





目录
1、语音识别基础与发展
1.1 语音识别基础
语音识别全称为“自动语音识别”,Automatic Speech Recognition (ASR), 一般是指将语音序列转换成文本序列。语音识别最终是统计优化问题,给定输入序列O={O1,…,On},寻找最可能的词序列W={W1,…,Wm},即寻找使得概率P(W|O)最大的词序列。用贝叶斯公式表示为:
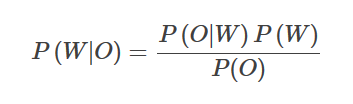
其中P(O|W) 叫做声学模型,描述的是给定词W时声学观察为O的概率;P(W)叫做语言模型,负责计算某个词序列的概率;P(O)是观察序列的概率,是固定的,是固定的,所以只看分母部分即可。
语音选择的基本单位是帧(Frame),一帧数据是由一小段语音经过ASR前端的声学特征提取模块产生的,整段语音就可以整理为以帧为单位的向量组。每帧的维度固定不变,但跨度可调,以适应不同的文本单位,比如音素、字、词、句子。
大多数语音识别的研究都是分别求取声学和语言模型,并把很多精力放在声学模型的改进上。但后来,基于深度学习和大数据的端到端(End-to-End)方法发展起来,能将声学和语言模型融为一体,直接计算P(W|O)。
1.2 语音识别的发展
-
传统机器学习,基于统计的GMM-HMM,其中HMM (隐马尔可夫模型,Hidden Markov Model)用来描述信号动态特性(即语音信号相邻帧间的相关性),GMM(高斯混合模型,Gaussian Mixed Model)用来描述HMM每个状态的静态特性(即HMM每个状态下语音帧的分布规律);
-
与深度学习结合,DNN-RNN、DNN-HMM,可引入LSTM(长短期记忆网络,Long Short-Term Memory),DNN(深度学习网络,Deep Neural Networks),RNN(循环神经网络,Recurrent Neural Network);
-
迁移学习(Transfer learning)算法、以及注意力(Attention)机制的基于语音频谱图的CNN(卷积神经网络,Convolutional Neural Network)模型的兴起。
2、语音识别方法
语音识别系统在长久的发展中形成了完整的流程(从前端语音信号处理,到声学模型和语言模型的训练,再到后端的解码),而深度学习方法较多地作用于声学模型和语言模型部分(或者端对端模型)。其中,前端的语音信号处理我们在task3中有所涉及,这里就不再赘述这部分了。
接下来我们将分别从“声学模型”、“语言模型”、“端到端模型”等模块简要介绍语音识别的基本实现方法。
2.1 声学模型
在今天的主流语音识别系统中,声学模型是一个混合(hybrid)模型,它包括用于序列跳转的隐马尔可夫模型(HMM)和根据当前帧来预测状态的深度神经网络。
2.1.1 HMM
隐马尔可夫模型(Hidden Markov Model,HMM)是用于建模离散时间序列的常见模型,它在语音识别中已经使用了几十年了。
HMM 涉及的主要内容有,两组序列(隐含状态和观测值),三种概率(初始状态概率,状态转移概率,发射概率),和三个基本问题(产生观测序列的概率计算,最佳隐含状态序列的解码,模型本身的训练),以及这三个问题的常用算法(前向或后向算法,Viterbi 算法,EM 算法)。语音识别的最终应用对应的是解码问题,而对语音识别系统的评估、使用也叫做解码(Decoding)。
在研究HMM之前,我们先简单的回顾一下马尔科夫链。马尔科夫链是建模随机过程的一种方法,用天气来举个简单点的例子就是,今天是否下雨和前一天是否下雨有关。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NqcVQplW-1619093186194)(attachment:76e19b42-4960-49cf-9cf3-b793f5f86893.png)]](https://img-blog.csdnimg.cn/20210422201728471.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDAyNzg2NA==,size_16,color_FFFFFF,t_70)
隐马尔可夫模型相当于是马尔可夫链的拓展,比如有时候我们在山洞里不能直观地知道前一天是否下雨,但我们知道前一天的湿度和今天的湿度等其他信息,通过这些已知的信息来推导未知的数据就是隐马尔可夫模型。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dMCU8zJJ-1619093186196)(attachment:369d0595-4393-42b1-8f8f-1f371009f07b.png)]](https://img-blog.csdnimg.cn/20210422201721316.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDAyNzg2NA==,size_16,color_FFFFFF,t_70)
放在语音识别里就是,我们能知道语音的频谱,但不知道之前的频谱代表什么意思的,就可以通过历史的频谱,来推导新的频谱的对应结果。
2.1.2 GMM
GMM(高斯混合模型,Gaussian Mixed Model),主要就是通过GMM来求得某一音素(phoneme)的概率。
在语音识别中,HMM用于建模subword级别(比如音素)的声学建模。通常我们使用3个状态的HMM来建模一个音素,它们分别表示音素的开始、中间和结束。每个状态可以跳转到自己也可以跳转到下一个状态(但是不能往后跳转)

而一个词是有一个或者多个音素组成,因此它的HMM由组成它的音素的HMM拼接起来。
因此一个高质量的发音词典非常重要,所谓的发音词典就是定义每个词由哪些音素组成。在深度学习流行之前,HMM的发射概率通常使用GMM模型来建模:
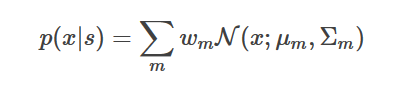
这里N(x;μm,Σm)是一个高斯分布,而wm是混合的权重,它满足∑mwm=1 。因此,每个状态都对应它自己的GMM。我们可以使用Baum-Welch在估计HMM跳转概率的同时估计所有GMM的参数,包括均值、协方差矩阵和混合的权重。
现在流行的语音系统不再使用GMM而是使用一个神经网络模型模型,它的输入是当前帧的特征向量(可能还要加上前后一些帧的特征),输出是每个音素的概率。比如我们有40个音素,每个音素有3个状态,那么神经网络的输出是40x3=120。
这种声学模型叫做”混合”系统或者成为HMM-DNN系统,这有别于之前的HMM-GMM模型,但是HMM模型还在被使用。
2.2 语言模型
语言模型要解决的问题是如何计算 P(W),常用的方法基于 n 元语法(n-gram Grammar)或RNN。
2.2.1 n-gram
语言模型是典型的的自回归模型(Autoregressive Model),给定词序列W=[w1,w2,…,wm],其概率表示为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nPdkLbl0-1619093186205)(attachment:0b41d6b9-bf29-4fac-baba-ebf6e8e91bcd.png)]](https://img-blog.csdnimg.cn/20210422201503927.png)
它假设当前词的出现概率只与该词之前n-1个词相关,该式中各因子需要从一定数量的文本语料中统计计算出来,此过程即是语言模型的训练过程,且需要求出所有可能的P(wi|wi−n+1, wi−n+2, …, wi−1),计算方法可以简化为计算语料中相应词串出现的比例关系,即:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9audNSEH-1619093186206)(attachment:348f55bf-4625-47bc-a6c6-15fc19091c9b.png)]](https://img-blog.csdnimg.cn/20210422201427861.png)
其中count表示词串在语料中出现的次数,由于训练语料不足或词串不常见等因素导致有些词串未在训练文本中出现,此时可以使用不同的平滑(Smoothing)算法进行处理。
2.2.2 RNN语言模型
因为当前的结果依赖于之前的信息,因此可以天然地使用单向循环神经网络进行建模。单向循环神经网络训练的常规做法是,利用句子中的历史词汇来预测当前词,下图展示了RNN 语言模型的基本结构,其输出层往往较宽,每个输出节点对应一个词,整个输出层涵盖了语言模型所使用的词表,故其训练本质上也是分类器训练,每个节点的输出表示产生该节点词的概率,即 P(wi|w1, w2, …,wi−1),故可以求出 P(W)。前向非循环神经网络也可以用于语言模型,此时其历史信息是固定长度的,同于n-gram。
2.3 解码器
我们的最终目的是选择使得 P(W|O) = P(O|W)P(W) 最大的 W ,所以解码本质上是一个搜索问题,并可借助加权有限状态转换器(Weighted Finite State Transducer,WFST) 统一进行最优路径搜索.
2.4 基于端到端学习的方法
由于语音与文本的多变性,起初我们否决了从语音到文本一步到位的映射思路。但今天再回过头来看这个问题。假设输入是一整段语音(以帧为基本单位),输出是对应的文本(以音素或字词为基本单位),两端数据都处理成规整的数学表示形式了,只要数据是足够的,选的算法是合适的,兴许能训练出一个好的端对端模型,于是所有的压力就转移到模型上来了,怎样选择一个内在强大的模型是关键。深度学习方法是端对端学习的主要途径。
端对端学习需要考虑的首要问题也是输入输出的不定长问题。我们在这里简要介绍两种。
-
CTC (连接时序分类,Connectionist temporal classification),
CTC 方法早在2006年就已提出并应用于语音识别,但真正大放异彩却是在2012年之后,随之各种CTC研究铺展开来。CTC仅仅只是一种损失函数,简而言之,输入是一个序列,输出也是一个序列,该损失函数欲使得模型输出的序列尽可能拟合目标序列。回忆语音识别系统的基本出发点,即求W∗ = argmaxw P(W|O),其中 O= [O1, O2, O3, …]表示语音序列,W= [w1, w2, w3, …] 表示可能的文本序列,而端对端模型zh本身就是 P(W|O ),则CTC 的目标就是直接优化 P(W|O ),使其尽可能精确。之前需要语音对齐到帧,用这个就可以不需要对齐,它只会关心预测输出的序列是否和真实的序列是否接近(相同)。 -
Attention
Attention模型的基本表述可以这样理解成: 当我们人在看一样东西的时候,我们当前时刻关注的一定是我们当前正在看的这样东西的某一地方,换句话说,当我们目光移到别处时,注意力随着目光的移动也在转移。
Attention机制的实现是通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。














 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









