






引言
大型语言模型(LLM) 正日益成为理解和生成人类语言的强大工具。这些模型在不同的自然语言处理任务上取得了最先进的结果,包括文本摘要、机器翻译、问答和对话生成。法学硕士甚至在更专业的领域显示出前景,如医疗保健、金融和法律。
谷歌一直处于LLM研究和开发的最前沿,发布了一系列开放模型,这些模型突破了这项技术的可能性。这些模型包括 BERT、T5 和 T5X,它们已被研究人员和从业者广泛采用。在本指南中,我们将介绍 Gemma,这是由 Google 开发的一个新的开放 LLM 系列。
学习目标
- 了解 Gemma 的架构和主要功能。
- 探索 Gemma 的培训过程和技巧。
- 评估 Gemma 在 NLP 基准测试中的表现。
- 了解如何使用 Gemma 执行推理任务。
- 认识到负责任部署对 Gemma 的重要性。
本文作为数据科学博客马拉松的一部分发表。
什么是 Gemma?
Gemma 是一个基于 Google Gemini 模型的开放语言模型系列,在多达 6T 个文本标记上进行训练。这些被认为是双子座模型的较轻版本。Gemma 系列由两种规模组成:用于在 GPU 和 TPU 上高效部署的 70 亿参数模型,以及用于 CPU 和设备端应用程序的 20 亿参数模型。Gemma 在文本领域表现出强大的通才能力以及最先进的大规模理解和推理技能。与不同领域(包括问答、常识推理、数学和科学以及编码)中其他类似或更大规模的开放模型相比,它实现了更好的性能。对于这两个模型,谷歌团队都发布了预训练的微调检查点和用于推理和服务的开源代码库。

Gemma 以分布式方式建立在序列模型、转换器、深度学习和大规模训练的最新进展之上。它延续了 Google 继 Word2Vec、Transformer、BERT、T5 和 T5X 之后发布开放模型和生态系统的历史。负责任地发布 Gemma 旨在提高前沿模型的安全性,提供公平使用该技术的机会,为对当前技术进行严格评估和分析提供途径,并促进未来创新的发展。但是,在部署或使用 Gemma 之前,针对每个用例进行全面的安全测试至关重要。
Gemma – 模型架构
Gemma 遵循 2017 年推出的仅解码器转换器的架构。Gamma 2B 和 7B 型号的词汇量均为 256k。这两个模型的上下文长度甚至为 8192 个令牌。Gemma 甚至包括变压器架构的最新进展,包括:
多查询注意:7B 模型使用多头注意力,而 2B 模型实现多查询注意力(num_kv_heads=1)。这种选择是基于通过消融研究在每个量表上显示的性能改进。
RoPE嵌入: 两种模型都没有使用绝对位置嵌入,而是在每一层中都采用旋转位置嵌入。此外,在输入和输出之间嵌入共享可最大限度地减小模型大小。
GeGLU 激活:常规的 ReLU 激活功能被 GeGLU 激活功能所取代,性能良好。
归一化器位置:Gemma 偏离了 goto 的做法,使用 RMSNorm 作为归一化方法,对每个转换器子层的输入和输出进行归一化。
Gemma 是如何训练的?
Gemma 2B 和 7B 模型分别在 2T 和 6T 代币上进行训练,这些代币主要来自 Web 文档、数学和代码。与包含多模态元素并针对多语言任务进行优化的 Gemini 模型不同,Gemma 模型专注于处理英语文本。训练数据经过仔细过滤过程,以删除不需要或不安全的内容,包括个人信息和敏感数据。这种过滤涉及启发式方法和基于模型的分类器,以确保数据集的质量和安全性。
Gemma 2B 和 7B 模型进行了监督微调 (SFT) 和从人类反馈中强化学习 (RLHF),以进一步完善其性能。监督微调涉及纯文本、纯英语合成和人工生成的提示响应对的混合。根据基于 LM 的并排评估精心选择用于微调的数据组合,并设计了不同的提示集,以突出特定功能,例如指令遵循、事实性、创造力和安全性。
甚至,合成数据也经历了几个过滤阶段,以删除包含个人信息或有毒输出的示例,遵循 Gemini 建立的方法,在不影响安全性的情况下提高模型性能。最后,来自人类反馈的强化学习涉及从人类评分者那里收集成对的偏好,并在Bradley-Terry模型下训练奖励函数。然后,使用一种 REINFORCE 类型优化此功能,以进一步优化模型的性能并缓解奖励黑客等潜在问题。
另请观看此视频 Google Gemma 教程和如何使用:https://www.youtube.com/watch?v=W9Qs2RVXjXQ
基准和性能指标
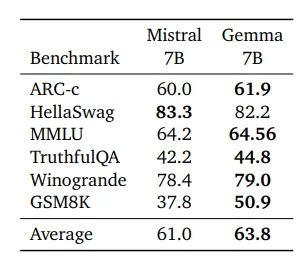
从结果来看,Gemma 在六个基准测试中的五个上都优于 Mistral,唯一的例外是 HellaSwag,它们获得了相似的准确性。这种优势在 ARC-c 和 TruthfulQA 等任务中很明显,其中 Gemma 在准确率和 F1 分数方面分别超过米斯特拉尔近 2% 和 2.5%。即使在 MMLU 上,困惑度分数越低越好,Gemma 的困惑度也明显较低,表明对语言模式的掌握程度更好。这些结果巩固了 Gemma 作为强大语言模型的地位,能够以良好的准确性和效率处理复杂的 NLP 任务。
Gemma 入门
在本节中,我们将开始使用 Gemma。我们将与 Google Colab 合作,因为它带有免费的 GPU。在开始之前,我们需要接受 Google 的条款和条件才能下载模型。
第 1 步:打开 Gemma
单击此链接转到 HuggingFace 上的 Gemma。您将看到如下内容:
第 2 步:单击“确认许可证”
如果单击“确认许可证”,则会看到如下页面。
单击“授权”。完成后,我们现在可以下载模型了。在此之前,让我们生成一个新的 HuggingFace 代币。为此,您可以转到 HuggingFace 设置并生成一个新的令牌,这个令牌将很有用,因为我们需要它在 Google Colab 内部授权才能下载 Google Gemma 大型语言模型。
步骤 3:安装库
首先,我们首先需要安装以下库。
!pip install -U accelerate bitsandbytes transformers huggingface_hub
- 加速: 支持分布式训练和混合精度训练,以实现更快、更高效的模型训练。加速库甚至有助于更快地推理大型语言模型。 位沙字节:
- 允许将模型权重量化为 4 位或 8 位精度,从而减少内存占用和计算要求。由于我们正在处理一个 70 亿参数模型,该模型需要大约
- 30-40GB 的 GPU VRAM,因此我们需要对其进行量化以适应 Colab GPU。
- 变形金刚:为自然语言处理任务提供预训练的语言模型、分词器和训练工具。我们使用这个库来下载 Gemma 模型并开始推断它。
- huggingface_hub:便于访问 Hugging FaceHub,这是一个用于共享和查看语言模型和数据集的平台。我们需要这个库来登录 huggingface,以便我们可以验证我们是否被授权下载
Google Gemma 大型语言模型
安装后的 -U 选项表示我们正在获取所有库的最新更新版本。
第 4 步:键入重要命令
现在,键入以下命令
!huggingface-cli login
上面的命令会要求你提供HuggingFace令牌,我们可以从HuggingFace网站获得。提供此令牌并按回车按钮,您将收到登录成功消息。现在让我们继续编码
# Import necessary classes for model loading and quantization
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
# Configure model quantization to 4-bit for memory and computation efficiency
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
# Load the tokenizer for the Gemma 7B Italian model
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
# Load the Gemma 7B Italian model itself, with 4-bit quantization
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b-it",
quantization_config=quantization_config)
- 自动分词器: 此类动态加载与给定模型关联的预训练分词器,确保兼容性并避免手动配置。
- AutoModelForCausalLM:与分词器类似,此类根据提供的模型标识符自动加载预训练的因果语言模型体系结构。
- quantization_config =BitsAndBytesConfig(load_in_4bit=True):此行创建一个用于量化的配置对象,告诉模型的权重应以 4位精度而不是原始的 32 位精度推送。这在很大程度上减少了内存消耗,并可能加快计算速度,使模型在资源受限的环境中更加高效。
- tokenizer =AutoTokenizer.from_pretrained(“google/gemma-7b-it”):此行加载专为“google/gemma-7b-it”模型设计的预训练分词器。此分词器知道如何将文本分解为模型可以理解和处理的单独标记。
- 模型 = AutoModelForCausalLM.from_pretrained(“google/gemma-7b-it”,quantization_config=quantization_config):此行加载实际的“google/gemma-7b-it”模型,但添加了quantization_config对象的关键内容。这确保了模型权重以我们之前讨论过的4 位格式创建,从而增加了量化的好处。
我们的 Gemma 大型语言模型被下载,转换为 4 位量化模型,并加载到 GPU 中。
第 5 步:推理模型
现在让我们尝试推理模型。
# Define input text:
input_text = "List the key points about Responsible AI"
# Tokenize the input text:
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
# Generate text using the model:
outputs = model.generate(
**input_ids, # Pass tokenized input as keyword argument
max_length=512, # Limit output length to 512 tokens
)
# Decode the generated text:
print(tokenizer.decode(outputs[0]))
- 定义输入文本: 该代码首先将提示“列出负责任 AI 的关键方面”分配给 input_text 变量。
- 标记化输入:与下载的模型关联的分词器对象用于将文本转换为模型可以理解的数字标记。return_tensors=“pt” 行讲述了如何转换为PyTorch 张量以实现高效的 GPU 处理。然后,如果可用,则使用 to(“cuda”) 将生成的令牌 ID 张量移动到 GPU。
- 生成文本: model.generate 函数使用标记化输入 (input_ids) 调用,最大输出长度为 512个标记。这将指示模型根据提供的提示生成文本,并遵守给定的长度限制。
- 解码和转换: 生成的文本以令牌 ID 序列的格式表示,使用tokenizer.decode 函数解码回人类可读的文本。最后,将解码后的文本打印出来。
第 6 步:生成响应
运行代码已生成以下响应

该模型已对提供的查询生成了公平的响应。它强调了创建负责任的 AI 的所有关键方面。这确实是对所问问题的相关且准确的答案。让我们通过问一个常识性问题来了解人工智能。
input_text = "How many eggs can a Whale lay in its lifetime?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids,max_length=512)
print(tokenizer.decode(outputs[0]))

input_text = "How many smartphones can a human eat ?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids,max_length=512)
print(tokenizer.decode(outputs[0]))

目前为止,一切都好。该模型具有良好的常识能力。它能够识别句子中的错误并输出相同的内容,如上图所示。让我们试着问一些数学问题。
input_text = "I have 3 apples and 2 oranges. I ate 2 organes. How many apples do I have?"
input_ids = tokenizer(input_text, return_tensors="pt").to('cuda')
outputs = model.generate(**input_ids,max_new_tokens=512)
print(tokenizer.decode(outputs[0]))
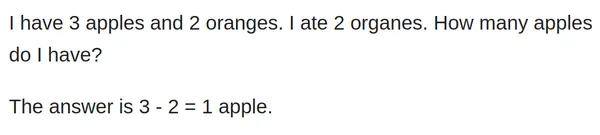
似乎该模型很难回答这个简单棘手的数学问题。让我们在这里尝试做一些提示工程。让我们在提示符中添加其他信息,并按如下方式运行它:
input_text = "I have 3 apples and 2 oranges. \
I ate 2 oranges. How many apples do I have? \
Think Step by Step. For each step, re-evaluate your answer"
input_ids = tokenizer(input_text, return_tensors="pt").to('cuda')
outputs = model.generate(**input_ids,max_new_tokens=512)
print(tokenizer.decode(outputs[0]))
哇,在提示中进行了简单的调整,模型正确回答了。它开始循序渐进地思考,这是一步一步来的。对于每一步,它都会开始重新评估它的答案,无论它是对还是错。最后,它已经找到了正确的答案。让我们尝试让模型用 Python 编写一个简单的 Hello World 程序。
input_text = "Write a hello world program"
input_ids = tokenizer(input_text, return_tensors="pt").to('cuda')
outputs = model.generate(**input_ids,max_new_tokens=512)
print(tokenizer.decode(outputs[0]))

结论
Gemma 是 Google 开放语言模型套件的最新成员,展示了自然语言处理领域的进步。凭借其强大的通才能力和最先进的理解和推理技能,Gemma 在问答、常识推理、数学和科学以及编码任务等不同领域的表现优于其他开放模型。Gemma 建立在序列模型、转换器和大规模训练技术的最新进展之上,提供了更高的性能和效率,使其成为研究人员和从业人员的强大工具。但是,在将 Gemma 集成到生产系统之前,必须针对每个问题进行负责任的部署和全面的安全测试。
关键要点
- Gemma 是 Google 开发的一系列开放语言模型,基于 Gemini 模型,但规模更轻。 它有两种尺寸:用于 GPU 和 TPU
- 部署的 70 亿参数模型,以及用于 CPU 和设备端应用程序的 20 亿参数模型。 Gemma
- 表现出强大的通才能力,在问答、常识推理、数学和科学以及编码等不同领域表现出色。 该模型架构包括多查询注意力、RoPE 嵌入、GeGLU
- 激活和用于规范化的 RMSNorm 等改进。 Gemma 的训练数据经过过滤以确保质量,模型经过监督微调和从人类反馈中强化学习。
- 性能基准测试表明 Gemma 优于其他模型,主要是在 ARC-c 和 TruthfulQA 等任务中。 开始使用 Gemma
- 包括安装必要的库、登录 Hugging Face 以及加载模型进行推理。 Gemma
- 在生成文本、回答问题甚至编写简单的编程任务方面表现出令人印象深刻的能力。
来源:https://www.analyticsvidhya.com/blog/2024/02/how-to-use-gemma-llm/

















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









