







 本文介绍了R-CNN系列的目标检测方法,包括R-CNN、Fast R-CNN和Faster R-CNN的工作原理及其优缺点。重点讨论了Faster R-CNN的端到端训练和RPN网络在提高检测速度和精度上的贡献,并分享了使用Faster R-CNN基于VGG16预训练模型在交通标志检测任务上的训练经验。
本文介绍了R-CNN系列的目标检测方法,包括R-CNN、Fast R-CNN和Faster R-CNN的工作原理及其优缺点。重点讨论了Faster R-CNN的端到端训练和RPN网络在提高检测速度和精度上的贡献,并分享了使用Faster R-CNN基于VGG16预训练模型在交通标志检测任务上的训练经验。
R-CNN,Fast-RCNN,Faster-RCNN都是基于候选区域(region proposal)的识别网络,在图片上寻找可能是目标存在的区域,对每个区域进行分类和检测框回归,实现目标检测。
R-CNN:
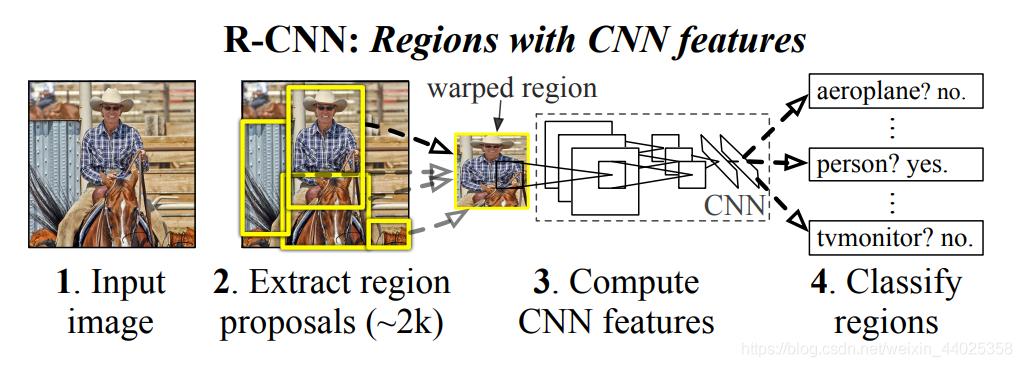
①对输入图片,使用Seletive Search算法,产生2000个类别独立的候选区域(region proposal) 。
②用卷积神经网络对每个候选区域提取长度相同的特征向量(由于SS产生的候选区域大小存在差异,在输入神经网络之前,需要将所有候选区域变换到227×227) 。
③用SVM对每个候选区域分类 ,bbox regression对边界框修正。
缺点:
①分步训练,让不了解深度学习的人很难进行训练。
②提取得到的特征数据需要写入硬盘,以供SVM分类和边界框回归训练使用,造成极大的内存和时间耗费。
③显而易见,网络的识别速度很慢。
Fast-RCNN:
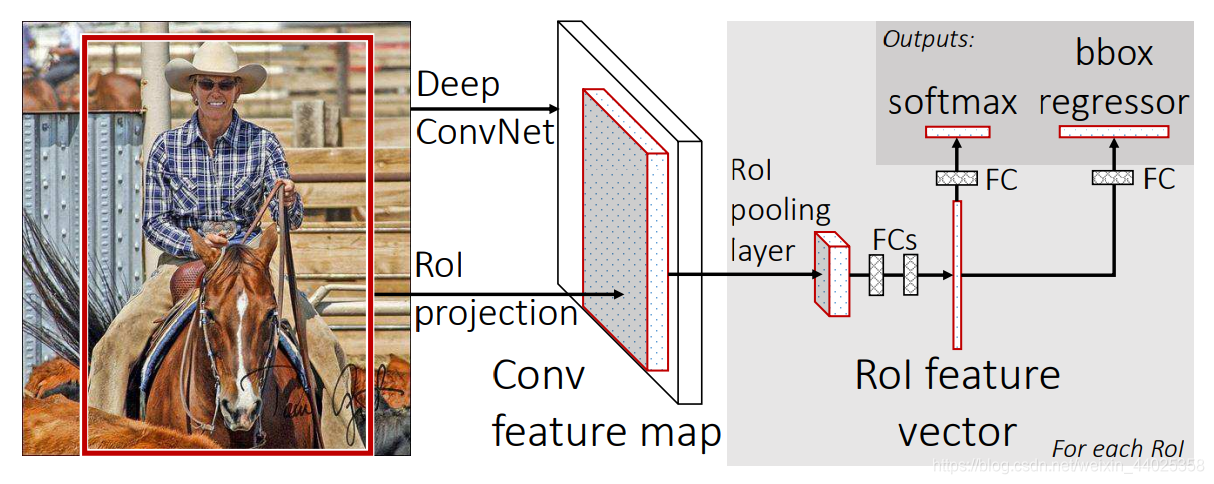
①对输入图片,使用Seletive Search算法,产生2000个类别独立的候选区域 。
②用深度神经网络对整个图片进行卷积,得到feature map,将候选区域映射到feature map上(文章
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









