







0. 引言
Re-ID 作为一个特定的人检索问题,在不重叠的摄像机上被广泛研究。给定一个感兴趣的查询人,重新标识的目标是确定这个人是否在不同的时间出现在另一个地方,由不同的相机拍摄。查询人可以由图像、视频序列甚至文本描述来表示。由于公共安全的迫切需求以及大学校园、主题公园、街道等处监控摄像头数量的不断增加,在智能视频监控系统设计中,人的身份识别势在必行。
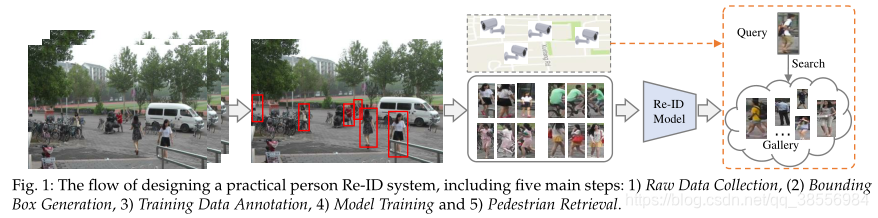
人员重新识别是指从计算机视觉的角度来看,通过多个监控摄像机的行人检索问题。一般来说,为特定场景构建人员重新标识系统需要五个主要步骤(如图1所示):
第一步:原始数据采集:从监控摄像头获取原始视频数据是实际视频调查的首要要求。这些摄像机通常位于不同环境下的不同地方,最有可能的是,这些原始数据包含了大量复杂且有噪声的背景杂波。
第二步:包围盒生成:从原始视频数据中提取包含人物图像的包围盒。一般来说,在大规模的应用程序中,不可能手动裁剪所有的人物图像。边界框通常由行人检测或跟踪算法获得。
第三步:训练数据标注:标注跨摄像机标签。由于摄像机之间的差异很大,训练数据标注对于有区别的重复识别模型学习通常是必不可少的。
第四步:模型训练:用先前标注的人物图像/视频训练一个有区别的、健壮的重识别模型。
第五步:行人检索:测试阶段进行行人检索。给定一个感兴趣的人(查询)和一个图库集,我们使用前一阶段学习的重标识模型提取特征表示。通过对计算出的查询到图库的相似性进行排序来获得检索到的排名列表。
下面主要介绍封闭世界的人的再识别。这种设置通常有以下假设:1)人的外观是由单模态可视摄像机捕获的,或者是图像,或者是视频;2)人员由边界框表示,其中大多数边界框区域属于相同的身份;3)训练有足够的带注释的训练数据用于有监督的有区别的重标识模型学习;4)注释大体正确;5)查询人必须出现在图库集合中。典型地,一个标准的封闭世界再识别系统包含三个主要组成部分:特征表示学习,它侧重于开发特征构建策略;深度度量学习,旨在设计不同损失函数或抽样策略的训练目标;和排名优化,其集中于优化检索到的排名列表。
1. Feature Representation Learning(特征表示学习)
我们首先讨论了封闭世界中的特征学习策略。有四个主要类别(如图2所示):a)全局特征,它为每个人图像提取一个全局特征表示向量,而不需要额外的注释提示;b)局部特征,它聚集部分级别的局部特征,以形成每个人物图像的组合表示;c)辅助特征,其使用辅助信息,例如属性、GAN生成的图像等,来改进特征表示学习。d)视频特征,它使用多个图像帧和时间信息学习基于视频的重标识的视频表示。我们回顾下针对人员重新标识的几个具体架构设计。

1.1 全局特征
全局特征表示学习为每个人物图像提取全局特征向量,如图2(a)所示。由于深度神经网络最初应用于图像分类,因此在早期将高级深度学习技术集成到人再识别领域时,全局特征学习是主要选择。此外在文献中已经广泛研究了注意力方案以增强表征学习。对于人物图像内的注意:和谐注意CNN (HA-CNN)模型联合学习软像素注意和硬区域注意,增强特征表示对错位的鲁棒性。
1.2 局部特征
局部特征表示通常学习区域聚集特征,使其对错位变化具有鲁棒性。人体部分或者通过人体姿态估计生成,或者通过粗略的水平分割生成。主要趋势是结合全局和局部特征。有些工作通过在训练框架中集成局部身体部分特征和全局全身特征,设计了多通道部分聚集的深度卷积网络。类似地,多尺度上下文感知网络通过堆叠多尺度卷积来捕获身体部位之间的局部上下文知识。沿着这一思路,提出了多级特征分解和选择性树形结构融合框架来捕捉宏观和微观特征。
1.3 辅助特征表示学习
辅助特征表示学习通常需要附加的注释信息(例如,语义属性)或生成/增强的训练样本来加强特征表示。
语义属性。提出了一种深度属性学习框架,通过结合预测的语义属性信息,以半监督学习方式增强特征表示的泛化能力和鲁棒性。语义属性和注意方案都被合并以改进零件特征学习,还采用语义属性进行视频重标识特征表示学习。在无监督学习中,它们也被用作辅助监督信息。通过对每个人物图像的语言描述,通过挖掘全局和局部图像-语言关联来实施表征学习,约束视觉和语言特征之间的一致性。这也提高了视觉表征学习。
视点信息。视点信息也被用来增强特征表示学习。MLFN还试图在多个语义级别学习身份鉴别和视图不变特征表示。有人还试图]利用视图混淆特征学习提取了视图不变同态表示,该学习是视图通用学习和视图专用学习的组合。
域名信息。将每个摄像机视为不同的域,提出了多摄像机一致匹配约束,以在深度学习框架中获得全局最优表示。类似地,摄像机视图信息或检测到的摄像机位置也在[17]中应用,以利用摄像机特定的信息建模来改善特征表示。
GAN。用增强的/GAN生成的图像作为辅助信息。郑等[33]首次尝试将GAN技术应用于人体再识别。利用生成的人物图像改进了有监督的特征表示学习。
数据增广。对于增强的辅助信息,产生对抗遮挡样本以增强训练数据的变化。提出了一种类似但简单得多的随机擦除策略,给输入图像添加随机噪声。批量丢弃块在特征图中随机丢弃一个区域块,以加强注意力集中的特征学习。Bak等人生成了在不同光照条件下渲染的虚拟人,丰富了监督数据。所有这些方法都用扩充的训练集丰富了监督,提高了对未知测试样本的泛化能力。
1.4 视频特征表示学习
基于视频的重新标识是另一个热门话题,其中每个人都由一个具有多个帧的视频序列来表示。由于丰富的外观和时间信息,它在ReID社区中获得了越来越多的兴趣。这也给多图像视频特征表示学习带来了额外的挑战。
1.5 结构设计
将人的重新识别作为一个具体的行人检索问题,现有的大多数作品都采用了为图像分类而设计的网络架构作为主干。一些作品试图修改主干架构,以实现更好的重新标识功能。对于广泛使用的ResNet50主干,重要的修改包括将最后一个卷积条带/大小更改为1 ,在最后一个汇集层采用自适应平均汇集,并在汇集层之后添加具有批处理规范化的瓶颈层。
2. Deep Metric Learning(深度度量学习)
度量学习的作用已经被损失函数设计所取代,以指导特征表示学习。我们将首先回顾2广泛使用的损失函数,然后用具体的抽样设计总结训练策略。
2.1 损失函数设计
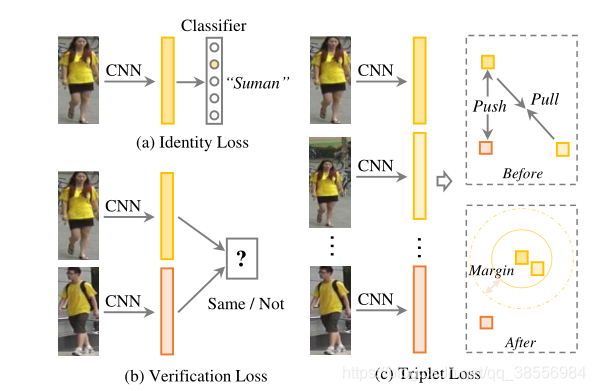
文献中有三种广泛研究的损失函数及其变体,包括身份损失、验证损失和三重损失。
身份损失。它将人重新身份的训练过程视为一个图像分类问题,即每个身份是一个不同的类。在测试阶段,采用汇集层或嵌入层的输出作为特征提取器。给定一个带有标签
y
i
y_i
yi的输入图像
x
i
x_i
xi,被识别为类别
y
i
y_i
yi的预测概率用一个softmax函数编码,用
p
(
y
i
∣
x
i
)
p(y_i|x_i)
p(yi∣xi)表示。然后通过交叉熵计算身份损失:
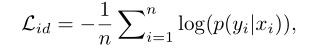
验证损失。它通过对比损失或二元验证损失来优化成对关系。对比损失改善了相对成对距离比较:
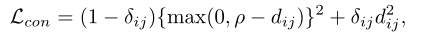
验证损失通常与身份丢失相结合,以提高性能。
三重损失。它将重标识模型训练过程视为一个检索排序问题。基本思想是正对之间的距离应该比负对小一个预定的余量。通常,一个三元组包含一个anchor样本 x i x_i xi,一个相同身份的正样品 x j x_j xj,和一个不同身份的负样品 x k x_k xk。带有余量参数的三重态损失由下式表示:
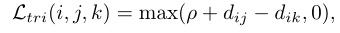
一些方法还研究了信息三元组挖掘的点对集相似策略。提出了一种用于深度度量学习的点对集合相似度,用点对集合度量代替了点到点的距离。
2.2 训练策略
批量采样策略在判别重标识模型学习中起着重要作用,特别是对于难以挖掘的三重损失。不同于一般的图像分类,每个图像的训练图像的数量明显不同。同时,严重不平衡的正负样本对增加了训练策略的额外挑战。处理不平衡问题最常用的训练策略是身份抽样。对于每个训练批次,随机选择一定数量的身份然后从每个选择的身份中采样几幅图像。采样图像形成训练批次。这种批量抽样策略保证了正负信息的挖掘。
为了进一步处理正负样本之间的不平衡问题,在[82]中提出了采样率学习(SRL),以自适应地调整正样本和负样本的贡献。在[43]中引入了自适应加权三重态损失,以利用相似性差异来平衡正负三重态。在[80]中还研究了一种聚焦损失方案来处理不平衡问题。在[80]中设计了一种课程抽样策略,先选择容易的三胞胎,再优化难的三胞胎。
为了自适应地组合多个损失函数,多损失动态训练策略[162]自适应地重新加权身份损失和三元组损失,提取它们之间共享的适当分量。这种多损失训练策略带来了持续的性能提升。
3. Ranking Optimization (排名优化)
在测试阶段,排序优化对提高检索性能起着至关重要的作用。给定初始排名列表,它通过自动图库间相似性挖掘或人工交互来优化排名顺序。等级/度量融合是另一种利用多个等级列表输入来提高等级性能的流行方法。
3.1 重排序
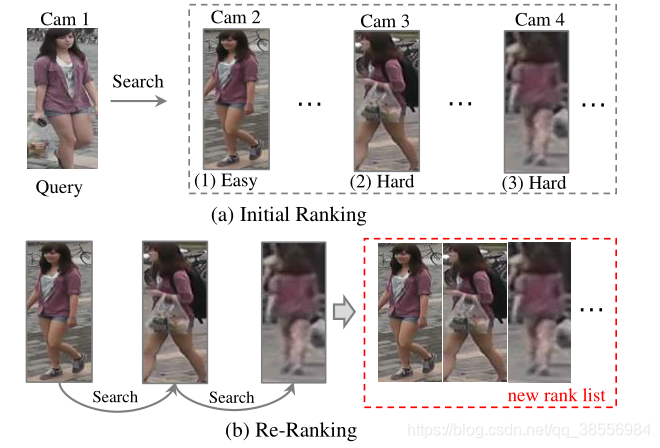
重新排序的基本思想是利用图库到图库的相似性来优化初始排序列表,如图4所示。在[163]中提出了一种使用排名靠前的相似性拉动和排名靠后的相异性推动的排名优化方法。在中引入了一种挖掘上下文信息的k-倒数编码的重新排序方法,以改进初始排序列表。由于它的简单性和有效性,它已被广泛应用于当前技术水平,以提高性能。利用底层流形的几何结构,从基于流形的亲和学习角度解决了重排序问题。通过整合交叉邻域距离,引入了扩展的交叉邻域重新排序方法。局部模糊重新排序采用聚类结构来改进邻域相似性测量,从而细化排序列表。
3.2 排名融合
用通过不同方法获得的多个等级列表来提高检索性能。文献提出了一种利用相似性和不相似性的等级聚合方法。人再识别中的等级融合过程被用图论表述为基于共识的决策问题,通过路径搜索将多个算法获得的相似性得分映射到一个图中。文献也研究了度量集成学习。
4. Datasets and Evaluation Metrics(数据集和评估)
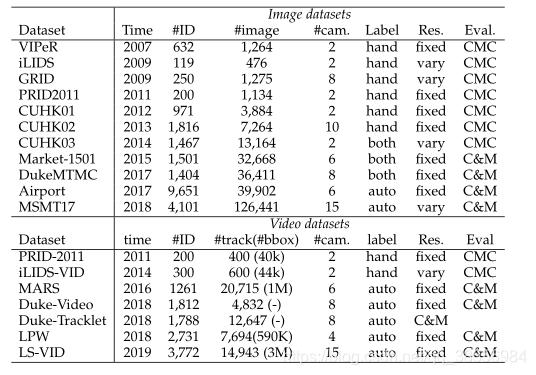
数据集。我们首先回顾了用于封闭世界设置的广泛使用的数据集,包括11个图像数据集(VIPeR ,iLIDS ,GRID [175],PRID2011 ,CUHK01-03 ,Market-1501,DukemMC,Airport 和MSMT17)和7个视频数据集(PRID-2011,iLIDSVID,MARS ,Duke-Video,Duke这些数据集的统计数据如表2所示。本调查仅关注深度学习方法的一般大规模数据集。
评价指标。累积匹配特性(CMC)和平均精度(MAP)是两种广泛使用的测量方法。
CMC-k(又名Rank-k匹配精度)表示在排名前 k k k的检索结果中出现正确匹配的概率。当每个查询只存在一个基本事实时,CMC是准确的,因为它在评估过程中只考虑第一个匹配。然而,通常包含大型相机网络中的多个基本事实,并且CMC不能完全反映一个模型在多个相机之间的可区分性。
另一个广泛使用的度量,即平均精度(mAP),衡量多个组的平均检索性能。对于重新标识评估,它可以解决两个系统在搜索第一个基本事实时同样可以度量的问题。
我们总结了四个数据集的结果,如图5所示。从这些结果中,我们可以得出五个主要的见解,如下所述。
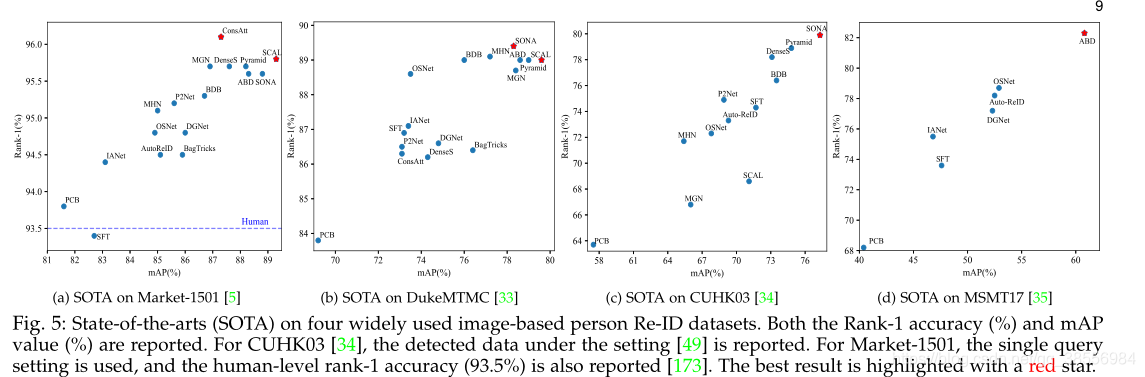
首先,随着深度学习的进步,在广泛使用的Market-1501数据集上,大多数基于图像的Re-ID方法都获得了比人类更高的rank1精度。
第二,零件级特征学习有利于区分性再识别模型学习。全局特征学习直接学习整个图像上的表示,而没有部分约束。当人检测/跟踪能够准确定位人体时,它是有区别的。当人的图像遭受大背景混乱或严重遮挡时,部分级特征学习通常通过挖掘有区别的身体区域来获得更好的性能。由于其在处理错位/遮挡方面的优势,我们观察到最近开发的大多数最先进的方法采用了特征聚合范式,结合了部分级别和完整的人体特征。
第三,注意有利于区分性再识别模型学习。我们观察到,在每个数据集上获得最佳性能的所有方(SCAL 、SONA)都采用了注意力方案。注意力捕捉不同卷积通道、多个特征图、分层、不同身体部位/区域甚至多个图像之间的关系。
第四,多损失训练可以提高Re-ID模型学习。不同的损耗函数从多角度优化网络。结合多种损失函数可以提高性能,最新方法中的多种损失训练策略证明了这一点。
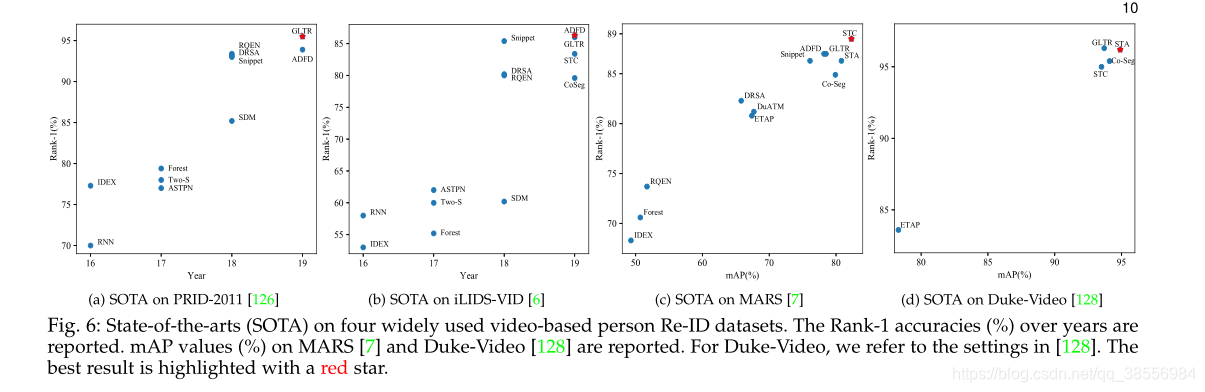
基于视频的重新标识。与基于图像的重新标识相比,基于视频的重新标识受到的关注较少。我们还总结了四个视频重标识数据集的结果,如图6所示。从这些结果中,可以得出以下观察结果。

















 2231
2231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









