







文章链接:https://doi.org/10.48550/arXiv.2403.10406
代码链接:https://github.com/Lighting-YXLI/BiAtten-Net
文章题目
Deep Bi-directional Attention Network for Image Super-Resolution Quality Assessment
发表年限
2024
期刊/会议名称
2024 IEEE International Conference on Multimedia and Expo (ICME)
论文简要
- 本文首次提出了一种专门为 SR 图像设计的基于深度学习的全参考图像质量评估(FR-IQA)方法。
- 受到人类视觉系统(HVS)特性的启发,作者为 SR 图像引入了双向注意力。
- 作者构建了一个深层双向注意力网络(BiAtten-Net),该网络能动态深化对两个过程中失真的视觉关注,与人类视觉系统(HVS)高度一致。作者在本文中开创了一个新的模型,通过 SR 图像与相应 HR 参考之间的双向信息交互来学习 SR 图像中的失真。
- 实验结果表明,作者提出的 BiAtten-Net 有效地为 SR 失真提供了视觉注意力,并超越了现有的最先进的质量评估方法。
动机
- 现有基于双流网络的 SR 图像质量评估(IQA)指标缺少分支间的交互。
- 鉴于将视觉注意力集中在 SR 图像的伪影上符合人类视觉系统,许多工作通过加权注意力图增强了 IQA 捕捉局部伪影或主要失真区域质量降低的能力。然而,这些基于注意力的方法缺乏各个分支之间的交互(即通道和空间)。
- 此外,这些方法仅考虑对 SR 图像的视觉注意力,并且缺乏与 HR 参考图像的交互作用。
主要思想或方法架构
- 考虑到失真是由于从降采样的高分辨率(HR)参考图像生成超分辨率(SR)图像而产生的,作者通过在输入为 HR 参考图像的分支中模拟此过程,来近似 HR 参考图像至 SR 图像。
- 此外,人类受试者通过评估 SR 图像与 HR 参考图像的近似程度来评价 SR 图像的感知质量。因此,作者使用输入为 SR 图像的分支来接近 SR 图像至 HR 参考图像,这模拟了主观质量评估的过程,因而更符合人类视觉系统(HVS)。
- 通过这种方式,作者通过动态模拟 HR 参考图像转换为 SR 图像及其反向过程的交互,有效地增强了对失真的视觉关注。
- 最近,注意力机制在 Transformer 模型中被广泛采用,具体如下:
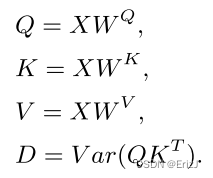
- 由于注意力机制是通过计算 Q Q Q, K K K 和 V V V 之间的点积来获得的,所以所有三个矩阵都需要是方阵。
- 给定一个形状为 M × M M\times{M} M×M 的输入图像 X X X,可以通过线性变换 W Q W_Q WQ、 W K W_K WK 和 W V W_V WV 得到 Q Q Q( Q u e r y Query Query) ∈ \in ∈ R M × M R^{M\times{M}} RM×M, K K K( K e y Key Key) ∈ \in ∈ R M × M R^{M\times{M}} RM×M 和 V V V( V a l u e Value Value) ∈ \in ∈ R M × M R^{M\times{M}} RM×M 矩阵。
- 线性变换通常是完全连接的线性层。 D D D 是 Q Q Q 和 K K K 的点积的方差。
- 之后,通过取 Q Q Q 和 K K K 的点积,随后使用标准差和 S o f t m a x Softmax Softmax 函数进行归一化,计算出注意力分数:
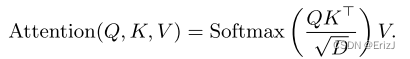
- 这里,注意力分数反映了图像 X X X 中每个像素与其他像素之间的相似性,从而实现了对图像的有效视觉关注。
- 受到注意力机制的启发,作者开发了 BiAtten-Net,如图 1 1 1 所示。
- 作者利用双流网络从高分辨率参考和超分辨率图像中提取特征,同时通过所提出的双向注意力块( B A B BAB BAB)逐步增强信息交互并引导视觉注意力到失真上。
- 这些特征随后被从两个分支组合起来,以预测最终的视觉质量得分。
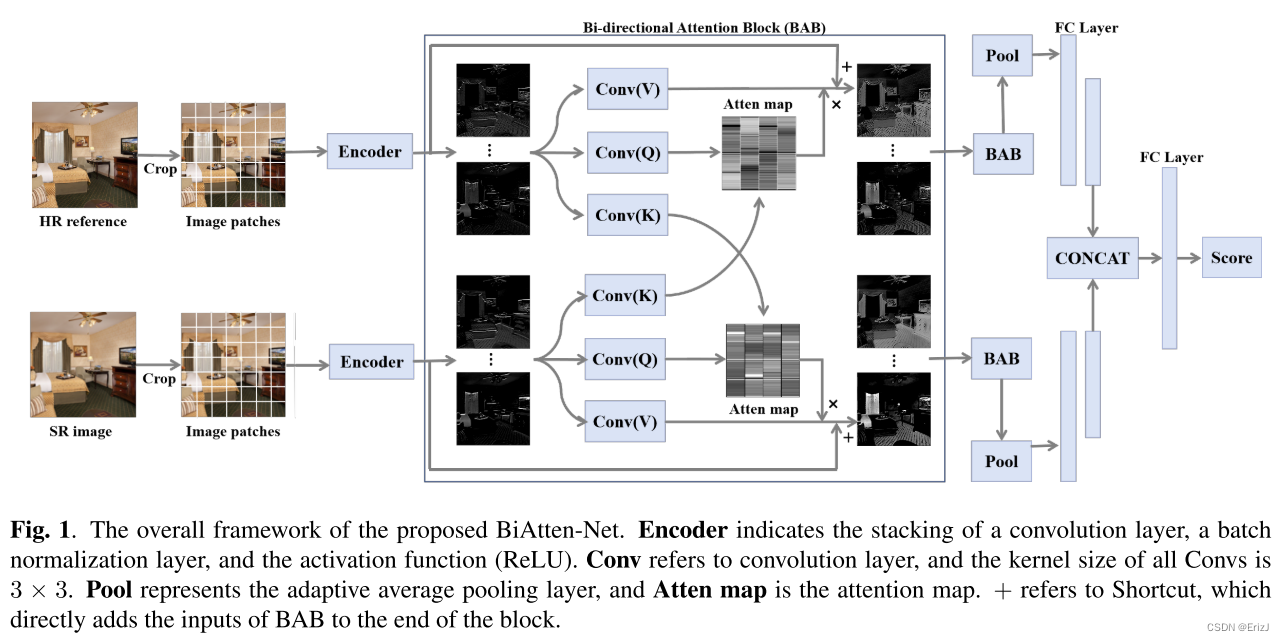
- 编码器表示卷积层、批量归一化层和激活函数( R e L U ReLU ReLU)的堆叠。 C o n v Conv Conv 指的是卷积层,所有 C o n v Conv Conv 的核大小是 3 × 3 3\times{3} 3×3。 P o o l Pool Pool 代表自适应平均池化层, A t t e n Atten Atten m a p map map 是注意力图。 + + + 表示快捷连接,它将 B A B BAB BAB 的输入直接加到块的末端。
- 作者在实验中将图片划分为 32 × 32 32\times{32} 32×32 大小的重叠块。然后采用单个卷积层堆叠,其中包括批量归一化层( B N BN BN)和激活函数( R e L U ReLU ReLU),来初步提取图像块的特征。
- 之后,这些图像块的特征图被输入到所提出的双向注意力块( B A B BAB BAB)。
- 作者分别为两个分支计算 Q Q Q、 K K K 和 V V V 矩阵:
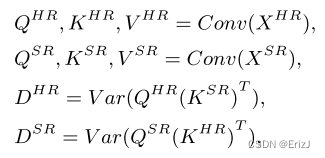
- 其中 X S R ∈ R M × M X_{SR} \in R^{M\times{M}} XSR∈RM×M 和 X H R ∈ R M × M X_{HR} \in R^{M\times{M}} XHR∈RM×M 代表输入到双向注意力块( B A B BAB BAB)的特征图。
- D H R D_{HR} DHR 和 D S R D_{SR} DSR 分别是 Q H R Q_{HR} QHR, K S R K_{SR} KSR 和 Q S R Q_{SR} QSR, K H R K_{HR} KHR 点乘的方差。
- 考虑到线性层的学习能力有限,作者采用卷积层而非线性层来获取 Q Q Q, K K K 和 V V V 矩阵。
- 两个分支的 K H R K_{HR} KHR 和 K S R K_{SR} KSR 矩阵被交换来计算注意力图,如下所示:
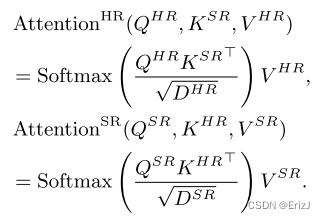
- 通过交换 K S R K_{SR} KSR 和 K H R K_{HR} KHR,生成的注意力图计算了当前分支特征和来自其他分支的特征之间的像素级相似性。
- 通过这种方式,注意力图直接加深了对微妙差异像素(即失真)的视觉关注。
- 考虑到身份快捷方式( I d e n t i t y Identity Identity S h o r t c u t Shortcut Shortcut)已被证明可以有效缓解模型过拟合问题,作者使用快捷方式作为主要架构。
- 通过两个双向注意力块( B A B BAB BAB)之后,两个分支的特征图被展平并通过全连接层连接,以增强信息交互,最终获得感知质量预测。

-
为了直观地证明所提出的方法有效增强了对失真的视觉关注,作者分别可视化了两个分支的中间特征图,如图 2 2 2 所示。
-
可以观察到,高分辨率(HR)参考图像和超分辨率(SR)图像之间的失真集中在“砖块 - SR 图像”的砖块和“花朵 - SR 图像”的花朵的外观上。与 B A B BAB BAB 之前的失真特征图相比, B A B BAB BAB 之后的失真模式明显更清晰。此外,失真的细节显著增加,表明作者提出的双向注意力可以有效增强对失真的视觉关注。
-
进一步阐述了 B i − D i r e c t i o n a l Bi-Directional Bi−Directional A t t e n t i o n Attention Attention B l o c k Block Block( B A B BAB BAB)的有效性是非常有趣的。
-
如前所述,两个分支分别模拟了在超分辨率(SR)图像中产生和评估失真的过程。因此,在理想情况下,通过两个分支之间的持续信息交互,高分辨率(HR)参考图像的特征图可以逐渐近似于 SR 图像,反之亦然。
-
在迭代学习过程中,如果 SR 图像和 HR 参考的特征图在相似性计算上显示出显著的改进,网络便能有效地模拟失真生成和质量评估的过程,从而更全面地评估失真水平。
-
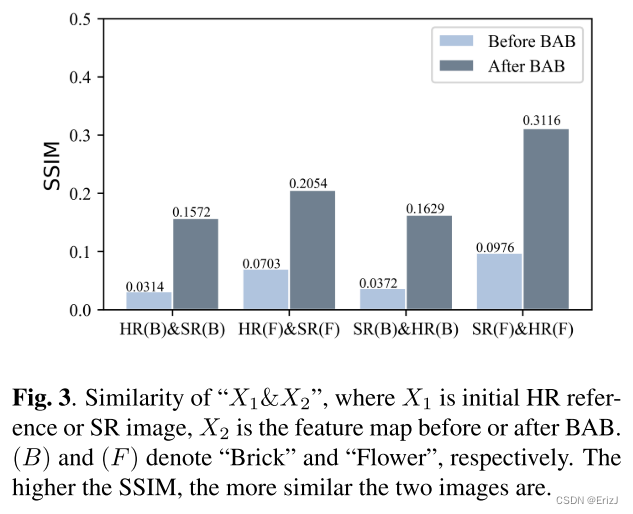
这里,作者计算了 B A B BAB BAB 前后两个分支的特征图之间的相似性(例如,结构相似性指数 S S I M SSIM SSIM),如图 3 3 3 所示。 S S I M SSIM SSIM 用于反映近似水平。
-
可以看到,经过 B A B BAB BAB 的视觉关注后,SR 图像的特征图在与 HR 参考的 S S I M SSIM SSIM 上有了显著的改善。此外,HR 参考的特征图在经过 B A B BAB BAB 后也显示出与 SR 图像显著的 S S I M SSIM SSIM 改善。这表明所提出的方法动态地关注着失真,随着“HR”和“SR”相互转化。
实验结果
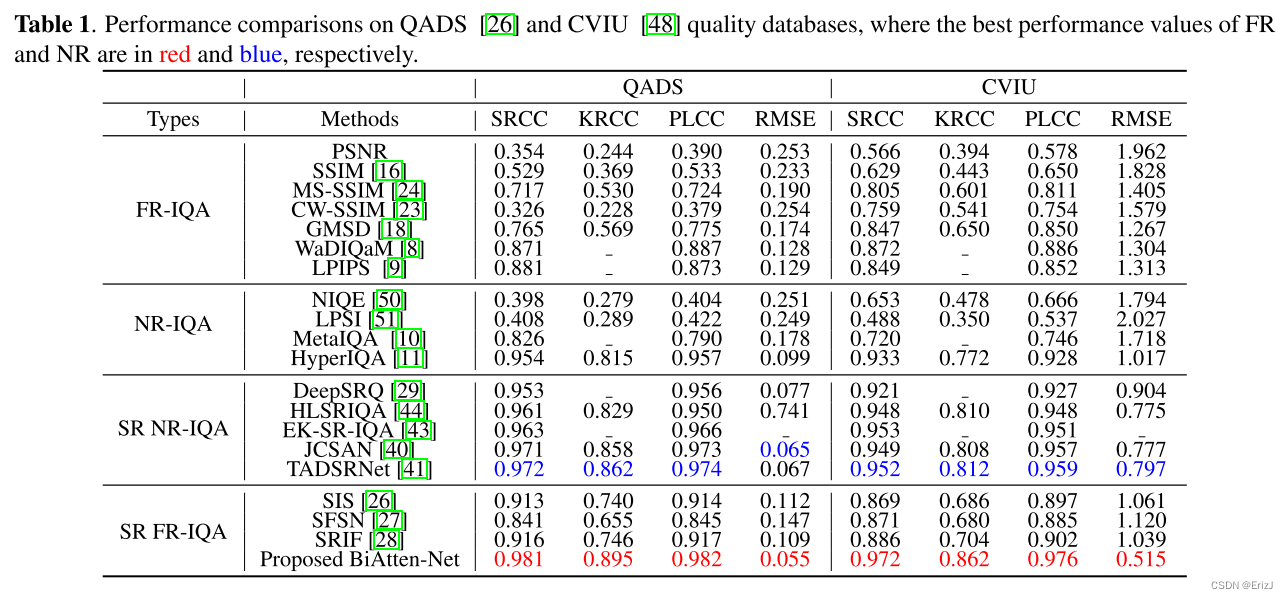
- 基于深度学习的方法表现更好,而 FR-IQA 和 NR-IQA 方法的性能基本上不如 SR IQA 方法,这表明传统的 IQA 方法无法覆盖超分辨率图像的多样化伪影。
- 在 SR IQA 方法中,FR 方法(即 S I S SIS SIS、 S F S N SFSN SFSN、 S R I F SRIF SRIF)仅限于浅层特征,不能充分利用参考图像中的隐藏信息,与基于深度学习的方法相比有显著差距。
- 此外,作者所提出的 BiAtten-Net 在分支之间实现了更大的信息交互,并直接关注失真,有效地利用了参考图像的深层特征。
- 因此,所提出的方法在 Q A D S QADS QADS 和 C V I U CVIU CVIU 数据库上都达到了最佳性能。
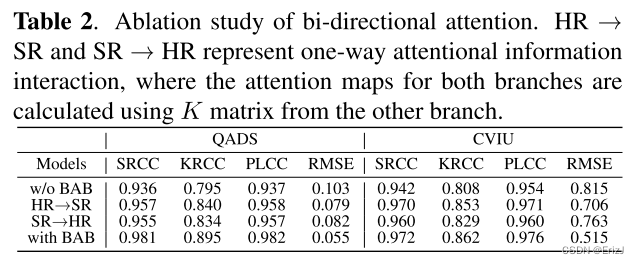
- 为了验证双向注意力块( B A B BAB BAB)中双向信息交互的有效性,作者针对视觉注意力的交互模式进行了消融实验。
- 具体来说,作者验证了以下情况:
- 不使用 B A B BAB BAB(即分别将方程 1 1 1 中的注意力应用于 SR 图像和 HR 参考分支);
- 在应用方程1中的注意力到 SR 图像分支的同时,添加来自 SR 图像分支的注意力信息到 HR 参考分支(即 SR → HR);
- 以及在应用方程 1 1 1 中的注意力到 HR 参考分支的同时,添加来自 HR 参考分支的注意力信息到 SR 图像分支(即 HR → SR)。
- 实验结果表明,不使用 B A B BAB BAB 的模型在两个数据库上的表现最差,即使添加单向注意力信息交互也能显著提升性能。
- 此外, B A B BAB BAB 带来的性能提升在两个数据库上的 K R C C KRCC KRCC 和 R M S E RMSE RMSE 上尤为显著。
- 最终,使用 B A B BAB BAB 的模型取得了最佳性能,表明作者所提出的 B A B BAB BAB 有效地增强了网络的学习能力。


















 3259
3259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











