







Task01 绪论与深度学习概述、数学基础
参考链接: https://datawhalechina.github.io/unusual-deep-learning/#/README
1 绪论与深度学习概述
1.1人工智能
人工智能是一门新兴的交叉学科,关于人工智能的定义,有很多人给出,例如约翰麦卡锡(2007)、 Andreas Kaplan,汉化版的定义是由全国信息安全标准化技术委员会给出,具体内容是:人工智能,是利用数字计算机或者数字计算机控制的机器模拟、延伸 和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理 论、方法、技术及应用系统。
人工智能的分类:
强人工智能:一种被认为是有自主意识的智能机器,能够真正能推理和解决一些现实问题。
弱人工智能:一种表面上看起来像是智能、但不是真正拥有智能和自主意识的机器,这种机器被认为不能真正的进行推理和解决现实的一些问题。
超级人工智能:机器的智能彻底超过了人类,未来(future)?
1.2机器学习
机器学习定义 让计算机具有像人一样的学习和思考能力的技术的总称。具体来说是从已知数据中获得规律,并利用规律对未知数据进行预测的技术。
机器学习分类:
有监督学习(SupervisedLearning):有老师(环境)的情况下, 学生(计算机)从老师(环境)那里获得对错指示、最终答案的学习方法。(概括:跟学师评)
无监督学习(UnsupervisedLearning):没有老师(环境)的情况下,学生(计算机)自学的过程,一般使用一些既定标准进行评价。(概括:自学标评)
强化学习(ReinforcementLearning):没有老师(环境)的情况 下,学生(计算机)对问题答案进行自我评价的方法。(概括:自学自评)
1.3深度学习
深度学习定义: 一般是指通过训练多层网络结构对未知数据进行分类或回归
深度学习分类:
有监督学习方法:深度前馈网络、卷积神经网络、循环神经网络等;
无监督学习方法:深度信念网、深度玻尔兹曼机,深度自编码器等。
起源与发展
第1阶段(1943-1969):提出MP神经元模型、感知器(Perceptron)、ADLINE神经网络,弊端是感知器只能解决简单的线性分类任务,无法解决XOR简单分类问题。
第2阶段(1980-1989):提出Hopfiled神经网络、误差反向传播算法(Error Back Propagation, BP)、CNN(Convolutional Neural Networks,CNN)。
第3阶段(2006-):提出深度学习概念,使用无监督学习方法逐层训练算法,再使用有监督的反向传播算法进行调优,CNN中引入ReLU激活函数,构建一个深层 神经网络——DNN,这些技术的发展应用在语音识别、图像识别取得了巨大的成功。
1.4主要应用
图像处理领域:
图像分类(物体识别)、整幅图像的分类或识别
物体检测、检测图像中物体的位置进而识别物体
图像分割、对图像中的特定物体按边缘进行分割
图像回归、预测图像中物体组成部分的坐标
语音领域:
语音识别、语音识别转换文字
声纹识别、通过声音确定是某个人
语音合成、通过文字合成特定人的声音
NLP领域:
语言模型、根据现有的词预测下一个词
情感分析、分析文本中表达的情感(正负向、正负中或多态度类型)
神经机器翻译、基于统计语言模型的多语种互译
机器阅读理解、阅读文本,回答问题
自然语言推理、根据一句话(前提)推理出另一句话(结论)
2 数学基础
2.1 矩阵基本知识
矩阵:一个二维数组,其中的每一个元素一般由两个索引来确定一般用大写变量(例如 A)表示,m行n列的实数矩阵,记做A∈R m×n。
矩阵的秩(Rank):矩阵列向量中的极大线性无关组的数目,记作矩阵的列秩,同样可以定义行秩。行秩=列秩=矩阵的秩,通常记作rank(A)。
矩阵的逆:
(1)若矩阵A为方阵(行数等于列数),当 rank(An×n)<n时,称A为奇异矩阵(又叫做不可逆矩阵);
(2)若矩阵A为方阵(行数等于列数),当 rank(An×n)=n时,称A为非奇异矩阵(又叫做可逆矩阵)。
矩阵的广义逆矩阵
(1)如果矩阵不为方阵或者是奇异矩阵,不存在逆矩阵,但是可以计算其广义逆矩阵或者伪逆矩阵;
(2)对于矩阵A,如果存在矩阵 B 使得 ABA=A,则称 B 为 A 的广义逆矩阵。
张量(Tensor): 是矢量概念的推广,用来表示在一些矢量(又叫向量,有大小、有方向)、标量和其它张量之间的线性关系的多线性函数。标量(有大小、无方向)是0阶张量,矩阵是二阶张量,三维及以上数组一般称为张量。

2.2 矩阵的分解
机器学习中常见的矩阵分解有特征分解和奇异值分解。矩阵的分解离不开矩阵的特征值和特征向量的理解,如下,
(1)若矩阵 A 为方阵,则存在非零向量 x 和常数 λ 满足 Ax= λx,则称λ 为矩阵 A 的一个特征值,x 为矩阵 A 关于 λ 的特征向量。
(2)An×n的矩阵具有 n 个特征值,λ1 ≤ λ2 ≤ ⋯ ≤ λn其对应的n个特征向量为 𝒖1,𝒖2, ⋯ ,𝒖𝑛
(3)矩阵的迹(trace)和行列式(determinant)的值分别为
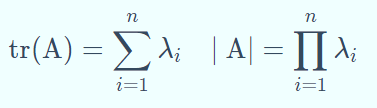
矩阵特征分解:An×n的矩阵具有 n 个不同的特征值,那么矩阵A可以分解为 A =UΣUT .
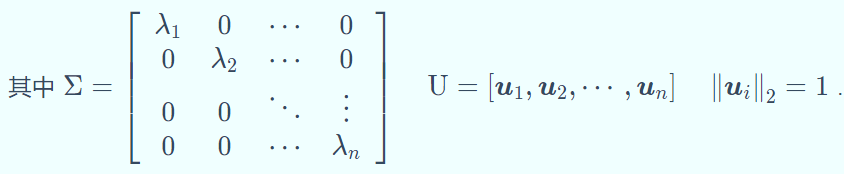
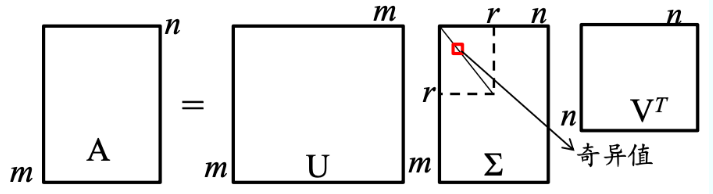
奇异值分解:对于任意矩阵 Am×n,存在正交矩阵 Um×m和 Vn×n,使其满足 A =UΣVT UTU=VTV=I,则称上式为矩阵 A 的特征分解。
2.3 概率统计
随机变量(Random variable)是随机事件的数量表现,随机事件数量化的好处是可以用数学分析的方法来研究随机现象。
随机变量(Random variable)可以是离散的或者连续的,离散随机变量是指拥有有限个或者可列无限多个状态的随机变量,连续随机变量是指变量值不可随机列举出来的随机变量,一般取实数值。
随机变量(Random variable)通常用概率分布来指定它的每个状态的可能性。
常见的概率分布
(1)伯努利分布:只有俩种结果的单次随机实验,又叫做0-1分布,表达式为P∗(∗X=1)=p,P(X=0)=1−p 。
(2)二项分布:二项分布即重复n次伯努利试验,各试验之间都相互独立。表达式为P(X=k)=Ckn pk (1−p)n−k 。
(3)均匀分布:又称矩形分布,在给定长度间隔[a,b]内的分布概率是等可能的,均匀分布由参数a,b定义,概率密度函数为:
p(x)= 1/(b−a) , a<x<b
(4)高斯分布:又称正态分布(normal),是实数中最常用的分布,由均值μ和标准差σ决定其分布,概率密度函数为:
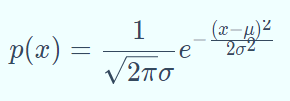
(5)指数分布:常用来表示独立随机事件发生的时间间隔,参数为λ>0的指数分布概率密度函数为:p(x)=λe−λx x≥0. 指数分布重要特征是无记忆性。
常用统计量
方差:用来衡量随机变量与数学期望之间的偏离程度。统计中的方差则为样本方差,是各个样本数据分别与其平均数之差 的平方和的平均数
协方差:衡量两个随机变量X和Y直接的总体误差
2.4 最优化估计
最小二乘估计
最小二乘估计又称最小平方法,是一种数学优化方法。它通过最小化误差的平方和寻找数据的最佳函数匹配。最小二乘法经常应用于回归问题,可以方便地求得未知参数,比如曲线拟合、最小化能量或者最大化熵
Task02 机器学习基础
一些基本概念
在这里进行一个简单的回顾,机器学习是指让计算机具有像人一样的学习和思考能力的技术的总称。具体来说是从已知数据中获得规律,并利用规律对未知数据进行预测的技术。
机器学习分类:
有监督学习(SupervisedLearning):有老师(环境)的情况下,学 生(计算机)从老师(环境)那里获得对错指示、最终答案的学习 方法。跟学师评
无监督学习(UnsupervisedLearning):没有老师(环境)的情况 下,学生(计算机)自学的过程,一般使用一些既定标准进行评价。 自学标评
强化学习(Reinforcement Learning):没有老师(环境)的情况下, 学生(计算机)对问题答案进行自我评价的方法。自学自评
机器学习根据任务分类:
有监督学习:代表任务"分类(Classification)"、“回归(Regression)”,分类任务一般适用于输出值是**离散(非连续值)**的场景下,回归任务一般适用于输出值是 连续值的场景下。
无监督学习:代表任务"聚类(Cluster)"、“降维(Dimension reduction)”

数据集
数据集:观测样本的集合。具体地,𝐷=x1,x2,⋯,xn,表示一个包含n个样本的数据集,其中 𝑥𝑖是一个向量,表示数据集的第𝑖个样本,其维度𝑑称为样本空间的维度。
向量 𝑥𝑖的元素称为样本的特征,其取值可以是连续的,也可以是离散的。从数据集中学出模型的过程,便称为“学习”或“训练”。
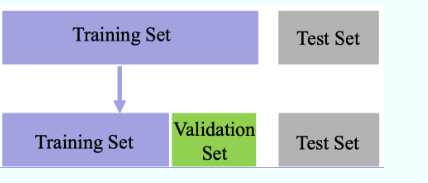
数据集分类
(1)训练集(Trainingset):用于模型拟合的数据样本;
(2)验证集(Validation set):是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估; 例如SVM中参数 cc (控制分类错误的惩罚程度)和核函数的选择,或者选择网络结构
(3)测试集(Testset):用来评估模最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。
误差分析
误差是指算法实际预测输出与样本真实值输出之间的差异。
训练误差:模型在训练集上的误差
泛化误差:模型在总体样本上的误差
测试误差:模型在测试集上的误差
由于我们无法知道总体样本量,所以我们只能尽量最小化训练误差, 导致训练误差和泛化误差有可能存在明显差异。
过拟合是指模型能很好地拟合训练样本,而无法很好地拟合测试样本的现象,从而导致泛化性能下降。为防止“过拟合”,可以选择减少参数、降低模型复杂度、正则化等。
欠拟合是指模型还没有很好地训练出数据的一般规律,模型拟合程度不高的现象。为防止“欠拟合”,可以选择调整参数、增加迭代深度、换用更加复杂的模型等。

泛化误差分析
假设数据集上需要预测的样本为Y,特征为X,潜在模型为 Y=f(X)+ε,其中ε∼N(0,σε)是噪声, 估计的模型为 f尖(X).

公式推导如上,这里的误差使用Err(error的简写)表示,注意上面误差的定义(误差我们这里表示的是预测值与真实值之间的差值) 通常在机器学习中,求得是预测值和真实值误差的平方,如果样本个数不唯一,那么需要把预测值和真实值误差的平方进行一个累加和,优化的方法一般采用的是最小均方误差算法(Minimum mean square error algorithm)。
Bias是偏差(bias)的英文,偏差反映了模型在 样本上的期望输出与真实 标记之间的差距,即模型本身的精准度,反映的是模型本身的拟合能力。
方差(Variance反映了模 型在不同训练数据集下学 得的函数的输出与期望输出之间的误差,即模型的稳定性,反应的是模型的波动情况。

欠拟合:高偏差低方差,解决办法如下,
寻找更好的特征,提升对数据的刻画能力
增加特征数量
重新选择更加复杂的模型
过拟合:低偏差高方差,解决办法如下
增加训练样本数量
减少特征维数,高维空间密度小
加入正则化项,使得模型更加平滑
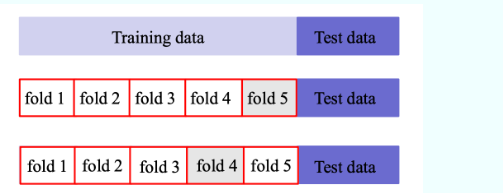
交叉验证
基本思路:将训练集划分为K份,每次采用其中K-1份作为训练集, 另外一份作为验证集,在训练集上学得函数后,然后在验证集上计算误差—K折交叉验证。
(1)K折重复多次,每次重复中产生不同的分割
(2)留一交叉验证(Leave-One-Out)
有监督学习
线性回归
线性回归是在样本属性和标签中找到一个线性关系的方法,根据训练数据找到一个线性模型,使得模型产生的预测值与样本标 签的差距最小。
若用 𝑥𝑖𝑘表示第𝑘个样本的第𝑖个属性,则线性模型一般形式为:
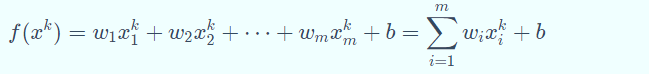
线性回归学习的对象就是权重向量𝑤和偏置向量𝑏。如果用最小均方 误差来衡量预测值与样本标签的差距,那么线性回归学习的目标可以表示为:
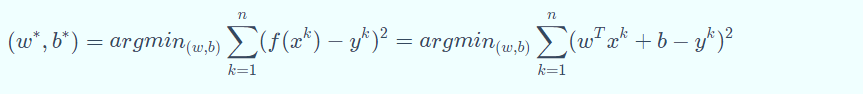
支持向量机
支持支持向量机是有监督学习中最具有影响力的方法之一,是基于线性判别函数的一种模型。
SVM基本思想:对于线性可分的数据,能将训练样本划分开的超平 面有很多,于是我们寻找“位于两类训练样本正中心的超平面”, 即margin最大化。从直观上看,这种划分对训练样本局部扰动的承 受性最好。事实上,这种划分的性能也表现较好。

决策树
决策树是一种基于树结构进行决策的机器学习方法,这恰是人类面临决策 时一种很自然的处理机制。
在这些树的结构里,叶子节点给出类标而内部节点代表某个属性;
例如,银行在面对是否借贷给客户的问题时,通常会进行一系列的决 策。银行会首先判断:客户的信贷声誉是否良好?良好的话,再判断 客户是否有稳定的工作? 不良好的话,可能直接拒绝,也可能判断客 户是否有可抵押物?..这种思考过程便是决策树的生成过程。
决策树的生成过程中,最重要的因素便是根节点的选择,即选择哪种特征作为决策因素:ID3算法使用信息增益作为准则。
无监督学习
聚类
聚类的目的是将数据分成多个类别,在同一个类内,对象(实体)之间具 有较高的相似性,在不同类内,对象之间具有较大的差异。
对一批没有类别标签的样本集,按照样本之间的相似程度分类,相似的归为一类,不相似的归为其它类。这种分类称为聚类分析,也 称为无监督分类
常见方法有K-Means聚类、均值漂移聚类、基于密度的聚类等
K-means聚类是一个反复迭代的过程,算法分为四个步骤:
(1)选取数据空间中的K个对象作为初始中心,每个对象代表一个聚 类中心;
(2)对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离, 按距离最近的准则将它们分到距离它们最近的聚类中心(最相似) 所对应的类;
(3)更新聚类中心:将每个类别中所有对象所对应的均值作为该类别 的聚类中心,计算目标函数的值;
(4)判断聚类中心和目标函数的值是否发生改变,若不变,则输出结 果,若改变,则返回(2)。
降维
降维的目的就是将原始样本数据的维度𝑑降低到一个更小的数𝑚,且尽量使得样本蕴含信息量损失最小,或还原数据时产生的误差最小。比如主成分分析法…
降维的优势:
数据在低维下更容易处理、更容易使用;
相关特征,特别是重要特征更能在数据中明确的显示出来;
如果只有二维或者三维的话,能够进行可视化展示;
去除数据噪声,降低算法开销等。
Task03 前馈神经网络
神经元
神经元(M-P) :1943 年,美国神经生理学家沃伦·麦卡洛克( Warren McCulloch ) 和数学家沃尔特 ·皮茨(Walter Pitts )对生物神经元进行建模,首次提出了一种形式神经元模型,并命名为McCulloch-Pitts模型,即后来广为人知的M-P模型。如下图,

在M-P(神经元) 模型中,神经元接受其他n个神经元的输入信号(0或1),这些输入信号经过权重加权并求和,将求和结果与阈值(threshold) θ 比较,然后经过激活函数处理,得到神经元的输出。激活函数的公式如下,
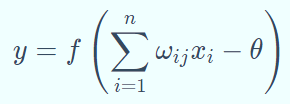
网络结构
神经网络模型是最早作为一种连接主义为主的模型。人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。常见的神经网络模型如下所示,其中圆形节点表示一个神经元,方形节点表示一组神经元。

感知器
单层感知器
1958 年,罗森布拉特( Roseblatt )提出了感知器,与 M-P 模型需 要人为确定参数不同,感知器能够通过训练自动确定参数。训练方式为有监督学习,即需要设定训练样本和期望输出,然后调整实际输出和期望输出之差的方式(误差修正学习)。
wi←wi+α(r−y)x ,
θ←θ−α(r−y)
其中,α 是学习率,r 和 y 分别是期望输出和实际输出。
感知器权重调整的基本思路:
实际输出 y 与期望输出 r 相等时,w 和 θ 不变
实际输出 y 与期望输出 r 不相等时,调整 w 和 θ 的值
wi←wi+α(r−y)x ,
θ←θ−α(r−y)
此时有俩种情况,
(1)未激活时:实际输出y = 0 ,期望输出r = 1 时,此时会出现 θ 逐渐减小,xi = 1的连接权重wi 逐渐增大,xi = 0 的连接权重wi 不变。
(2)激活过度:实际输出y = 1 ,期望输出r = 0 时,此时会出现 θ 逐渐增大,xi = 1的连接权重wi 逐渐降低,xi = 0 的连接权重wi 不变。
感知器模型的训练过程

多层感知器
单层感知器只能解决线性可分问题,而不能解决线性不可分问题;为了解决线性不可分问题,我们需要使用多层感知器。如下图所示,更好的理解单层感知器和多层感知器解决问题的区别。

多层感知器指的是由多层结构的感知器递阶组成的输入值向前传播的网络,也被称为前馈网络或正向传播网络。以三层结构的多层感知器为例,它由输入层、中间层及输出层组成,多层感知器的构成和上面提到的MP模型相同,多层感知器构成图如下,

BP(Back Propagation ,反向传播)算法
多层感知器的训练使用误差反向传播算法(Error Back Propagation),即BP算法。BP算法最早有沃博斯于1974年提出,鲁梅尔哈特等人进一步发展了该理论。
BP(Back Propagation ,反向传播)算法的过程
(1)前向传播计算:由输入层经过隐含层向输出层的计算网络输出
(2)误差反向逐层传递:网络的期望输出与实际输出之差的误差信号由输出层经过隐含层逐层向输入层传递
(3)由“前向传播计算”与“误差反向逐层传递”的反复进行的网络训练 过程
BP算法就是通过比较实际输出和期望输出得到误差信号,把误差信 号从输出层逐层向前传播得到各层的误差信号,再通过调整各层的连接权重以减小误差。权重的调整主要使用梯度下降法:
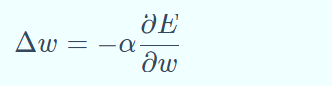
激活函数
一个神经元是由线性部分、非线性部分一起组成的,线性部分一般是由累加和的形式进行表示,非线性部分则用激活函数来表示,
(1)M-P 模型中使用阶跃函数作为激活函数,只能输出 0或 1,不连续所以 不可导
(2)为了使误差能够传播,鲁梅尔哈特等人提出使用可导函数Sigmoid作为激活函数

一些常见的激活函数:ReLu (Rectified Linear Unit,修正线性单元)和tanh等

BP(Back Propagation ,反向传播)算法的数学过程演示
以包含一个中间层和一个输出单元 y 的多层感知器为例:w1ij表示输 入层与中间层之间的连接权重,w2j1表示中间层与输出层之间的连接权重, i 表示输入层单元,j 表示中间层单元。
在反向传播算法中,更新优化哪个参数,那么就对哪个参数进行求导
中间层到输出层的求导

这里涉及到了一个复合函数求导的问题,字母 E 表示损失(误差)函数,y 表示的是一个神经元的函数表达式,结合神经元的构成(线性部分+非线性部分), y和u 构成了一个神经元的函数,而 u和 w构成了非线性部分的函数表达式,这样进行拆分,复合函数的求导也就更容易理解了。
输入层到中间层的求导

这里还是涉及到了复合函数求导的问题,理解的过程同上。
优化问题
难点
(1)参数过多,影响训练
(2)非凸优化问题:即存在局部最优而非全局最优解,影响迭代
(3)梯度消失问题,下层参数比较难调
(4)参数解释起来比较困难
需求
(1)计算资源要大
(2)数据要多
(3)算法效率要好:即收敛快
非凸优化问题

梯度消失问题

Task04 卷积神经网络CNN
前面我们介绍了全连接神经网络,它的权重矩阵的参数非常多。而往往自然图像中的物体都具有局部不变性特征,即尺度缩放、平移、旋转等操作不影响其语义信息,但是全连接前馈网络很难提取这些局部不变特征,这就引出了我们将要介绍的卷积神经网络(Convolutional Neural Networks,CNN)。
卷积
卷积:(f*g)(n)称为 f 和 g 的卷积,卷积可以分为连续卷积和离散卷积,表达为如下形式:
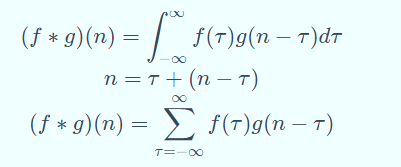
卷积的应用:
(1)统计学中加权平均法
(2)概率论中两个独立变量之和概率密度的计算
(3)信号处理中的线性系统
(4)物理学的线性系统
(5)图像处理中的应用(卷积神经网络)
卷积经常用在信号处理中,用于计算信号的延迟累积。
例如,假设一个信号发生器每个时刻 t 产生一个信号 xt,其信息的衰减率为 wk ,即在 k−1 个时间步长后,信息为原来的 wk倍,假设 w1 = 1,w2 = 1/2,w3 = 1/4,则时刻 t 收到的信号 yt为当前时刻产生的信息和以前时刻延迟信息的叠加,即:
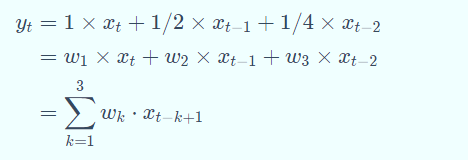
其中 wk就是滤波器,也就是常说的卷积核 convolution kernel。给定一个输入信号序列 x 和滤波器 w,卷积的输出为:
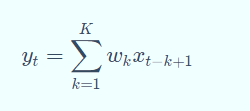
不同的滤波器来提取信号序列中的不同特征:

下面引入滤波器的滑动步长S和零填充P:
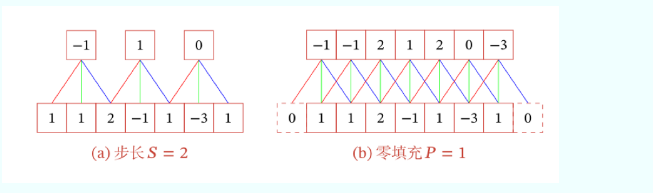
卷积的结果按输出长度不同可以分为三类:
窄卷积:步长 𝑇 = 1 ,两端不补零 𝑃 = 0 ,卷积后输出长度为 𝑀 − 𝐾 + 1
宽卷积:步长 𝑇 = 1 ,两端补零 𝑃 = 𝐾 − 1 ,卷积后输出长度 𝑀 + 𝐾 − 1
等宽卷积:步长 𝑇 = 1 ,两端补零 𝑃 =(𝐾 − 1)/2 ,卷积后输出长度 𝑀
其它形式的卷积
转置卷积/微步卷积:低维特征映射到高维特征

空洞卷积:为了增加输出单元的感受野,通过给卷积核插入“空洞”来变相地增加其大小。
卷积神经网络基本原理
卷积神经网络的基本结构大致包括:卷积层、激活函数、池化层、全连接层、输出层等。
二维卷积运算:给定二维的图像I作为输入,二维卷积核K,卷积运算可表示为
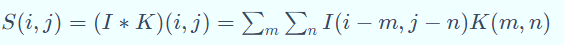 卷积核需要进行上下翻转和左右反转,
卷积核需要进行上下翻转和左右反转,
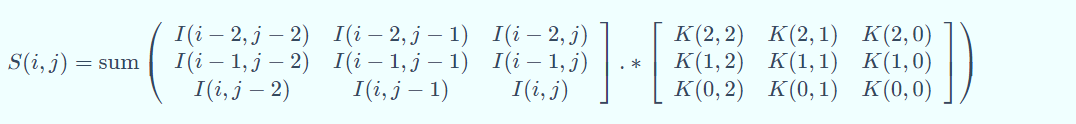 卷积实际上就是互相关
卷积实际上就是互相关
 卷积的步长(stride):卷积核移动的步长
卷积的步长(stride):卷积核移动的步长
 卷积的模式:Full**,** Same和Valid
卷积的模式:Full**,** Same和Valid

数据填充:如果我们有一个 𝑛×𝑛 的图像,使用𝑓×𝑓 的卷积核进行卷积操作,在进行卷积操作之前我们在图像周围填充 𝑝 层数据,输出的维度:

感受野:卷积神经网络每一层输出的特征图(featuremap)上的像素点在输 入图片上映射的区域大小,即特征图上的一个点对应输入图上的区 域。
 那么如何计算感受野的大小,可以采用从后往前逐层的计算方法:
那么如何计算感受野的大小,可以采用从后往前逐层的计算方法:
(1)第 i 层的感受野大小和第 i - 1 层的卷积核大小和步长有关系,同时也与第 (i - 1)层感受野大小有关
(2)假设最后一层(卷积层或池化层)输出特征图感受野的大小(相对于其直 接输入而言)等于卷积核的大小
激活函数
激活函数是用来加入非线性因素,提高网络表达能力,卷积神经网络中最常用的是ReLU,Sigmoid使用较少。
- ReLU函数
优点,计算速度快,ReLU函数只有线性关系,比Sigmoid和Tanh要快很多; 输入为正数的时候,不存在梯度消失问题。
缺点,强制性把负值置为0,可能丢掉一些特征;当输入为负数时,权重无法更新,导致“神经元死亡”(学习率不 要太大) - Parametric ReLU
优点,比sigmoid/tanh收敛快;解决了ReLU的“神经元死亡”问题。
缺点,需要再学习一个参数,工作量变大。 - ELU函数
优点,处理含有噪声的数据有优势;更容易收敛
缺点,计算量较大,收敛速度较慢。
特征图
浅层卷积层:提取的是图像基本特征,如边缘、方向和纹理等特征
深层卷积层:提取的是图像高阶特征,出现了高层语义模式,如“车轮”、“人脸”等特征
池化层
池化操作使用某位置相邻输出的总体统计特征作为该位置 的输出,常用最大池化 (max-pooling)和均值池化(average- pooling)。
池化层不包含需要训练学习的参数,仅需指定池化操作的核大小、操作步幅以及池化类型。

全连接层
(1)对卷积层和池化层输出的特征图(二维)进行降维
(2)将学到的特征表示映射到样本标记空间的作用
输出层
对于分类问题:使用Softmax函数
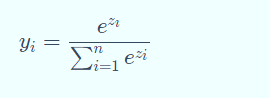 对于回归问题:使用线性函数
对于回归问题:使用线性函数
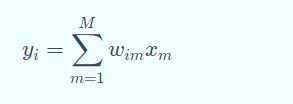
卷积神经网络的训练
Step 1:用随机数初始化所有的卷积核和参数/权重
Step 2:将训练图片作为输入,执行前向步骤(卷积, ReLU,池化以及全连接层的前向传播)并计算每个类别的对应输出概率。
Step 3:计算输出层的总误差
Step 4:反向传播算法计算误差相对于所有权重的梯度,并用梯度下降法更新所有的卷积核和参数/权重的值,以使输出误差最小化
注:卷积核个数、卷积核尺寸、网络架构这些参数,是在 Step 1 之前就已经固定的,且不会在训练过程中改变——只有卷 积核矩阵和神经元权重会更新。

经典卷积神经网络

1. LeNet-5
主要进行手写数字识别和英文字母识别。经典的卷积神经网络,LeNet虽小,各模块齐全,是学习 CNN的基础。

输入层:32∗32 的图片,也就是相当于1024个神经元
C1层(卷积层):选择6个 5∗5 的卷积核,得到6个大小为32-5+1=28的特征图,也就是神经元的个数为 6∗28∗28=4704
S2层(下采样层):每个下抽样节点的4个输入节点求和后取平均(平均池化),均值 乘上一个权重参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。池化核大小选择 2∗2,得到6个 14∗14 大小特征图
C3层(卷积层):用 5∗5的卷积核对S2层输出的特征图进行卷积后,得到6张10∗10 新 图片,然后将这6张图片相加在一起,然后加一个偏置项b,然后用 激活函数进行映射,就可以得到1张 10∗10 的特征图。我们希望得到 16 张 10∗10 的 特 征 图 , 因 此 我 们 就 需 要 参 数 个 数 为 16∗(6∗(5∗5))=16∗6∗(5∗5) 个参数
S4层(下采样层):对C3的16张 10∗10 特征图进行最大池化,池化核大小为2∗2,得到16张大小为 5∗5 的特征图。神经元个数已经减少为:16∗5∗5=400
C5层(卷积层):用5∗5 的卷积核进行卷积,然后我们希望得到120个特征图,特征图 大小为5-5+1=1。神经元个数为120(这里实际上是全连接,但是原文还是称之为了卷积层)
F6层(全连接层):有84个节点,该层的训练参数和连接数(120+1)∗84=10164
Output层:共有10个节点,分别代表数字0到9,如果节点i的输出值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式:
2. AlexNet
2012年提出,通过AlexNet确定了CNN在计算机视觉领域的王者地位。
(1)首次成功应用ReLU作为CNN的激活函数
(2)使用Dropout丢弃部分神元,避免了过拟合
(3)使用重叠MaxPooling(让池化层的步长小于池化核的大小), 一定程度上提升了特征的丰富性
(4)使用CUDA加速训练过程
(5)进行数据增强,原始图像大小为256×256的原始图像中重 复截取224×224大小的区域,大幅增加了数据量,大大减 轻了过拟合,提升了模型的泛化能力

输入层:AlexNet首先使用大小为224×224×3图像作为输入(后改为227×227×3)
第一层(卷积层):包含96个大小为11×11的卷积核,卷积步长为4,因此第一层输出大小为55×55×96;然后构建一个核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为27×27×96
第二层(卷积层):包含256个大小为5×5卷积核,卷积步长为1,同时利用padding保证 输出尺寸不变,因此该层输出大小为27×27×256;然后再次通过 核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为13×13×256
第三层与第四层(卷积层):均为卷积核大小为3×3、步长为1的same卷积,共包含384个卷积核,因此两层的输出大小为13×13×384
第五层(卷积层):同样为卷积核大小为3×3、步长为1的same卷积,但包含256个卷积 核,进而输出大小为13×13×256;在数据进入全连接层之前再次 通过一个核大小为3×3、步长为2的最大池化层进行数据降采样, 数据大小降为6×6×256,并将数据扁平化处理展开为9216个单元
第六层、第七层和第八层(全连接层):全连接加上Softmax分类器输出1000类的分类结果,有将近6千万个参数
3. VGGNet
VGGNet由牛津大学和DeepMind公司提出,比较常用的是VGG-16,结构规整,具有很强的拓展性,相较于AlexNet,VGG-16网络模型中的卷积层均使用 3∗3 的卷积核,且均为步长为1的same卷积,池化层均使用 2∗2 的 池化核,步长为2。

两个卷积核大小为 3∗3 的卷积层串联后的感受野尺寸为 5∗5, 相当于单个卷积核大小为5∗5 的卷积层
两者参数数量比值为(2∗3∗3)/(5∗5)=72% ,前者参数量更少
此外,两个的卷积层串联可使用两次ReLU激活函数,而一个卷积层只使用一次。
4. Inception Net
Inception Net 是Google公司2014年提出,获得ImageNet LSVRC-2014冠军。文章提出获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),采用了22层网络。
Inception Module
深度:层数更深,采用了22层,在不同深度处增加了两个 loss来避免上述提到的梯度消失问题
宽度:Inception Module包含4个分支,在卷积核3x3、5x5 之前、max pooling之后分别加上了1x1的卷积核,起到了降低特征图厚度的作用。1×1的卷积的作用:可以跨通道组织信息,来提高网络的表达能力;可以对输出通道进行升维和降维。

5. ResNet
ResNet(Residual Neural Network),又叫做残差神经网 络,是由微软研究院的何凯明等人2015年提出,获得ImageNet ILSVRC 2015比赛冠军,获得CVPR2016最佳论文奖。
随着卷积网络层数的增加,误差的逆传播过程中存在的梯 度消失和梯度爆炸问题同样也会导致模型的训练难以进行,甚至会出现随着网络深度的加深,模型在训练集上的训练误差会出现先降低再升高的现象。残差网络的引入则有助于解决梯度消失和梯度爆炸问题。
残差块
ResNet的核心是叫做残差块(Residual block)的小单元, 残差块可以视作在标准神经网络基础上加入了跳跃连接(Skip connection)
原连接
 跳跃连接
跳跃连接

6. Densenet
DenseNet中,两个层之间都有直接的连接,因此该网络的直接连接个数为L(L+1)/2。对于每一层,使用前面所有层的特征映射作为输入,并且使用其自身的特征映射作为所有后续层的输入。
 DenseNets可以自然地扩展到数百个层,而没有表现出优化困难。在实验中,DenseNets随着参数数量的增加,在精度上产生一致的提高,而没有任何性能下降或过拟合的迹象。
DenseNets可以自然地扩展到数百个层,而没有表现出优化困难。在实验中,DenseNets随着参数数量的增加,在精度上产生一致的提高,而没有任何性能下降或过拟合的迹象。
优点:
(1)缓解了消失梯度问题
(2)加强了特征传播,鼓励特征重用
(3)一定程度上减少了参数的数量
Task05 循环神经网络RNN
循环神经网络(recurrent neural network, RNN) 是一类用于处理序列数据的神经网络。
计算图
计算图是形式化一组计算结构的方式,它的元素包括节点(node)和边(edge),节点表示变量,可以是标量、矢量、张量等,而边表示的是某个操作,即函数。
用两个计算图来表示一个嵌套函数:

也可以用复合函数来表示计算图

对于计算图的求导,可以采用链式法则有如下俩种情况,
情况1

情况2

举个例子简单说明,如下计算图的求导,其中黑色实现代表数据流动方向,红色和黄色代表导数传播方向:

(1)a = 3, b = 1 可以得到 c = 4, d = 2, e = 6
(2)e 对 a 进行求导,采用链式法则,等价于e 先对c进行求导,然后c在对a进行求导,结果得到d ,数值表示为2.
RNN基本原理
CNN大量应用于图像处理领域,然而现实生活中还存在很多序列化结构,我们需要建立一种更好的模型来处理序列化数据。
循环神经网络的节点间的连接形成一个遵循时间序列的有向图。它的核心思想是,样本间存在顺序关系,每个样本和它之前的样本存在关联。通过神经网络在时序上的展开,我们能够找到样本之间的序列相关性。RNN的一般结构如下:
 其中各个符号的表示:xt,st,ot 分别表示的是 t 时刻的输入、记忆和输出,U,V,W是RNN的连接权重,bs,bo是RNN的偏置,σ,φ是激活函数,σ通常选tanh或sigmoid,φ通常选用softmax。
其中各个符号的表示:xt,st,ot 分别表示的是 t 时刻的输入、记忆和输出,U,V,W是RNN的连接权重,bs,bo是RNN的偏置,σ,φ是激活函数,σ通常选tanh或sigmoid,φ通常选用softmax。
其中 softmax 函数,用于分类问题的概率计算。本质上是将一个K维的任意实数向量压缩 (映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间。
RNN的一般结构
(1)Elman Network

(2)Jordan Network

(3)其它

RNN训练算法BPTT
我们先来回顾一下BP算法,就是定义损失函数 Loss 来表示输出 y^和真实标签 y 的误差,通过链式法则自顶向下求得 Loss 对网络权重的偏导。沿梯度的反方向更新权重的值, 直到 Loss 收敛。而这里的 BPTT 算法就是加上了时序演化,后面的两个字母 TT 就是 Through Time。

定义输出函数
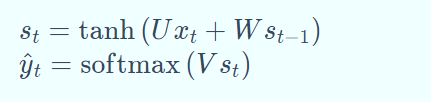
为了弥补前面产生的误差对整体的影响,这里我们还需要定义损失函数,

分别求损失函数E对U、V、W的梯度:
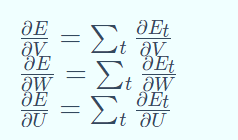
求 E 对 V 的梯度,先求 E3对 V 的梯度,这里还是采用的链式法则,
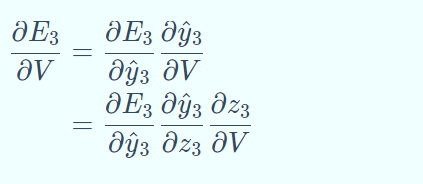
求 E 对 W 的梯度,先求 E3对 W 的梯度,

其中: s3依赖于 s2,而 s2又依赖于 s1和 W ,依赖关系 一直传递到 t = 0 的时刻。因此,当我们计算对于 W 的偏导数时,不能把 s2看作是常数项!
求 E 对 U 的梯度,先求 E3对 U 的梯度,
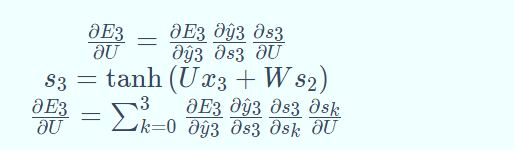
LSTM基本原理
LSTM,即长短时记忆网络,于1997年被Sepp Hochreiter 和Jürgen Schmidhuber提出来,LSTM是一种用于深度学习领域的人工循环神经网络(RNN)结构。一个LSTM单元由输入门、输出门和遗忘门组成,三个门控制信息进出单元。

(1)LSTM依靠贯穿隐藏层的细胞状态实现隐藏单元之间的信息传递,其中只有少量的线性操作
(2)LSTM引入了“门”机制对细胞状态信息进行添加或删除,由此实现长程记忆
(3)“门”机制由一个Sigmoid激活函数层和一个向量点乘操作组成,Sigmoid层的输出控制了信息传递的比例
遗忘门:LSTM通过遗忘门(forget gate)实现对细胞状态信息遗忘程度的控制,输出当前状态的遗忘权重,取决于 ht−1和 xt
 输入门:LSTM通过输入门(input gate)实现对细胞状态输入接收程度的控制,输出当前输入信息的接受权重,取决于 ht−1和 xt.
输入门:LSTM通过输入门(input gate)实现对细胞状态输入接收程度的控制,输出当前输入信息的接受权重,取决于 ht−1和 xt.
 输出门:LSTM通过输出门(output gate)实现对细胞状态输出认可程度的控制,输出当前输出信息的认可权重,取决于 ht−1 和 xt.
输出门:LSTM通过输出门(output gate)实现对细胞状态输出认可程度的控制,输出当前输出信息的认可权重,取决于 ht−1 和 xt.

状态更新:“门”机制对细胞状态信息进行添加或删除,由此实现长程记忆。

经典的循环神经网络
(1)Gated Recurrent Unit (GRU),是在2014年提出的,可认为是LSTM 的变种,它的细胞状态与隐状态合并,在计算当前时刻新信息的方法和LSTM有 所不同;GRU只包含重置门和更新门;在音乐建模与语音信号建模领域与LSTM具有相似的性能,但是参数更少,只有两个门控。

(2)Peephole LSTM
让门层也接受细胞状态的输入,同时考虑隐层信息的输入。

(3)Bi-directional RNN(双向RNN)假设当前t的输出不仅仅和之前的序列有关,并且还与之后的序列有关,例如:完形填空,它由两个RNNs上下叠加在一起组成,输出由这两个RNNs的隐藏层的状态决定。

RNN主要应用
(1)语言模型,根据之前和当前词预测下一个单词或者字母
(2)自动作曲
(3)机器翻译,将一种语言自动翻译成另一种语言
(4)自动写作,根据现有资料自动写作,当前主要包括新闻写作和诗歌创作。主要是基于RNN&LSTM的文本生成技术来实现,需要训练大量同 类文本,结合模板技术。
(5)图像描述,根据图像形成语言描述















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









