







前言
Deep Residual Networks - Deep Learning Gets Way Deeper深度残差网络-让深度学习变得超级深
ResNet(Residual Neural Network)由前微软研究院的 Kaiming He 等4名华人提出,通过使用 Residual Blocks 成功训练152层深的神经网络,在 ILSVRC 2015 比赛中获得了冠军,取得 3.57% 的 top-5 错误率,同时参数量却比 VGGNet 低,效果非常突出。ResNet 的结构可以极快地加速超深神经网络的训练,模型的准确率也有非常大的提升。MSRA的深度残差网络在2015年ImageNet和COCO如下共5个领域取得第一名:ImageNet recognition, ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation。
- 历年网络比赛效果
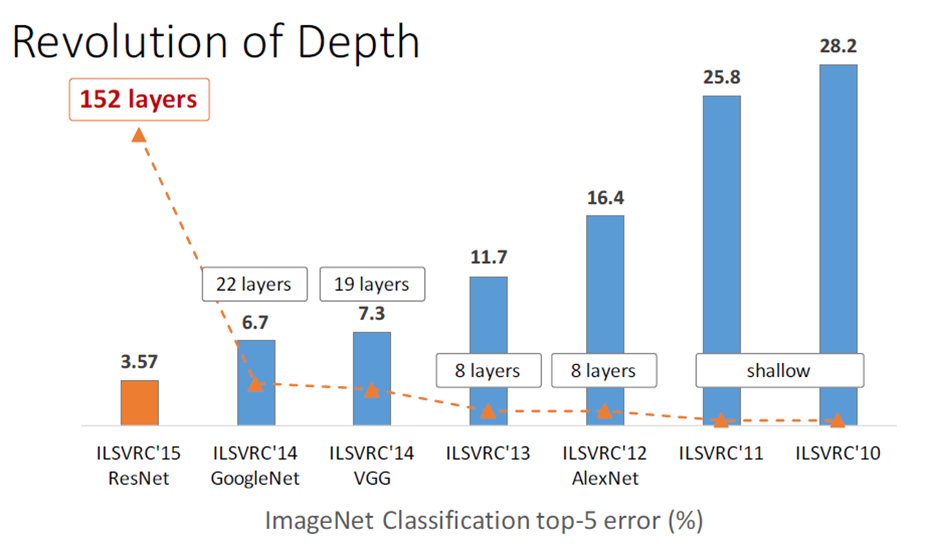
- 网络发展革命

是不是网络越深模型效果越好?
深度带来的问题
随着网络结构的加深,带来了两个问题:
- 一是vanishing/exploding gradient,导致了训练十分难收敛,这类问题能够通过normalized initialization 和intermediate normalization layers解决;
- 另一个是被称为degradation的退化现象。对合适的深度模型继续增加层数,模型准确率会下滑(不是overfit造成),training error和test error都会很高,相应的现象在CIFAR-10和ImageNet都有出现。
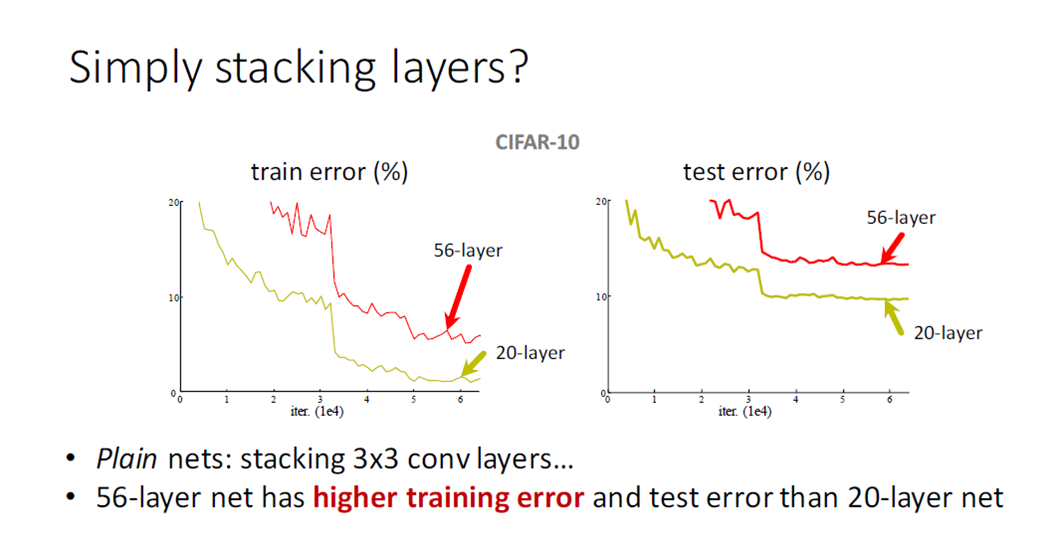
残差结构
可以看到普通直连的卷积神经网络和 ResNet 的最大区别在于,ResNet 有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这种结构也被称为 shortcut connections。传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。 同时34层 residual network 取消了最后几层 FC,通过 avg pool 直接接输出通道为1000的 Softmax,使得 ResNet 比16-19层 VGG 的计算量还低。 注意:实现部分是深度未发生变化的连接,虚线部分是深度发生变化的连接。 对应深度有变化的连接有两种解决方案:
- 使用 zero-pading 进行提升深度 parameter-free。
- 使用 1*1的卷积核提升维度 有卷积核的运算时间。
两种方法,使用下面一种方法效果更好,但是运行会更耗时,一般还是更倾向于第一种方案节约运算成本。

残差块
作者提出一个 Deep residual learning 框架来解决这种因为深度增加而导致性能下降问题。
假定某段神经网络的输入是 x,期望输出是 H(x),即 H(x) 是期望的复杂潜在映射,但学习难度大;如果我们直接把输入 x 传到输出作为初始结果,通过下图“shortcut connections”,那么此时我们需要学习的目标就是 F(x)=H(x)-x,于是 ResNet 相当于将学习目标改变了,不再是学习一个完整的输出,而是最优解 H(X) 和全等映射 x 的差值,即残差 F(x) = H(x) - x;
Shortcut 原意指捷径,在这里就表示越层连接,在 Highway Network 在设置了一条从 x 直接到 y 的通路,以 T(x, Wt) 作为 gate 来把握两者之间的权重;而 ResNet shortcut 没有权值,传递 x 后每个模块只学习残差F(x),且网络稳定易于学习,作者同时证明了随着网络深度的增加,性能将逐渐变好。可以推测,当网络层数够深时,优化 Residual Function:F(x)=H(x)−x,易于优化一个复杂的非线性映射 H(x)。
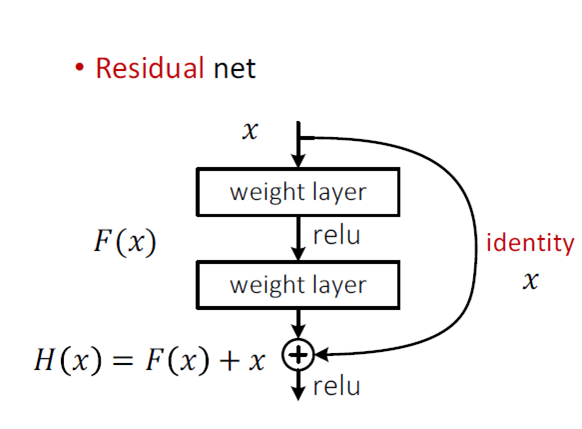
瓶颈结构
在 ResNet 的论文中,除了提出残差学习单元的两层残差学习单元,还有三层的残差学习单元。两层的残差学习单元中包含两个相同输出通道数(因为残差等于目标输出减去输入,即,因此输入、输出维度需保持一致)的3´3卷积;而3层的残差网络则使用了 Network In Network 和 Inception Net 中的1´1卷积,并且是在中间3´3的卷积前后都使用了1´1卷积,先降维再升维的操作,降低计算复杂度。另外,如果有输入、输出维度不同的情况,我们可以对 x 做一个线性映射变换,再连接到后面的层。
TIP:网络深度大于50层时使用bottleneck,可以有效降低参数
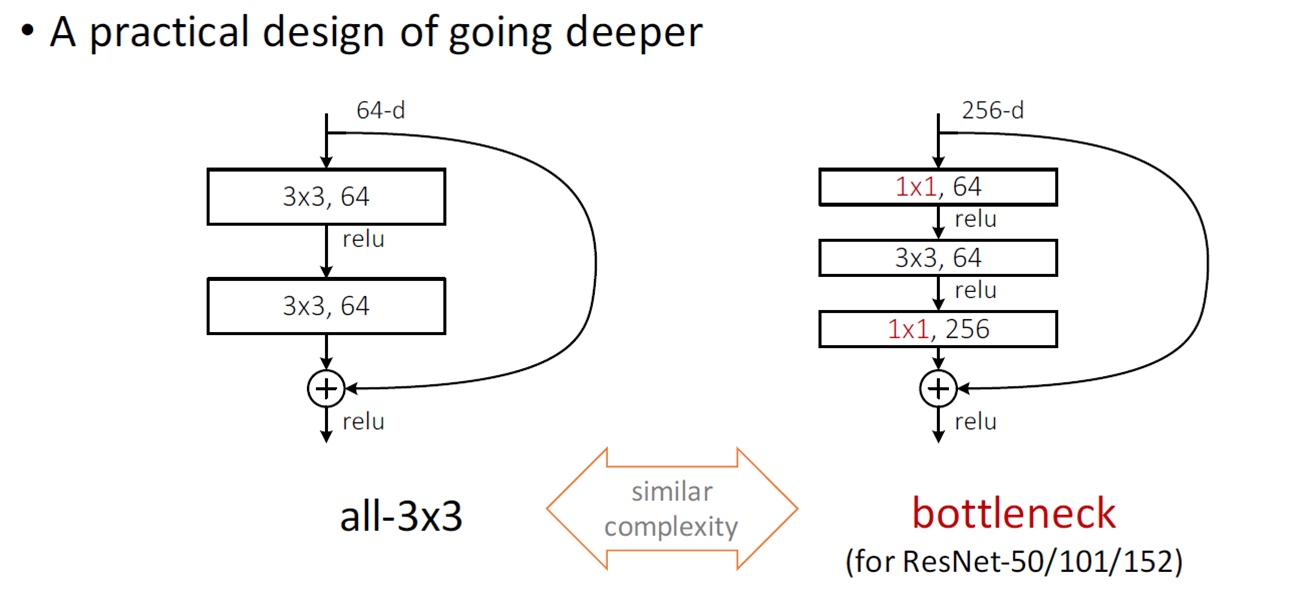
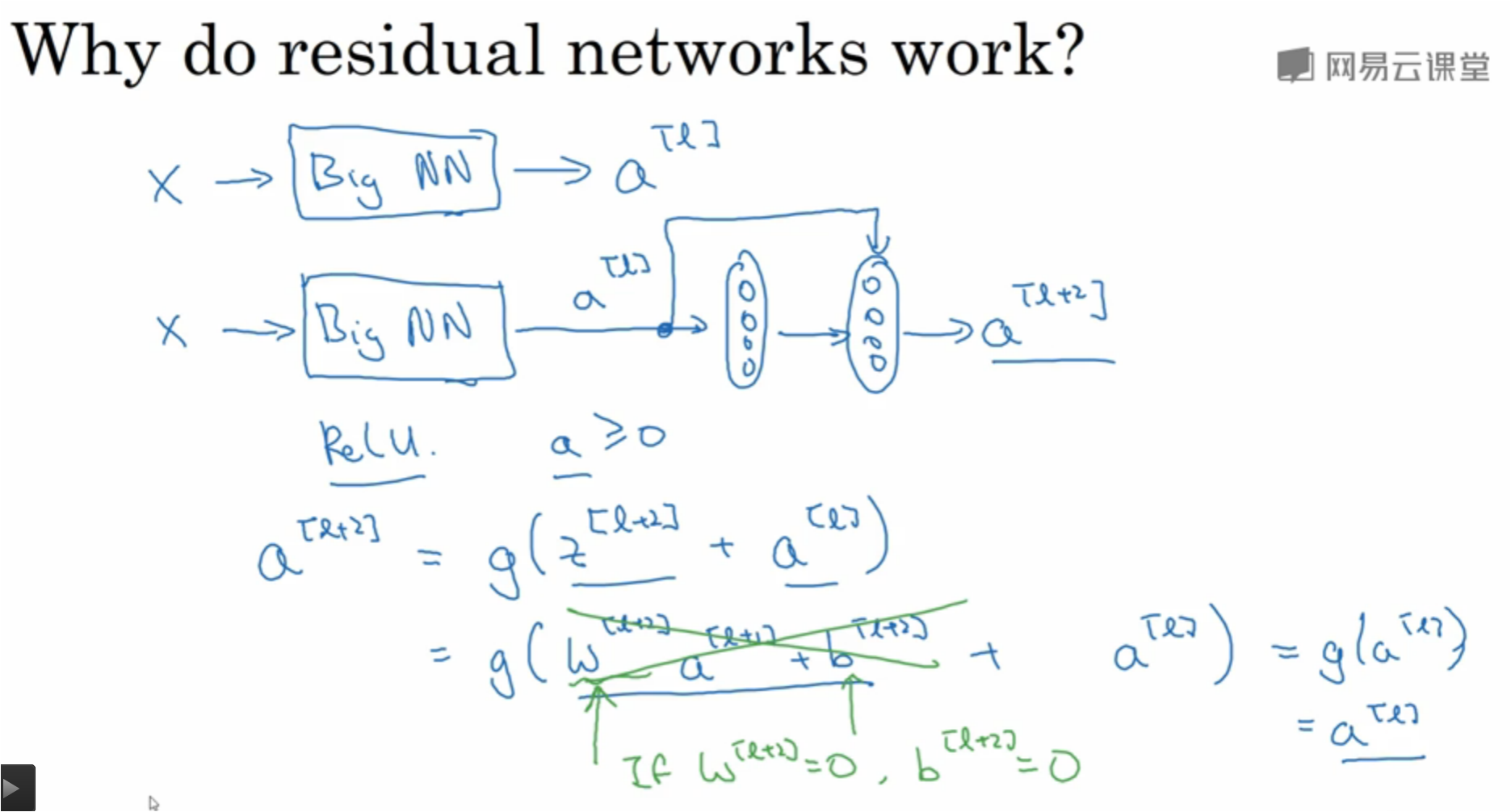
Why residual better?
Deeplearning.ai 第四部分(卷积神经网络) 第二周内容
众所周知,网络的性能与深度息息相关。如果在一个浅层网络A上叠加几层layer形成网络B,如果这些新添加的layer是Identity mapping(恒等映射),那么网络B性能至少不会比A差。但是实际实验结果却显示网络越深,性能越差,所以作者猜测solver 对于学习单位映射比较困难。既然学习单位映射比较麻烦,那干脆直接给它加上一个shortcut,直接给这个模块输出叠加上输入。实际情况中,单位映射x并不是最优解H(x),最优解在单位映射附近,这个最优解与单位映射之间的差就叫做residual F(x)。
附录
- batch normalization实现方法

- 每层都会使用batch normalization
- γ与白塔 在每一层都有,并且会通过学习不断更新。
- μ是一个batch的均值
- の是标准差 (一般会给 の加个很小的值10^-8, 防止の为0)
(2)测试阶段
- 模型训练好以后,参数固定不变,那么对于每一个输入的测试样本来说,归一化所用的均值 E 和方差 Var 都应该固定不变。所以,用训练阶段的批的均值的均值和方差的无偏估计来计算:

重构输出:
(3)注意事项
- 原来神经元的偏置bias在增加了BN层以后就不再需要了。
- BN有一个作用就是可以使得激活函数的作用范围更大,所以在激活函数前操作。
- python 实现残差块
def residual_block(x, out_channels, down_sample, projection=False):
in_channels = x.get_shape().as_list()[3]
if down_sample:
x = max_pool(x)
output = conv2d_with_batch_norm(x, [3, 3, in_channels, out_channels], 1)
output = conv2d_with_batch_norm(output, [3, 3, out_channels, out_channels], 1)
if in_channels != out_channels:
if projection:
# projection shortcut
input_ = conv2d(x, [1, 1, in_channels, out_channels], 2)
else:
# zero-padding
input_ = tf.pad(x, [[0,0], [0,0], [0,0], [0, out_channels - in_channels]])
else:
input_ = x
return output + input_
def residual_group(name,x,num_block,out_channels):
assert num_block>=1,'num_block must greater than 1'
with tf.variable_scope('%s_head'%name):
output = residual_block(x, out_channels, True)
for i in range (num_block-1):
with tf.variable_scope('%s_%d' % (name,i+1)):
output = residual_block(output,out_channels, False)
return output
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











