







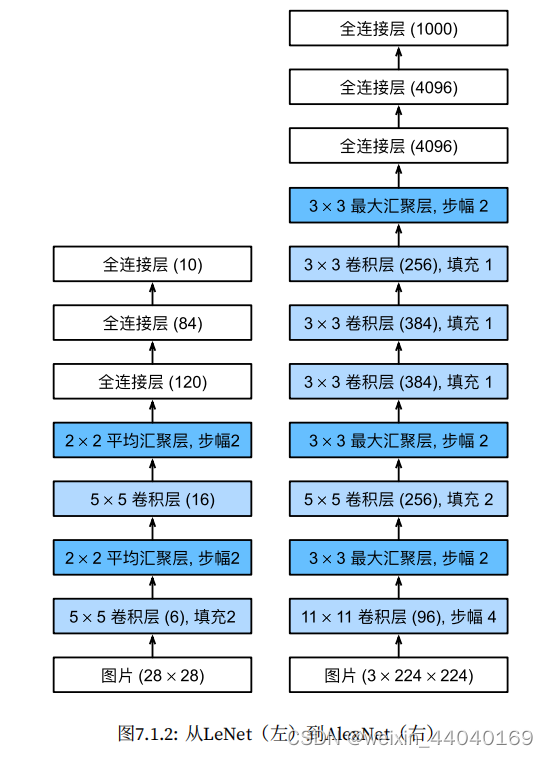
1.LeNet–早期成功的神经网络
LeNet 分为卷积层块和全连接层块两个部分,卷积层块⾥的基本单位是卷积层后接最⼤池化层。
使用卷积层来学习图片空间信息,通过池化层降低图片敏感度
使用全连接层来转换到类别空间。
2.AlexNet是更大更深的LeNet,,AlexNet 包含 8 层变换,其中有五层卷积和两层全连接隐含层,以及⼀个全连接输出层
AlextNet 将 sigmoid 激活函数改成了更加简单的 ReLU 激活函数
AlextNet 通过丢弃法来控制全连接层的模型复杂度。
AlextNet 引⼊了⼤量的图像增⼴,例如翻转、裁剪和颜⾊变化,从而进⼀步扩⼤数据集来缓解过拟合。
新引入了丢弃法,ReLU,最大池化,数据增强(图中汇聚层即池化层)
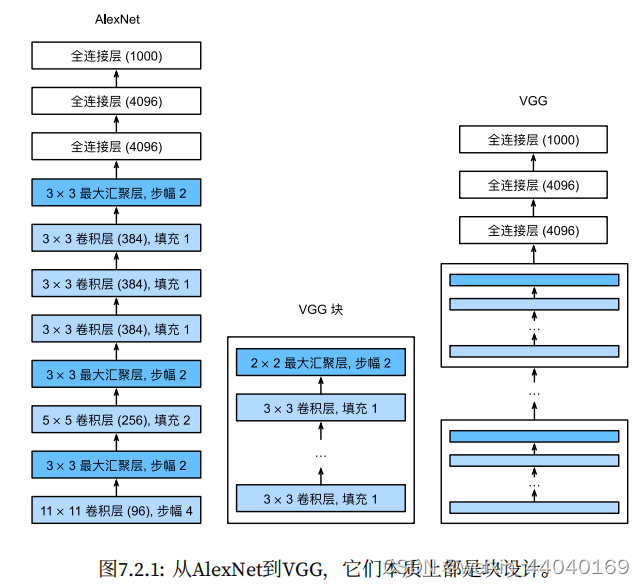
3.VGG 块:的组成规律是:连续使⽤数个相同的填充为 1、窗口形状为 3 × 3 的卷积层后接上⼀个步
幅为 2、窗口形状为 2 × 2 的最⼤池化层。卷积层保持输⼊的⾼和宽不变,而池化层则对其减半。
VGG⽹络:可以分为两部分:第⼀部分主要由卷积层和汇聚层组成,第⼆部分由全连接层组成。
VGG使用可重复使用的卷积块来构建深度卷积神经网络。
不同卷积块个数和超参数可以得到不同复杂度的变种。
VGG网络如下图
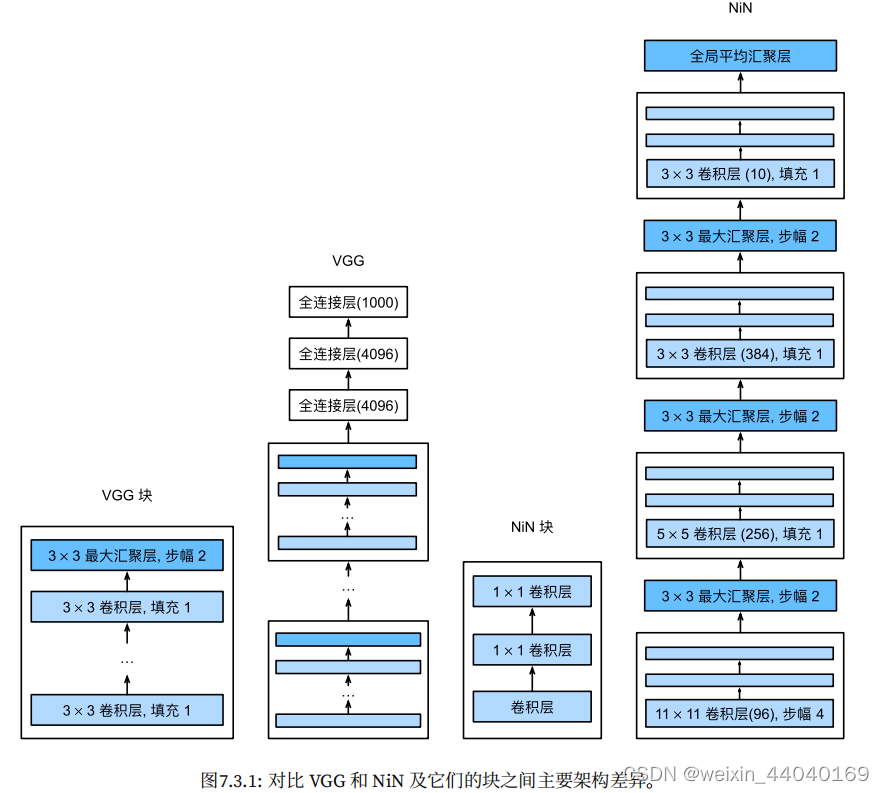
4.NiN(网络中的网络)
NiN块:
1*1卷积层可以等价于一个全连接层
步幅为2的最大池化层(高宽减半)
补充:
1 × 1卷积层通常⽤于调整⽹络层的通道数量和控制模型复杂性。实际上,1 × 1 卷积的主要计算发⽣在通道维上。如下图展⽰了使⽤输⼊通道数为 3、输出通道数为 2 的 1 × 1 卷积核的互相关计算。值得注意的是,输⼊和输出具有相同的⾼和宽。输出中的每个元素来⾃输⼊中在⾼和宽上相同位置的元素在不同通道之间的按权重累加。
假设我们将通道维当做是特征维,将⾼和宽维度上的元素当成数据样本,那么 1 × 1 卷积层的作⽤与全连接层等价。

每个输⼊都与每个输出(在本例中只有⼀个输出)相连,我们将这种变换(图3.1.2中的输出
层)称为全连接层(fully-connected layer)
我们知道,卷积层的输⼊和输出通常是四维数组(样本,通道,⾼,宽),而全连接层的输⼊和输
出则通常是⼆维数组(样本,特征)。如果想在全连接层后再接上卷积层,则需要将全连接层的
输出变换为四维。因此,NiN 使 ⽤ 1 × 1 卷积层来替代全连接层,从而使空间信息能够⾃然传递到后⾯的层中去。不用全连接层。
NiN 使⽤了输出通道数等于标签类别数的 NiN 块,然后使⽤全局平均池化层对每个通道中所有元素求平均并直接⽤于分类。这⾥的全局平均池化层即窗口形状等于输⼊空间维形状的平均池化层。NiN 的这个设计的好处是可以显著减小模型参数尺⼨,从而很好地
缓解过拟合。然而,该设计有时会造成模型训练时间的增加。(NiN网络如下图)
5.GoogLeNet含并行连结的网络
重点是解决了什么样⼤⼩的卷积核最合适的问题。
基本的卷积块被称为Inception块,(不改变高宽,只改变通道数)
Inception 块⾥有四条并⾏的线路。前三条线路使⽤窗口⼤小分别是 1 × 1、 3 × 3 和 5 × 5 的卷积层来抽取不同空间尺⼨下的信息。其中中间两个线路会对输⼊先做 1 × 1 卷
积来减少输⼊通道数,以降低模型复杂度。第四条线路则使⽤ 3 × 3 最⼤池化层,后接 1 × 1 卷积
层来改变通道数。四条线路都使⽤了合适的填充来使得输⼊输出⾼和宽⼀致。最后我们将每条线
路的输出在通道维上连结,并输⼊到接下来的层中去。结构如下图

GoogLeNet使用9个Inception块
主体卷积部分中使⽤五个模块(block)。其架构如下图

6.ResNet残差网络
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。跳跃连接(Skip connection)可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。利用跳跃连接构建能够训练深度网络的ResNets,有时深度能够超过100层。
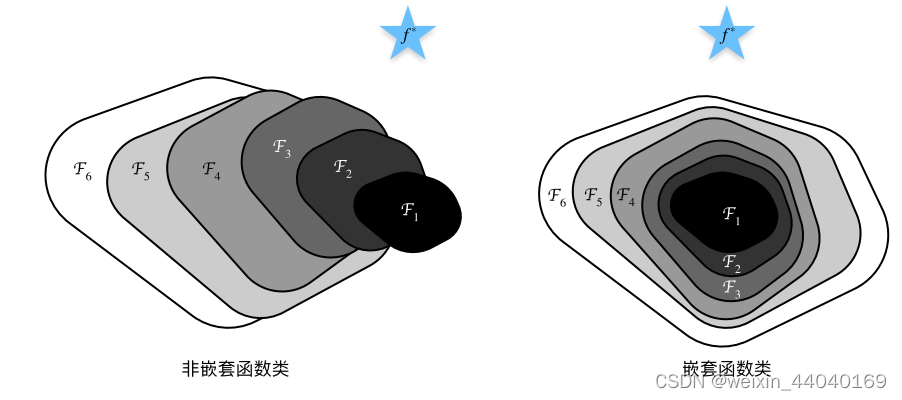
残差⽹络的核⼼思想是:每个附加层都应该更容易地包含原始函数作为其元素之⼀。
这样的设计要求2个卷积层的输出与输⼊形状⼀样,从⽽使它们可以相加(下图左)。如果想改变通道数,就需要引⼊⼀个额外的1 × 1卷积层来将输⼊变换成需要的形状后再做相加运算(下图右)。
残差块如下图

残差块使得训练很深的网络更加容易,甚至可以上千。
残差结构
可以看到普通直连的卷积神经网络和 ResNet 的最大区别在于,ResNet 有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差
残差块
如果我们直接把输入 x 传到输出作为初始结果,那么此时我们需要学习的目标就是 F(x)=H(x)-x,于是 ResNet 相当于将学习目标改变了,不再是学习一个完整的输出,而是最优解 H(X) 和全等映射 x 的差值,即残差 F(x) = H(x) - x。以上摘自Residual Net 详解















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









