







1、试试看
import wordcloud
"""
wordcloud库把词云当作一个WordCloud对象
- wordcloud.WordCloud()代表一个文本对应的词云
- 可以根据文本中词语出现的频率等参数绘制词云
- 词云的绘制形状、尺寸和颜色都可以设定
"""
"""
-步骤1:配置对象参数,默认宽400高200
- 以WordCloud对象为基础
- 配置参数、加载文本、输出文件
"""
w = wordcloud.WordCloud()
"""
- 步骤2:加载词云文本
w.generate(txt): 向WordCloud对象w中加载文本txt
"""
w.generate("hello world")
"""
- 步骤3:输出词云文件
w.to_file(filename):将词云输出为图像文件,.png或.jpg格式
"""
w.to_file("helloworld.png")
2、配置对象参数




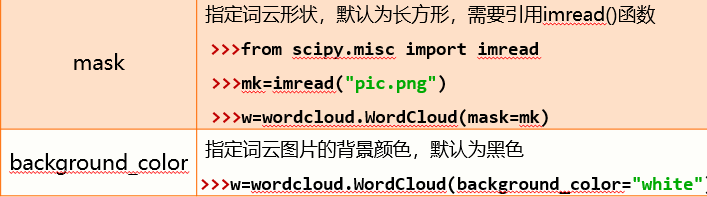
from scipy.misc import imread 报错的话

图片需要自己下
3、实例: 政府工作报告词云1
参考学习于:【Python程序设计(七)】文件和数据格式化
import jieba
import wordcloud
import urllib.request
url = "https://python123.io/resources/pye/"+urllib.parse.quote("新时代中国特色社会主义.txt")
# urllib.parse.quote 只能用于局部中文,对于整个url会报错
infile = urllib.request.urlopen(url)
t = infile.read().decode('utf-8')
ls = jieba.lcut(t) # 精确模式 返回列表类型
txt = " ".join(ls)
w = wordcloud.WordCloud(font_path="msyh.ttc", width=1000, height=700, background_color="white")
w.generate(txt)
w.to_file("grwordcloud.png")

涉及知识点:
python第三方库jieba(结巴)的学习
用urllib.parse.quote()对网址链接中的中文进行处理
4、实例: 政府工作报告词云2
import jieba
import wordcloud
import urllib.request
from imageio import imread
url = "https://python123.io/resources/pye/" + urllib.parse.quote("新时代中国特色社会主义.txt")
# urllib.parse.quote 只能用于局部中文,对于整个url会报错
infile = urllib.request.urlopen(url)
f = infile.read()
t = f.decode('utf-8')
mask = imread("fivestar.png")
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud(font_path="msyh.ttc", mask=mask, width=1000, height=700, background_color="white")
w.generate(txt)
w.to_file("grwordcloud.png")
素材1:五角红星

成品:

素材2:

成品:

















 3062
3062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











