







前言
神经网路若线性,一层一层叠上去的,对于这种网络的实现Sequential模型是更好的选择,但我们使用=>Keras API可以有multi-input/ output或是有向无环图
简单对比
以下两者效果相同,后者使用Keras API。
有了api方便我们实现重复调用模型,注意重复使用的话权重也是相同的。


- API的架构

Mulit-input
- 架构

from keras.models import Model
from keras import layers
from keras import Input
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
##文本
text_input = Input(shape=(None,), dtype='int32', name='text') #shape 一维
embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input)
encoded_text = layers.LSTM(32)(embedded_text)
##题目
question_input = Input(shape=(None,), dtype='int32', name='question')
embedded_question = layers.Embedding(question_vocabulary_size, 32)(question_input)
encoded_question = layers.LSTM(16)(embedded_question)
#合成起來concatenate 沿著 -1=>32/16-(48,)
concatenated = layers.concatenate([encoded_text, encoded_question],axis=-1)
#接输出
answer = layers.Dense(answer_vocabulary_size,
activation='softmax')(concatenated)
model = Model([text_input, question_input], answer)#輸入輸出框起來Model
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['acc'])
多输出层
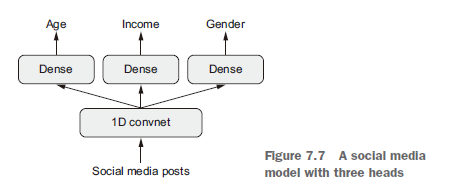
- 架构

超参数选择
安装套件Hyperas
自行定义网络架构后,以{{}}让机器自行决定超参数。
原理:
在N中只要有可能挑到最好的k就好,因此机率维K/N。
尝试挑选x次,得到最好的K机率为(1-(K/N)**x)
试想,若取K的机率达90%,即可在减少成本下采用抽样发访来达到选取最佳参数K的结果。
举例来说,若N=1000,K=10,在达到90%概率拿到最佳K石,只需要抽样230即可。
步骤:
- 从集合中选定超参数
- 建立对应的模型
- 配适训练资料,评估模型表现,重复步骤,找出最合适的超参数
难点
- 要重复做模型,是很昂贵的成本
- 超参数通常是离散的,因此不能使用梯度下降。因此效率较低。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









