 BN,同时提出的解决方案也分别对 x1 和 x2 执行 BN 和 IN。然后得到最终的归一化结果如下:
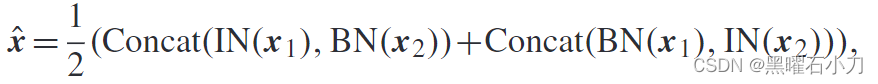
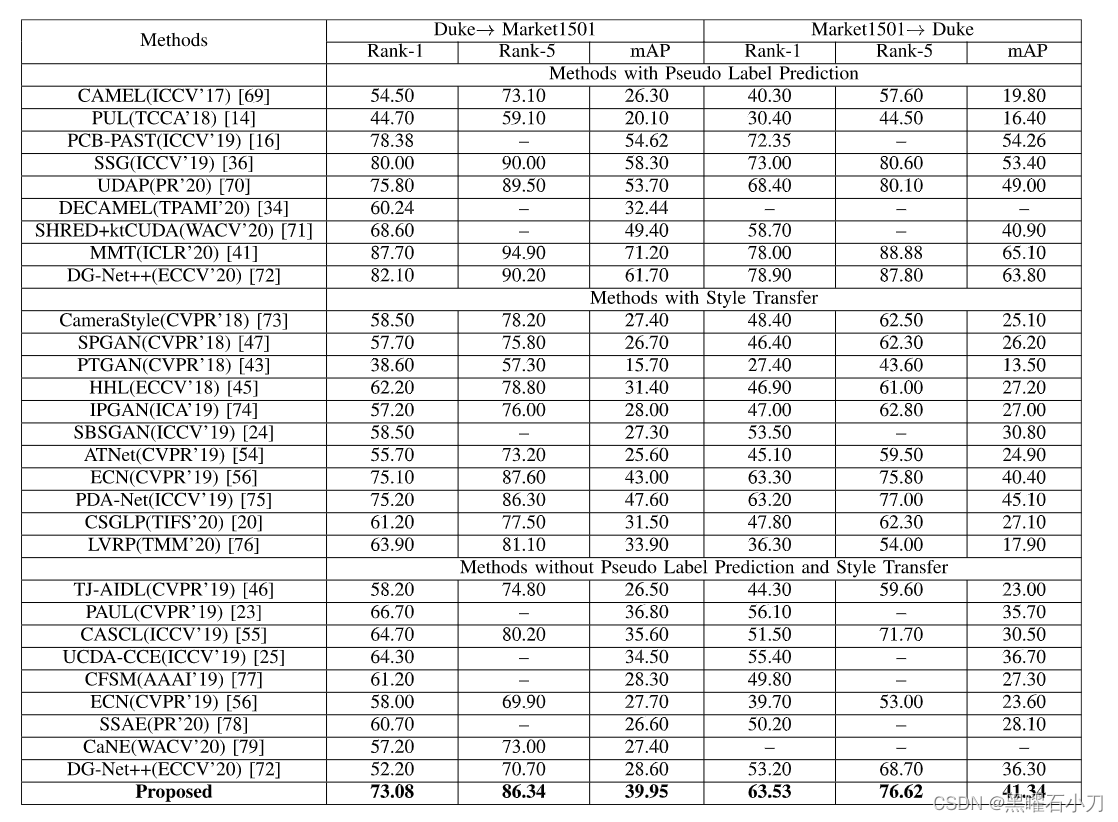
实验结果:














 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









