







说一下电脑配置是4090的显卡,cuda为12.2,显存24G,内存64G,可以实现模型的部署~
首先下载ollama框架,下载链接官方网站https://ollama.com/,国内在下载github时往往会下载过慢,也可以从此链接中ollama的win版本下载。
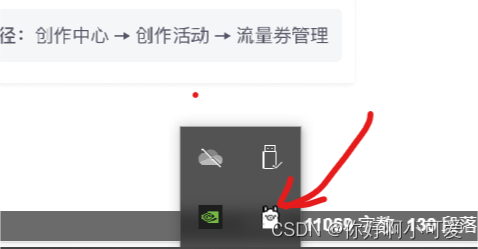
1.下载按照提示的步骤安装即可,安装成功后右下角会有一个羊驼的标志
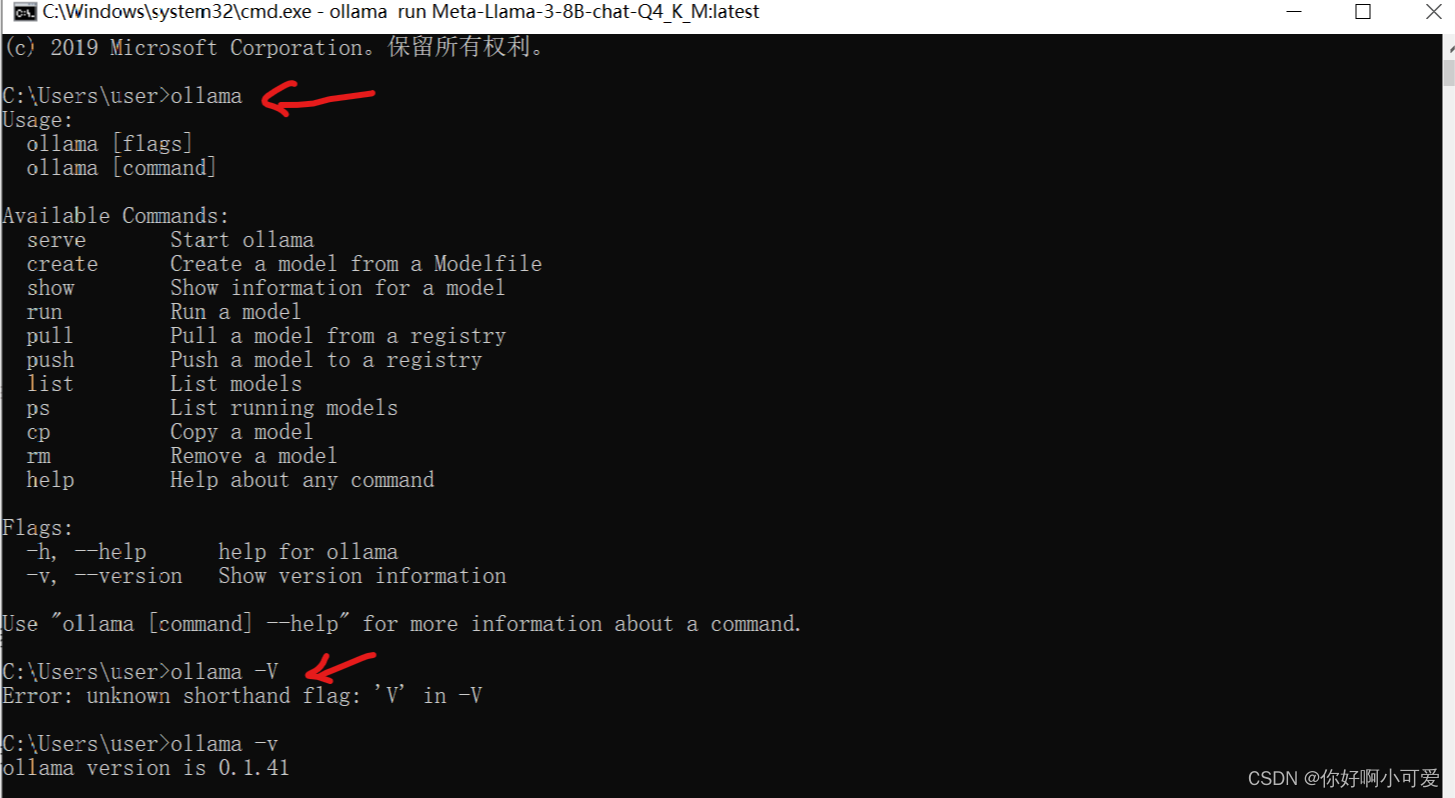
2.之后打开CMD窗口,检查ollama是否安装成功,输入以下命令如果出现类似提示,则显示安装成功。
3.在ollamav.1.39版本之后能够实现直接将模型量化,如Safetensors等格式可以用于ollama模型加载,转换模型过程十分简单。
从Hugging Face 下载一个带Safetensors 文件格式的模型,可以自行选择。用cd 切换到当前目录,如下所示

在当前文件夹下编写Modelfile文件,也就是在Meta-Llama-3-8B-Instruct文件夹下创建Modelfile文件
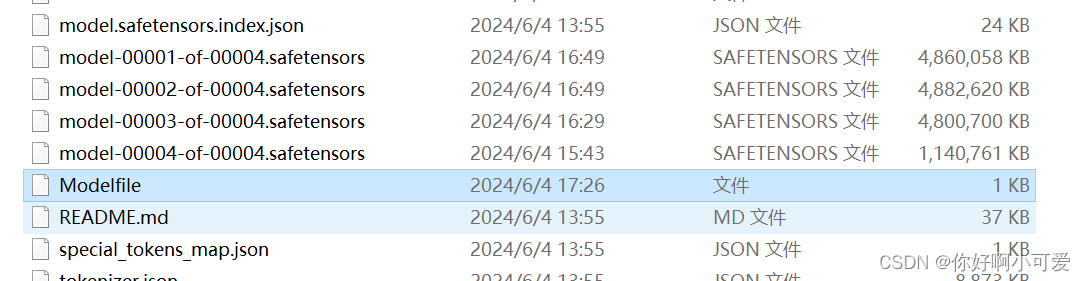
文件代码
FROM .
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
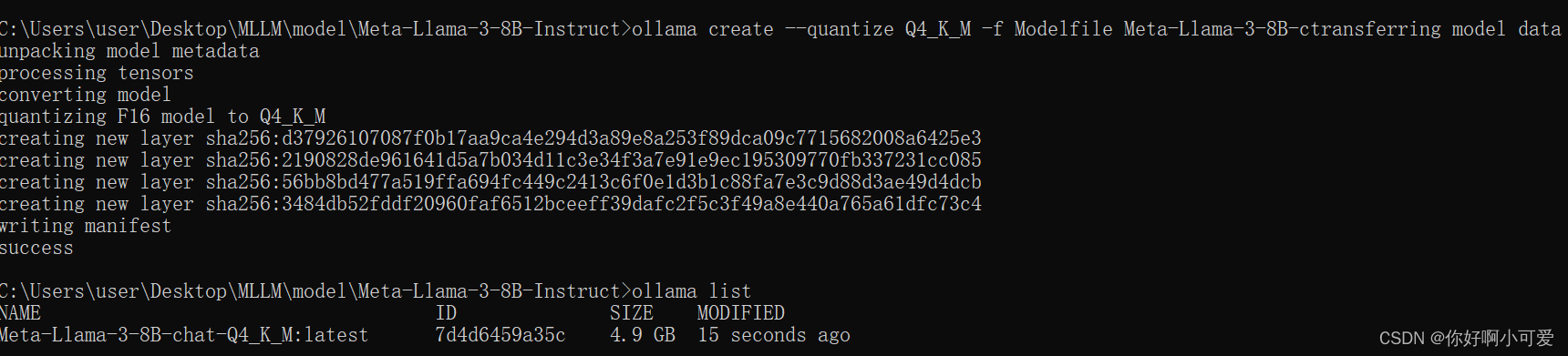
4.在cmd中输入模型量化命令
ollama create --quantize Q4_K_M -f Modelfile Meta-Llama-3-8B-chat-Q4_K_M
完事之后耐心等待,之后成为下图
5.最后运行模型,输入命令
ollama run Meta-Llama-3-8B-chat-Q4_K_M:latest
如下图所示

最后开启你的大模型学习之旅吧~


















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









