







一、生成模型的定义
- 给定的训练集 X = { x 1 , x 2 , . . . , x n } X =\{x^1,x^2,...,x^n\} X={x1,x2,...,xn}
- 隐变量 z z z满足 p ( z ) = N ( 0 , I ) p(z)= \mathcal{N} (0,I) p(z)=N(0,I)
- 定义一个条件分布 p θ ( x ∣ z ) p_{\theta}(x|z) pθ(x∣z), θ \theta θ可以理解为生成模型的参数
- 训练好模型后,采样 z ∼ p ( z ) z{\sim}p(z) z∼p(z),利用 p θ ( x ∣ z ) p_{\theta}(x|z) pθ(x∣z)可以生成 x x x
注: p θ ( x ∣ z ) p_{\theta}(x|z) pθ(x∣z)可以理解为“生成器”,把高斯 z z z映射到数据分布 x x x
二、四种代表生成模型
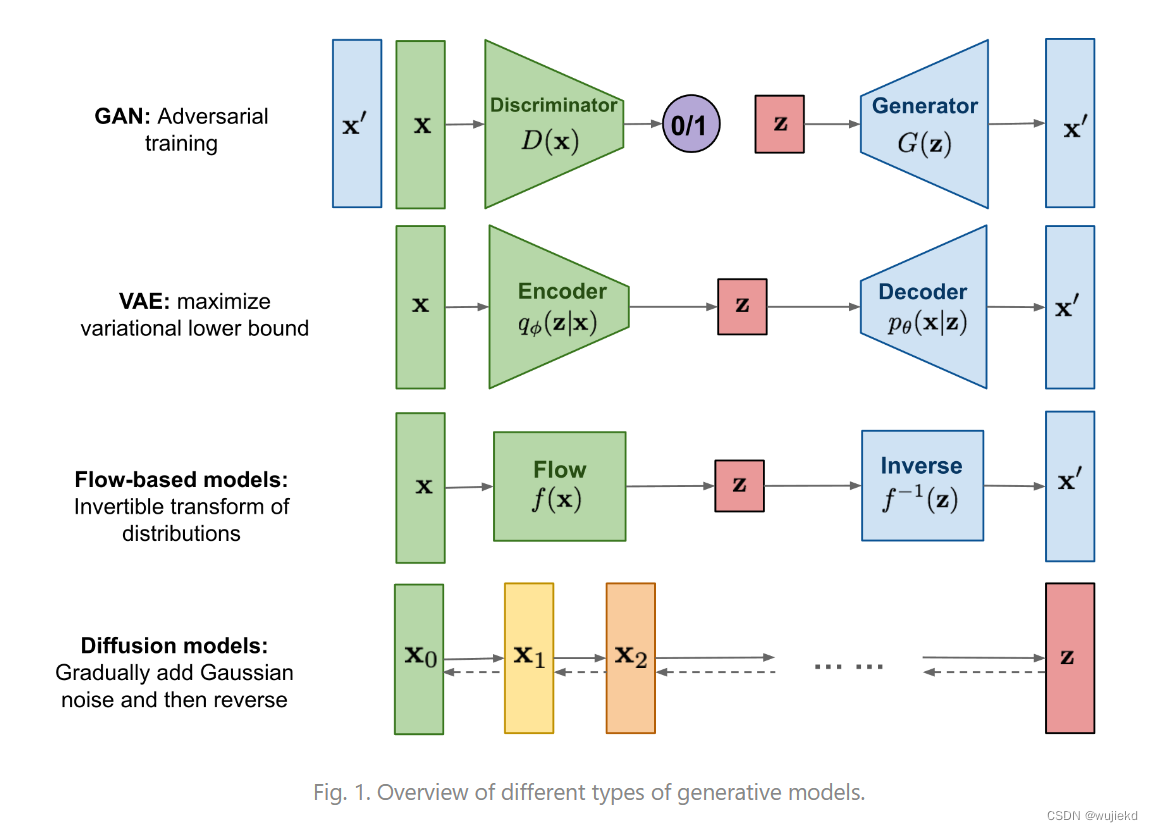
1. VAE
注:Diffusion model的部分理论推导和VAE很相似
目的是能够得到真实数据的分布
p
(
x
)
p(x)
p(x),这样就可以随意的生成数据。
借助隐变量
z
z
z描述
x
x
x的分布
p
(
x
)
p(x)
p(x):
p
(
x
)
=
∫
p
(
x
,
z
)
d
z
=
∫
p
(
x
∣
z
)
p
(
z
)
d
z
p(x) = \int p(x,z)dz = \int p(x|z)p(z)dz
p(x)=∫p(x,z)dz=∫p(x∣z)p(z)dz
目标是最大化似然 p θ ( x ) p_{\theta}(x) pθ(x), p θ ( x ) p_{\theta}(x) pθ(x) = p θ ( z , x ) p θ ( z ∣ x ) \frac{p_{\theta}(z,x)}{p_{\theta}(z|x)} pθ(z∣x)pθ(z,x)= p θ ( z ) p θ ( x ∣ z ) p θ ( z ∣ x ) \frac{p_{\theta}(z)p_{\theta}(x|z)}{p_{\theta}(z|x)} pθ(z∣x)pθ(z)pθ(x∣z)
但是 p θ ( z ∣ x ) {p_{\theta}(z|x)} pθ(z∣x)是intractable的,通常我们都需要借助variational inference的技巧,采用 q ϕ ( z ∣ x ) {q_{\phi}(z|x)} qϕ(z∣x)去近似它。
将最大化似然
p
θ
(
x
)
p_{\theta}(x)
pθ(x)转化成使得 ELBO(变分下界)最大
模型似然
log
p
θ
(
x
)
≥
E
L
B
O
\log p_{\theta}(x) \geq ELBO
logpθ(x)≥ELBO,
E
L
B
O
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
log
p
θ
(
x
∣
z
)
+
log
p
(
z
)
−
log
q
ϕ
(
z
∣
x
)
]
=
E
z
∼
q
ϕ
(
z
∣
x
)
log
p
θ
(
x
∣
z
)
−
D
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
(
z
)
)
ELBO = \mathbb{E}_{z\sim q_{\phi}(z|x)} [\log p_{\theta}(x|z) + \log p(z) - \log q_{\phi}(z|x)] = \mathbb{E}_{z\sim q_{\phi}(z|x)} \log p_{\theta}(x|z) - D_{KL}(q_{\phi}(z|x)||p(z))
ELBO=Ez∼qϕ(z∣x)[logpθ(x∣z)+logp(z)−logqϕ(z∣x)]=Ez∼qϕ(z∣x)logpθ(x∣z)−DKL(qϕ(z∣x)∣∣p(z))
p
θ
(
x
∣
z
)
p_{\theta}(x|z)
pθ(x∣z)为decoder部分,
q
ϕ
(
z
∣
x
)
q_{\phi}(z|x)
qϕ(z∣x)为encoder部分
模型的优化的loss为
L
V
A
E
(
θ
,
ϕ
)
=
−
E
L
B
O
=
D
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
(
z
)
)
−
E
z
∼
q
ϕ
(
z
∣
x
)
log
p
θ
(
x
∣
z
)
L_{VAE}(\theta,\phi) = -ELBO = D_{KL}(q_{\phi}(z|x)||p(z)) - \mathbb{E}_{z\sim q_{\phi}(z|x)} \log p_{\theta}(x|z)
LVAE(θ,ϕ)=−ELBO=DKL(qϕ(z∣x)∣∣p(z))−Ez∼qϕ(z∣x)logpθ(x∣z)
第一项为计算两个多元高斯分布的KL散度
第二项为重建误差(reconstruction error),因为正是给定下
z
z
z生成真实数据的似然,对于一个给定的训练样本
x
i
x^i
xi,我们可以采用蒙特卡洛方法(Monte Carlo method)来估计这个数学期望,即从
q
ϕ
(
z
∣
x
i
)
q_{\phi}(z|x^i)
qϕ(z∣xi)多次采样来估计
−
E
z
∼
q
ϕ
(
z
∣
x
)
log
p
θ
(
x
i
∣
z
)
≈
−
1
L
∑
l
=
1
L
log
p
θ
(
x
i
∣
z
(
i
,
l
)
)
- \mathbb{E}_{z\sim q_{\phi}(z|x)} \log p_{\theta}(x^i|z) \approx -\frac{1}{L}\sum^{L}_{l=1}\log p_{\theta}(x^i|z^{(i,l)})
−Ez∼qϕ(z∣x)logpθ(xi∣z)≈−L1∑l=1Llogpθ(xi∣z(i,l))
2. GAN和Flow-based Model
GAN和Flow-based Model,都是只需要一个“生成器”,先采样高斯噪声,然后用“生成器”把这个高斯噪声映射到数据分布就可以,而且只关心生成。
但是GAN和Flow-based Model也有别的缺陷,比如GAN还需要额外训练判别器,这导致训练很困难;而Flow-based Model需要模型是可逆函数,不能随便用一个图像分类or分割领域的SOTA神经网络,这也导致模型表达能力受限。
3. Diffusion model
只需要训练“生成器”,训练目标函数简单,而且不需要训练别的网络(判别器/后验分布等),并且这个生成器没啥限制,可以随便选表达能力极强的神经网络。
前向和反向是两条马尔可夫链。
-
前向过程(加噪过程)
1、前者通常是手工设计的,目的是将任何数据分布转换为简单的先验分布(例如,标准高斯)
2、定义: q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t |x_{t-1}) = \mathcal{N}(x_t;\sqrt{1- \beta_t}x_{t-1},\beta_t\mathcal{I}) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
原图 x 0 x_0 x0,通过不断的高斯采样噪声,得到 x t x_t xt。当 t t t趋近无穷, x T x_T xT得到的就是标准的高斯噪声,均值为0,方差为1。
3、任意时刻的 x t x_t xt能通过 x 0 x_0 x0和 β \beta β表示,假设 α t = 1 − β t \alpha_t = 1-\beta_t αt=1−βt,并且 α ‾ t = ∏ i = 1 T α i \overline\alpha_t =\prod^T_{i=1}\alpha_i αt=∏i=1Tαi,展开 x t x_t xt可以得到: x t = α ‾ t x 0 + 1 − α ‾ t z ‾ t x_t=\sqrt{\overline\alpha_t}x_0+\sqrt{1-\overline\alpha_t}\overline{z}_t xt=αtx0+1−αtzt -
反向过程(去噪过程)
1、利用 x t x_t xt,使用一个深度学习模型(U-net,参数为 θ \theta θ),去计算出 x t − 1 x_{t-1} xt−1
2、定义: p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , ∑ θ ( x t , t ) ) p_\theta(x_{t-1}|x_t)=\mathcal{N}(x_{t-1};\mu_\theta(x_t,t),\sum_\theta(x_t,t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),∑θ(xt,t))反向过程由贝叶斯定理可以推导,其中由于 q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q(x_{t-1}|x_t,x_0)=q(x_{t}|x_{t-1},x_0)\frac{q(x_{t-1}|x_0)}{q(x_{t}|x_0)} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0),可推导其分布如下:
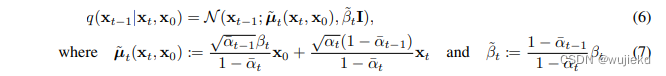
可以看到 x t − 1 x_{t-1} xt−1方差是一个定量(扩散过程参数固定),而 x t − 1 x_{t-1} xt−1均值是一个依赖 x 0 x_{0} x0和 x t x_{t} xt的函数。这个分布将会被用于推导扩散模型的优化目标。
特性2指的是: x t = α ‾ t x 0 + 1 − α ‾ t z ‾ t x_t=\sqrt{\overline\alpha_t}x_0+\sqrt{1-\overline\alpha_t}\overline{z}_t xt=αtx0+1−αtzt转换得到 x 0 x_0 x0

z
‾
t
\overline{z}_t
zt是从
x
0
x_0
x0到
x
t
x_t
xt过程加的噪声,但是没有
x
0
x_0
x0,我们无法得到
z
‾
t
\overline{z}_t
zt,则可以使用模型帮我们去得到
z
θ
{z}_\theta
zθ,然后在得到
x
0
x_0
x0,最后可以计算
x
t
−
1
的均值和方差
x_{t-1}的均值和方差
xt−1的均值和方差。
z
θ
{z}_\theta
zθ是模型预测的噪声,需要输入
x
t
x_t
xt和
t
t
t,
t
t
t帮助模型知道是第几次加,噪声会根据
t
t
t对噪声有一个
β
\beta
β的放缩。
-
优化目标
-
最大化 p θ ( x 0 ) p_{\theta}(x_0) pθ(x0),但是 p θ ( x 1 : T ∣ x 0 ) {p_{\theta}(x_{1:T}|x_0)} pθ(x1:T∣x0)是intractable的,求解和VAE类似,采用 q ϕ ( x 1 : T ∣ x 0 ) {q_{\phi}(x_{1:T}|x_0)} qϕ(x1:T∣x0)去近似它,区别就是 x 0 x_0 x0到隐变量 z z z的后验变成 x 0 x_0 x0到 x 1 : T x_{1:T} x1:T的后验。和VAE的推导下界类似。 q ϕ ( x 1 : T ∣ x 0 ) {q_{\phi}(x_{1:T}|x_0)} qϕ(x1:T∣x0)由定义的前向的式子可算。
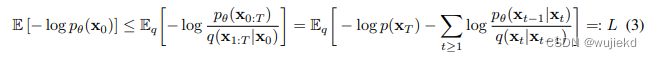
-
完全展开后,优化的目标为
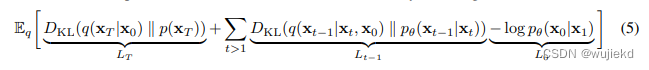
-
再看一下优化的目标,没有参数的部分可以直接忽略,即 L T L_T LT。而 L t − 1 L_{t-1} Lt−1根据多元高斯分布的KL散度求解等价于下面的式子
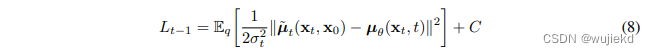
-
最后把式子(7)的均值代进(8)的左边,将 x t x_t xt通过 x 0 x_0 x0进行表示,可得最终的优化目标
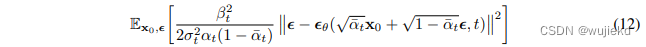
-
最后得到的简化loss如下:
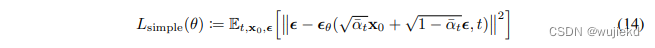
-
-
推理过程
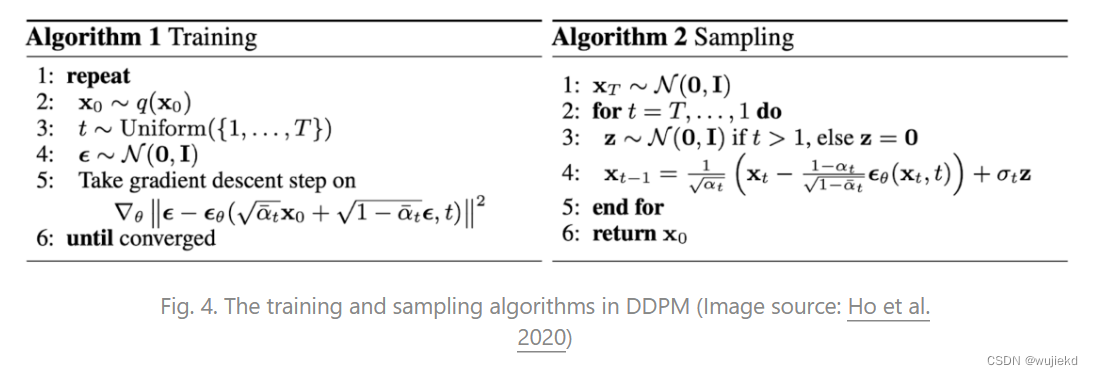
上面是discrete model (DDPM) 最先提出的形式
下面是continuous model (SDE) 完善理论框架
首次揭示了diffusion model的连续版本对应的数学背景,并且将统计机器学习中的denoising score matching方法与DDPM中的去噪训练统一起来。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











