






引用
Transformer 和大型语言模型在自然语言处理 (NLP) 领域被引入后风靡全球。自成立以来,该领域一直在快速发展,通过创新和研究使这些 LLM 更加高效。其中包括 LoRA(Low-Rank Adaption)、Flash Attention、Quantization 以及最近著名的 LLM 的合并方法。在本指南中,我们将介绍一种合并 Upstage AI 引入的 LLM (Solar 10.7B) 的新方法。

学习目标
● 了解 Solar 10.7B 的独特架构及其创新的“深度升级”
● 探索模型的预训练过程及其使用的各种数据
● 分析 Solar 10.7B 在不同 NLP 任务中令人印象深刻的性能基准
● 将 Solar 10.7B 与其他著名的 LLM(如 Mixtral MoE)进行比较和对比
● 了解如何为您的项目访问和使用 Solar 10.7B
本文作为数据科学博客马拉松的一部分发布。
目录
● 什么是SOLAR 10.7B?
● 什么是深度向上扩展?
● 培训 SOLAR 10.7B
● 评估和基准测试结果
● SOLAR 10.7B 入门
● SOLAR 10.7B 与 Mixtral MoE
● 限制和注意事项
● 常见问题解答
什么是SOLAR 10.7B?
Upstange AI 推出了新的 107 亿参数模型 SOLAR 10.7B。该模型是合并两个 70 亿参数模型的结果,特别是两个 Llama 2 70 亿模型,它们经过预训练以创建 SOLAR 10.7B。这种合并的独特之处在于应用了一种称为深度放大 (DUS) 的新方法,与采用混合专家的 Mixtral 方法形成鲜明对比。
新的 10.7B 型号优于 Mistral 7B、Qwen 14B。一个名为 SOLAR 10.7B Instruct 的 Instruct 版本已经发布,一经发布,它就登上了排行榜的榜首,超过了 Qwen 72B 和 Mixtral 8x7B 大型语言模型。尽管是一个 107 亿参数的模型,但 SOLAR 的性能能够优于其大小数倍的 LLM
什么是深度向上扩展?
让我们了解这一切是如何开始的,以及 SOLAR 10.7B 的形成。这一切都始于一个基本模型。Upstage 选择了包含 32 个 Transformer 层的 Llama 2 作为其基础模型,因为它的开源贡献者范围更广。然后创建此基础模型的副本

然后我们得到两个基本模型。至于砝码,Upstage 采用了 Mistral 7B 的预训练砝码,因为它当时表现最好。现在,我们开始深度缩放。每个基础模型包含 32 层。从这 32 个图层中,我们删除了 m 个图层,即原始模型中的最后 m 个图层和复制版本中的前 m 个图层。每个图层总共有 24 个图层。然后我们合并这两个模型:
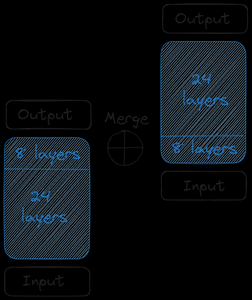
两个基本模型连接起来形成缩放模型。缩放后的模型现在包含 48 个图层。由于合并,缩放后的模型性能不佳。因此,缩放后的模型会进行预训练。这种深度缩放,然后是持续的预训练,共同构成了深度扩展 (DUS)。
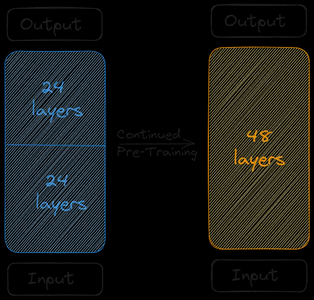
培训 SOLAR 10.7B
缩放后的模型需要进行预训练,因为合并会导致性能下降。制作者表示,通过预训练,性能迅速上升。预训练/微调包括两个阶段
第一阶段是指令微调。在这种类型的微调中,模型在数据集上进行了训练,以与指令保持一致。微调过程涉及使用流行的开源数据集,例如 Alpaca-GPT4 和 OpenOrca。该论文指出,在微调合并模型时,仅使用了数据集的一个子集。除了开源数据,Upstage 甚至用一些闭源数学数据对其进行了训练。
在第二阶段,执行对齐调整。在 Alignment Tuning 中,我们采用一个微调模型,并进一步对其进行微调,使其与人类或 GPT4 等强大的 AI 更加一致。这是通过 DPOTrainer(直接偏好优化)完成的,这是一种类似 RLHF(人类反馈的强化学习)技术。
在直接偏好优化中,我们有一个包含三列的数据集,一个提示、一个首选答案列和一个拒绝答案列。然后,这用于训练缩放模型,使其生成我们需要它生成的答案。此处使用为指令微调而训练的相同数据集。
评估和基准测试结果
Hugging Face OpenLLM 排行榜使用多个基准来评估大型语言模型 (LLM) 的功能。每个基准测试都评估LLM性能的不同方面:
● ARC(AI2 推理挑战): 该基准测试LLM回答初级科学问题的能力,提供对模型对科学概念的理解和推理的见解。
● MMLU(大规模多任务语言理解):MMLU 是一个多元化的基准测试,涵盖 57 项不同的任务,包括与基础数学、历史、法律、计算机科学等相关的问题。它评估了法学硕士处理和理解跨多个学科的信息的能力。
● 海拉赃物:为了测试法学硕士的常识推理,HellaSwag挑战模型将日常逻辑应用于各种场景,评估它们做出类似于人类思维过程的直觉判断的能力。
● 维诺格兰德:这个基准类似于 HellaSwag,侧重于常识推理,但与 HellaSwag 相比有不同的细微差别。它要求LLM表现出复杂的理解和逻辑推理水平。
● 真实质量保证: TruthfulQA 评估 LLM 提供的信息的准确性和可靠性。它包括来自科学、法律、政治等不同领域的问题,测试模型生成真实和事实响应的能力。
● GSM8K:GSM8K 专为测试数学能力而设计,包括需要逻辑推理和计算思维的多步骤数学问题,挑战 LLM 评估他们在数学中解决问题的能力。
基础 SOLAR 10.7B 型号的性能优于 Mistral 7B Instruct v0.2 型号和 Qwen 14B 型号等型号。SOLAR 10.7B 的 Instruct 版本甚至能够击败 Mistral 8x7B、Qwen 72B、Falcon 180B 和其他大型语言模型等非常大的语言模型。它领先于 ARC 和 TruthfulQA 基准测试中的所有模型
SOLAR 10.7B 入门
SOLAR 10.7B 型号可在 HuggingFace Hub 中轻松获得,以便与变压器库配合使用。甚至可以使用SOLAR 10.7B的量化模型。在本节中,我们将下载量化版本,并尝试输入具有不同任务的模型,并查看生成的输出
为了使用 SOLAR 10.7B 的量化版本进行测试,我们将使用 Python 的llama_cpp_python库,该库允许我们运行量化的大型语言模型。在这个演示中,我们将使用免费版本的 Google Colab。
下载软件包
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python
!pip3 install huggingface-hub
● CMAKE_ARGS=“-DLLAMA_CUBLAS=on” 和 FORCE_CMAKE=1 将允许llama_cpp_python在免费 colab 版本中提供的 Nvidia GPU 上工作
● 然后我们通过 pip3 安装 llama_cpp_python 包
● 我们甚至下载了huggingface-hub,我们将用它来下载量化的SOLAR 10.7B模型
要使用 SOLAR 10.7B 模型,我们需要首先下载它的量化版本。要下载它,我们将运行以下代码:
from huggingface_hub import hf_hub_download
# specifying the model name
model_name = "TheBloke/SOLAR-10.7B-Instruct-v1.0-GGUF"
# specifying the type of quantization of the model
model_file = "solar-10.7b-instruct-v1.0.Q2_K.gguf"
# download the model by specifying the model name and quantized model name
model_path = hf_hub_download(model_name, filename=model_file)
使用 Hugging Face Hub
在这里,我们与hugging_face_hub一起下载量化模型。为此,我们导入采用以下参数的hf_hub_download
● model_name:这是我们希望下载的模型类型。在这里,我们希望下载 SOLAR 10.7B Instruct GGUF 模型
● model_file:在这里,我们告诉要下载哪个量化版本。在这里,我们将下载 SOLAR 10.7B 指令的 2 位量化版本
● 然后,我们将这些参数传递给hf_hub_download,接收这些参数并下载指定的模型。下载后,返回模型下载路径
● 返回的此路径保存在 model_path 变量中
现在,我们可以通过 llama_cpp_python 库加载这个模型。加载模型的代码如下图
from llama_cpp import Llama
llm = Llama(
model_path=model_path,
n_ctx=512, # the number of i/p tokens the model can take
n_threads=8, # the number of threads to use
n_gpu_layers=110 # how many layers of the model to offload to the GPU
)
导入 Llama 类
我们从llama_cpp导入 Llama 类,该类采用以下参数
● model_path: 此变量采用存储模型的路径。我们已经从上一步中获得了路径,我们将在此处提供该路径
● n_ctx:在这里,我们给出模型的上下文长度。目前,我们为上下文长度提供了 512 个令牌
● n_threads: 在这里,我们提到了 Llama 类要使用的线程数。现在,我们通过它 8,因为我们有 4 个核心 CPU,每个核心可以同时运行 2 个线程
● n_gpu_layers:如果我们有一个正在运行的 GPU,我们会给出这个,我们这样做是因为我们正在使用免费的 colab。为此,我们传递 110,这说明我们想要将整个模型卸载到 GPU 中,并且不希望它的某些部分在系统 RAM 中运行
● 最后,我们从这个 Llama 类创建一个对象,并将其交给变量 llm
运行此代码会将 SOLAR 10.7B 量化模型加载到 GPU 上,并设置适当的上下文长度。现在,是时候对这个模型进行一些推理了。为此,我们使用以下代码
output = llm(
"### User:\nWho are you?\n\n### Assistant:", # User Prompt
max_tokens=512, # the number of output tokens generated
stop=["</s>"], # the token which tells the LLM to stop
)
print(output['choices'][0]['text']) # llm generated text
推断模型
为了推断模型,我们将以下参数传递给 LLM:
● 提示/聊天模板:这是与模型聊天所需的模板。上述模板(### User:\n{user_prompt}?\n\n### Assistant:) 适用于 SOLAR 10.7B 型号。在模板中,User 后面的句子是 User Prompt,生成将在 Assistant 之后生成
● max_tokens:这是大型语言模型在给出提示时可以输出的最大标记数。目前,我们将其限制为 512 个代币
● 停:这是停止令牌。停止令牌告诉大型语言模型它需要停止生成进一步的令牌。对于 SOLAR 10.7B,停止令牌为
运行此命令会将结果存储在输出变量中。生成的结果类似于 OpenAI API 调用。因此,我们可以通过给定的 print 语句访问生成,这类似于我们从 OpenAI 响应中访问生成的方式。生成的输出如下所示

生成的句子似乎足够好,没有出现重大语法错误。让我们通过给出以下提示来尝试模型的常识部分
output = llm(
"### User:\nHow many eggs can a monkey lay in its lifetime?\n\n### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

output = llm(
"### User:\nHow many smartphones can a human eat?\n\n### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

在这里,我们看到两个与常识相关的例子,令人惊讶的是,SOLAR 10.7B 处理得很好。大型语言模型能够通过一些有用的内容提供正确的答案。让我们尝试通过以下提示来测试模型的数学和推理能力
output = llm(
"### User:\nLook at this series: 80, 10, 70, 15, 60, ... \
What number should come next?\n\n### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

output = llm(
"### User:\nJohn runs faster than Ken. Magnus runs faster than John. \
Does Ken run faster than Magnus?\n\n### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

从给定的示例提示中,SOLAR 10.7B 产生了良好的响应。它能够正确地回答给定的数学和逻辑推理,甚至回答与常识有关的问题。总的来说,我们可以得出结论,SOLAR 10.7B 大型语言模型正在产生良好的响应
SOLAR 10.7B 与 Mixtral MoE
Mixtral 8x7B MoE 由 Mistral AI 和 Mixture of Experts 架构创建。简而言之,这个专家组合,Mistral 采用了 8 个 70 亿参数模型。这些模型中的每一个都有一些前馈网络被其他层(称为专家)所取代。因此,Mixtral 8x7B 被认为有 8 位专家。模型在输入提示中接受的每个人,都会有一个门控机制,从 8 个专家中只选择 2 个。然后,2 位专家接受此输入提示并生成最终输出令牌。因此,我们可以看到这种类型的合并涉及一些复杂性,我们必须用其他层替换前馈层,并引入一种在这些专家之间进行选择的门控机制
而 Upstage 的 SOLAR 10.7B 模型则利用了深度放大方法。在深度放大中,我们只从基础模型中删除一定数量的起始层,并从其复制版本中删除相同数量的最终层。然后,我们只需通过将一个模型堆叠在另一个模型之上来合并模型。只需几个时期的微调,合并后的模型就可以显示出性能的快速增长。在这里,我们不会用其他一些图层替换现有图层。同样在这里,我们没有门控机制。总的来说,深度放大是一种简单有效的方法,可以合并不涉及复杂性的模型。
同样比较性能,深度升级,尽管仅通过组合两个 70 亿模型,SOLAR 10.7B 能够明显优于 Mixtral 8x7B,相比之下,Mixtral 8x7B 是一个更大的模型。这证明了简单的合并方法相对于像 Mixtral of Experts 这样的复杂方法的有效性
限制和注意事项
● 超参数探索:一个关键的局限性是DUS方法中对超参数的探索不足。由于硬件限制,从基础模型的两端移除了 8 层,而没有验证此数字是否是获得最佳性能的最佳值。未来的工作旨在进行更严格的实验,并进行分析以解决这个问题。
● 计算需求: 该模型需要大量的计算资源进行训练和推理。这可能会限制其使用,主要是针对那些计算能力有限的用户。
● 训练数据中的偏差:与所有机器学习模型一样,它容易受到训练数据中存在的偏差的影响,在某些情况下可能导致结果偏差。
● 环境影响:即使是训练和操作模型所需的能源消耗也会带来环境问题,这凸显了可持续人工智能发展的重要性。
● 模型的更广泛含义:虽然该模型在遵循说明时表现出改进的性能,但它仍然需要特定于任务的微调,以便在专用应用程序中实现最佳性能。此微调过程会占用大量资源,并且可能并不总是有效。
结论
在本指南中,我们了解了Upstage AI最近发布的SOLAR 107亿参数模型。Upstage AI 采用了一种新方法来合并和缩放模型。该论文使用了一种称为深度放大的新方法,通过删除一些起始层和最终的变压器层来合并两个 Llama-2 70 亿参数模型。之后,它在开源数据集上对模型进行了微调,并在 OpenLLM 排行榜上进行了测试,获得了最高的 H6 分数并在排行榜上名列前茅。
关键要点
● SOLAR 10.7B 引入了深度放大,这是一种独特的合并方法,挑战了传统方法并展示了模型架构的进步
● 尽管 SOLAR 10.7B 拥有 107 亿个参数,但其优势优于大型型号,超过了 Mistral 7B、Qwen 14B,甚至凭借 SOLAR 10.7B Inspire 等版本在排行榜上名列前茅
● 涉及指令和对齐调整的两阶段微调过程确保了模型对不同任务的适应性,使其非常擅长遵循指令并与人类偏好保持一致
● SOLAR 10.7B在各种基准测试中表现出色,从而显示了其在从基础数学和语言理解到常识推理和真实性评估等任务方面的能力
● SOLAR 10.7B 可在 HuggingFace Hub 上轻松获得,为开发人员和研究人员提供高效且可用的语言处理应用程序工具
● 可以使用用于微调大型语言模型的常规方法对模型进行微调。例如,您可以利用 Hugging Face 的 Supervised Fine-Tune Trainer (SFTrainer) 来微调 SOLAR 10.7B 模型。
常见问题解答
问题1.什么是 SOLAR 10.7B,它如何在 LLM 世界中脱颖而出?
答:SOLAR 10.7B 是 Upstage AI 的 107 亿参数模型,采用了一种称为深度放大的独特合并技术。它通过超越大型 LLM 和展示合并模型的进步而脱颖而出。
问题2.深度缩放如何工作?
答:深度缩放涉及两个基本模型。该过程涉及通过将这两个基本模型堆叠在一起来直接合并它们。在合并之前,将删除一个模型的初始层和另一个模型的最终层。
问题3.SOLAR 10.7B是如何训练的?
答:SOLAR 10.7B经历了两个阶段的预训练过程。指令微调涉及在强调指令遵循的数据集上训练模型。对齐调整使用一种称为直接偏好优化 (DPO) 的技术来优化模型与人类偏好的对齐。
问题4.SOLAR 10.7B 在基准评估中表现如何?
答:SOLAR 10.7B 在各种基准测试中表现出色,包括 ARC(AI2 推理挑战)、MMLU(大规模多任务语言理解)、HellaSwag、Winogrande、TruthfulQA 和 GSM8K。它获得了高分,展示了其在处理不同语言任务方面的多功能性。
问题5.SOLAR 10.7B 与 Mistral 7B 和 Qwen 14B 等其他大型型号相比如何?
答:SOLAR 10.7B 超越了 Mistral 7B 和 Qwen 14B 等型号,尽管参数较少,但性能卓越。在各种基准测试中,指示版本甚至可以与非常大的型号竞争并超越它们,包括 Mistral 8x7B 和 Qwen 72B。
本文中显示的媒体不归 Analytics Vidhya 所有,由作者自行决定使用。
文章来源:https://www.analyticsvidhya.com/blog/2024/01/solar-10-7b-comparing-its-performance-to-other-notable-llms/

















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









