






人类是复杂的存在,我们的沟通方式是多层次的,心理学家设计了许多种测试来衡量我们从彼此的互动中推断理解的能力,而AI 模型在这些测试中表现得越来越好。最新发表在《自然 • 人类行为》杂志上的研究显示,一些大型语言模型(LLMs)在执行旨在测试追踪人们心理状态能力的任务时,表现与人类相当,甚至在某些情况下优于人类,这种能力被称为“心理理论”。

理论上,人工智能模型越擅长模仿人类,它们在与我们互动时就显得越有用和富有同情心。上周,OpenAI和谷歌都宣布了功能更强大的人工智能助手;GPT-4o和Astra被设计为能够比其前辈提供更流畅、更自然的回应。但我们必须避免陷入认为它们的能力像人类一样的陷阱,即使它们看起来是这样。

心理理论是情感和社会智力的一个标志,使我们能够推断他人的意图,进行互动并彼此产生共鸣。大多数儿童在三到五岁之间习得这类技能。
研究人员测试了两大家族的大型语言模型:OpenAI的GPT-3.5和GPT-4,以及Meta的三种版本的Llama,任务旨在测试人类的心理理论,包括识别错误信念、识别社交失礼行为以及理解隐含而非直接表达的内容。他们还测试了1907名人类参与者,以比较两组得分。
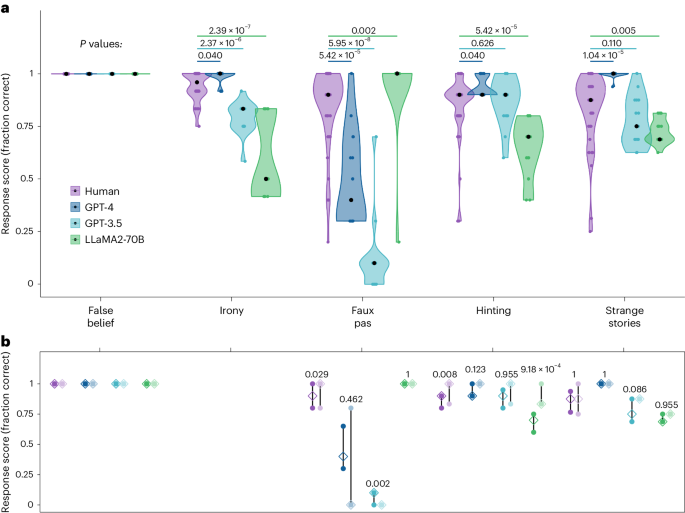
人工智能模型在独立的对话中分别进行了15次每项测试,以便它们将每个请求视为独立的,并且它们的回应按照用于人类的同样方式进行评分。然后研究人员测试了人类志愿者,并比较了两组得分。
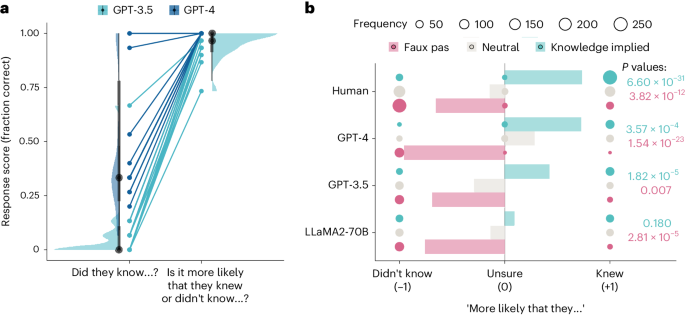
然而,Llama 2是测试的三个Meta模型中最大的一个,在识别社交失礼场景时表现优于人类,而GPT则一致提供了错误的回应。作者认为这是由于GPT普遍避免对意见做出结论,因为这些模型大多回应说他们没有足够的信息来回答。
“可以肯定的是,这些模型并没有展示出人类的心理理论,”他说,“但我们的确证明了它们在此类推断上的能力,即对角色或他人的心理状态进行思考和推理。”

归根结底,我们仍然不了解大型语言模型(LLMs)是如何工作的。像这样的研究可以帮助我们加深对这些模型能做什么和不能做什么的理解,哈佛大学的认知科学家托默·乌尔曼(Tomer Ullman)说,他并没有参与这个项目。但重要的是要记住,当我们设置像这样的LLMs测试时,我们真正在测量的是什么。如果一个人工智能在设计用来测量心理理论的测试中超越了人类,这并不意味着人工智能具有心理理论。
"我不是反对基准测试,但我是那些担心我们目前使用基准测试的方式可能已经到达了效用极限的人群中的一员,"乌尔曼说。“无论这个模型是如何学会通过基准测试的,我不认为它是以一种类似人类的方式。”



















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









