










这里承接上一篇关于ProGAN的论文精读笔记,记录一下其代码实现细节。
一、初始化
#导入需要的库和包
import argparse
import os
import numpy as np
import time
import datetime
import sys
import torch
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torch.autograd import Variable
def str2bool(v):
if isinstance(v, bool):
return v
if v.lower() in ("yes", "true", "t", "y", "1"):
return True
elif v.lower() in ("no", "false", "f", "n", "0"):
return False
else:
raise argparse.ArgumentTypeError("Boolean value expected.")
parser = argparse.ArgumentParser("Train Progressively grown GAN",
formatter_class=argparse.ArgumentDefaultsHelpFormatter, )
parser.add_argument("--rec_dir", action="store", type=str2bool, default=True,
help="whether images stored under one folder or has a recursive dir structure",
required=False, )
parser.add_argument("--flip_horizontal", action="store", type=str2bool, default=True,
help="whether to apply mirror augmentation", required=False, )
parser.add_argument("--depth", action="store", type=int, default=5,
help="对应generator和discriminator的深度,depth=5适用于渐进训练到32*32网络也就是cifar-10,高分辨率的以此类推是2的n次方n=depth的分辨率", required=False, )
parser.add_argument("--num_channels", action="store", type=int, default=3,
help="输入图像的通道数,默认是RGB三通道", required=False, )
parser.add_argument("--latent_size", action="store", type=int, default=128,
help="generator与discriminator中间的隐层神经元节点个数,如果是高分辨率图像可以改为512", required=False, )
parser.add_argument("--use_eql", action="store", type=str2bool, default=True,
help="控制是否使用均衡学习率策略", required=False, )
parser.add_argument("--use_ema", action="store", type=str2bool, default=True,
help="是否使用指数滑动平均策略", required=False, )
parser.add_argument("--ema_beta", action="store", type=float, default=0.999, help="value of the ema beta",
required=False, )
parser.add_argument("--epochs", action="store", type=int, required=False, nargs="+",
default=[172 for _ in range(9)], help="Mapper network configuration", )
parser.add_argument("--batch_sizes", action="store", type=int, required=False, nargs="+",
default=[512, 256, 128, 128, ], help="Mapper network configuration", )
parser.add_argument("--fade_in_percentages", action="store", type=int, required=False, nargs="+",
default=[50 for _ in range(9)], help="百分之多少的epoch采用平滑过渡也就是渐进式训练的那个阿尔法进行平滑过渡", )
args = parser.parse_known_args()[0]
#该组参数适用于cifar-10数据集
num_epochs = [4, 8, 16, 20] #分别对应渐进式训练的1,2,3,4层epoch数,分辨率越高训练epoch越多
fade_ins = [50, 50, 50, 50] #平滑过度在所有epoch中占比,这里都是前一半进行过度,后一半epoch阿尔法完全变成1
gen_learning_rate = 0.003
dis_learning_rate = 0.003
二、数据加载:
#加载的数据为 256*256 的建筑正面照片和分割图
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
data_path = "../DATA/"
transforms = tv.transforms.Compose(
[tv.transforms.ToTensor(), tv.transforms.Normalize([0.5], [0.5])]
)
trainset = tv.datasets.CIFAR10(root=data_path,
transform=transforms,
download=True)
from torch.utils.data import DataLoader, Dataset
def get_data_loader(dataset: Dataset, batch_size: int, num_workers: int = 3) -> DataLoader:
"""
generate the data_loader from the given dataset
Args:
dataset: Torch dataset object
batch_size: batch size for training
num_workers: num of parallel readers for reading the data
Returns: dataloader for the dataset
"""
return DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True,)
查看一下训练集中的图像
from torch.autograd import Variable
import matplotlib.pyplot as plt
def show_img(img, trans=True):
if trans:
img = np.transpose(img.detach().cpu().numpy(), (1, 2, 0)) # 把channel维度放到最后
plt.imshow(img / 2 + 0.5)
else:
plt.imshow(img)
plt.show()
print(trainset[0])
for i in range(2):
sample = trainset[i]
print(classes[sample[1]])
show_img(sample[0], trans=True)
三、模型
3.1自定义层
3.1.1学习率均衡
使用动态权重缩放
from torch.nn import Conv2d, ConvTranspose2d, Linear
from torch import Tensor
class EqualizedConv2d(Conv2d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
bias=True, padding_mode="zeros", ) -> None:
super().__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias,
padding_mode, )
# make sure that the self.weight and self.bias are initialized according to random normal distribution
torch.nn.init.normal_(self.weight)
if bias:
torch.nn.init.zeros_(self.bias)
# define the scale for the weights:
fan_in = np.prod(self.kernel_size) * self.in_channels
self.scale = np.sqrt(2) / np.sqrt(fan_in)
def forward(self, x: Tensor) -> Tensor:
return torch.conv2d(input=x, weight=self.weight * self.scale, bias=self.bias, stride=self.stride,
padding=self.padding, dilation=self.dilation, groups=self.groups, )
class EqualizedConvTranspose2d(ConvTranspose2d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1,
bias=True, dilation=1, padding_mode="zeros", ) -> None:
super().__init__(in_channels, out_channels, kernel_size, stride, padding, output_padding, groups, bias,
dilation, padding_mode, )
# make sure that the self.weight and self.bias are initialized according to
# random normal distribution
torch.nn.init.normal_(self.weight)
if bias:
torch.nn.init.zeros_(self.bias)
# define the scale for the weights:
fan_in = self.in_channels
self.scale = np.sqrt(2) / np.sqrt(fan_in)
def forward(self, x: Tensor, output_size: Any = None) -> Tensor:
output_padding = self._output_padding(
input, output_size, self.stride, self.padding, self.kernel_size)
return torch.conv_transpose2d(input=x, weight=self.weight * self.scale, bias=self.bias,
stride=self.stride, padding=self.padding, output_padding=output_padding,
groups=self.groups, dilation=self.dilation, )
class EqualizedLinear(Linear):
def __init__(self, in_features, out_features, bias=True) -> None:
super().__init__(in_features, out_features, bias)
# make sure that the self.weight and self.bias are initialized according to
# random normal distribution
torch.nn.init.normal_(self.weight)
if bias:
torch.nn.init.zeros_(self.bias)
# define the scale for the weights:
fan_in = self.in_features
self.scale = np.sqrt(2) / np.sqrt(fan_in)
def forward(self, x: Tensor) -> Tensor:
return torch.nn.functional.linear(x, self.weight * self.scale, self.bias)
3.1.2Minibatch标准差
增加Batch内的标准差feature
class MinibatchStdDev(torch.nn.Module):
"""
Minibatch standard deviation layer for the discriminator
Args:
group_size: Size of each group into which the batch is split
"""
def __init__(self, group_size: int = 4) -> None:
"""
Args:
group_size: 将batchsize切分成group_size个小的mini_batch
"""
super(MinibatchStdDev, self).__init__()
self.group_size = group_size
def extra_repr(self) -> str:
return "group_size={self.group_size}"
def forward(self, x: Tensor, alpha: float = 1e-8) -> Tensor:
"""
forward pass of the layer
Args:
x: input activation volume
alpha: small number for numerical stability
Returns: y => x appended with standard deviation constant map
"""
batch_size, channels, height, width = x.shape
if batch_size > self.group_size:
assert batch_size % self.group_size == 0, (
"batch_size {batch_size} should be "
"perfectly divisible by group_size {self.group_size}"
)
group_size = self.group_size
else:
group_size = batch_size
# reshape x into a more amenable sized tensor
y = torch.reshape(x, [group_size, -1, channels, height, width])
# indicated shapes are after performing the operation
y = y - y.mean(dim=0, keepdim=True) # [G x M x C x H x W] 减去group的平均值
y = torch.sqrt((y * y).mean(dim=0, keepdim=False) + alpha) # [M x C x H x W] 计算每个group的标准偏差
y = y.mean(dim=[1, 2, 3], keepdim=True) # [M x 1 x 1 x 1] 取特征图和像素的平均值
y = y.repeat(group_size, 1, height, width) # [B x 1 x H x W] 复制group和像素
y = torch.cat([x, y], 1) # [B x (C + 1) x H x W] 追加为新的 feature_map.
# return the computed values:
return y
3.1.3 像素归一化
像素级的normalization
class PixelwiseNorm(torch.nn.Module):
def __init__(self):
super(PixelwiseNorm, self).__init__()
@staticmethod
def forward(x: Tensor, alpha: float = 1e-8) -> Tensor:
y = x.pow(2.0).mean(dim=1, keepdim=True).add(alpha).sqrt() # [N1HW] 在channel维度上求平均值,keepdim=true保留了像素维度,再加上一个alpha再开根号,相当于是求出了每个样本,每个像素上的标准差
y = x / y # normalize the input x volume
return y
3.2生成器
从4 * 4 生成到 32 * 32,有4个block,其中1个输出层block,3个general block,使用了pixel-wise normalization,激活函数使用lrelu,使用反卷积和最近邻resize进行上采样
3.2.1General Block
from typing import Any, Dict, Optional
from torch.nn.functional import interpolate
from torch.nn import AvgPool2d, Conv2d, ConvTranspose2d, Embedding, LeakyReLU, Module
class GenGeneralConvBlock(torch.nn.Module):
"""
Module implementing a general convolutional block
Args:
in_channels: number of input channels to the block
out_channels: number of output channels required
use_eql: whether to use equalized learning rate
"""
def __init__(self, in_channels: int, out_channels: int, use_eql: bool) -> None:
super(GenGeneralConvBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = in_channels
self.use_eql = use_eql
ConvBlock = EqualizedConv2d if use_eql else Conv2d
self.conv_1 = ConvBlock(in_channels, out_channels, (3, 3), padding=1, bias=True)
self.conv_2 = ConvBlock(out_channels, out_channels, (3, 3), padding=1, bias=True)
self.pixNorm = PixelwiseNorm()
self.lrelu = LeakyReLU(0.2)
def forward(self, x: Tensor) -> Tensor:
y = interpolate(x, scale_factor=2) #interpolate是插值算法可以上采样也可以下采样,scale_factor=2代表每个维度上采样为原来两倍,某人采用最近邻的算法
y = self.pixNorm(self.lrelu(self.conv_1(y)))
y = self.pixNorm(self.lrelu(self.conv_2(y)))
return y
3.2.2 GenInitialBlock
class GenInitialBlock(Module):
"""
Module implementing the initial block of the input
Args:
in_channels: number of input channels to the block
out_channels: number of output channels of the block
use_eql: whether to use equalized learning rate
"""
def __init__(self, in_channels: int, out_channels: int, use_eql: bool) -> None:
super(GenInitialBlock, self).__init__()
self.use_eql = use_eql
ConvBlock = EqualizedConv2d if use_eql else Conv2d
ConvTransposeBlock = EqualizedConvTranspose2d if use_eql else ConvTranspose2d
self.conv_1 = ConvTransposeBlock(in_channels, out_channels, (4, 4), bias=True)
self.conv_2 = ConvBlock(
out_channels, out_channels, (3, 3), padding=1, bias=True
)
self.pixNorm = PixelwiseNorm()
self.lrelu = LeakyReLU(0.2)
def forward(self, x: Tensor) -> Tensor:
y = torch.unsqueeze(torch.unsqueeze(x, -1), -1)
y = self.pixNorm(y) # normalize the latents to hypersphere
y = self.lrelu(self.conv_1(y))
y = self.lrelu(self.conv_2(y))
y = self.pixNorm(y)
return y
3.2.3 计算feature map的函数
from torch.nn import Conv2d, ModuleList
def nf(stage: int, fmap_base: int = 16 << 10, fmap_decay: float = 1.0, fmap_min: int = 1,
fmap_max: int = 512,) -> int:
"""
computes the number of fmaps present in each stage
Args:
stage: stage level
fmap_base: base number of fmaps
fmap_decay: decay rate for the fmaps in the network
fmap_min: minimum number of fmaps
fmap_max: maximum number of fmaps
Returns: number of fmaps that should be present there
"""
return int(np.clip(int(fmap_base / (2.0 ** (stage * fmap_decay))), fmap_min, fmap_max,).item())
class Generator(torch.nn.Module):
"""
Generator Module (block) of the GAN network
Args:
depth: required depth of the Network
num_channels: number of output channels (default = 3 for RGB)
latent_size: size of the latent manifold
use_eql: whether to use equalized learning rate
"""
def __init__(self, depth: int = 10, num_channels: int = 3, latent_size: int = 512,
use_eql: bool = True,) -> None:
super().__init__()
# object state:
self.depth = depth
self.latent_size = latent_size
self.num_channels = num_channels
self.use_eql = use_eql
ConvBlock = EqualizedConv2d if use_eql else Conv2d
self.layers = ModuleList([GenInitialBlock(latent_size, nf(1), use_eql=self.use_eql)])
for stage in range(1, depth - 1):
self.layers.append(GenGeneralConvBlock(nf(stage), nf(stage + 1), use_eql))
self.rgb_converters = ModuleList(
[ConvBlock(nf(stage), num_channels, kernel_size=(1, 1)) for stage in range(1, depth)])
def forward(self, x: Tensor, depth: int, alpha: float) -> Tensor:
"""
forward pass of the Generator
Args:
x: input latent noise
depth: depth from where the network's output is required
alpha: value of alpha for fade-in effect
Returns: generated images at the give depth's resolution
"""
assert depth <= self.depth, "Requested output depth {depth} cannot be produced"
if depth == 2:
y = self.rgb_converters[0](self.layers[0](x))
else:
y = x
for layer_block in self.layers[: depth - 2]:
y = layer_block(y)
residual = interpolate(self.rgb_converters[depth - 3](y), scale_factor=2)
straight = self.rgb_converters[depth - 2](self.layers[depth - 2](y))
y = (alpha * straight) + ((1 - alpha) * residual)
return y
def get_save_info(self) -> Dict[str, Any]:
return {
"conf": {
"depth": self.depth,
"num_channels": self.num_channels,
"latent_size": self.latent_size,
"use_eql": self.use_eql,
},
"state_dict": self.state_dict(),
}
generator = Generator(depth=args.depth, num_channels=args.num_channels, latent_size=args.latent_size,
use_eql=args.use_eql,)
print(generator)
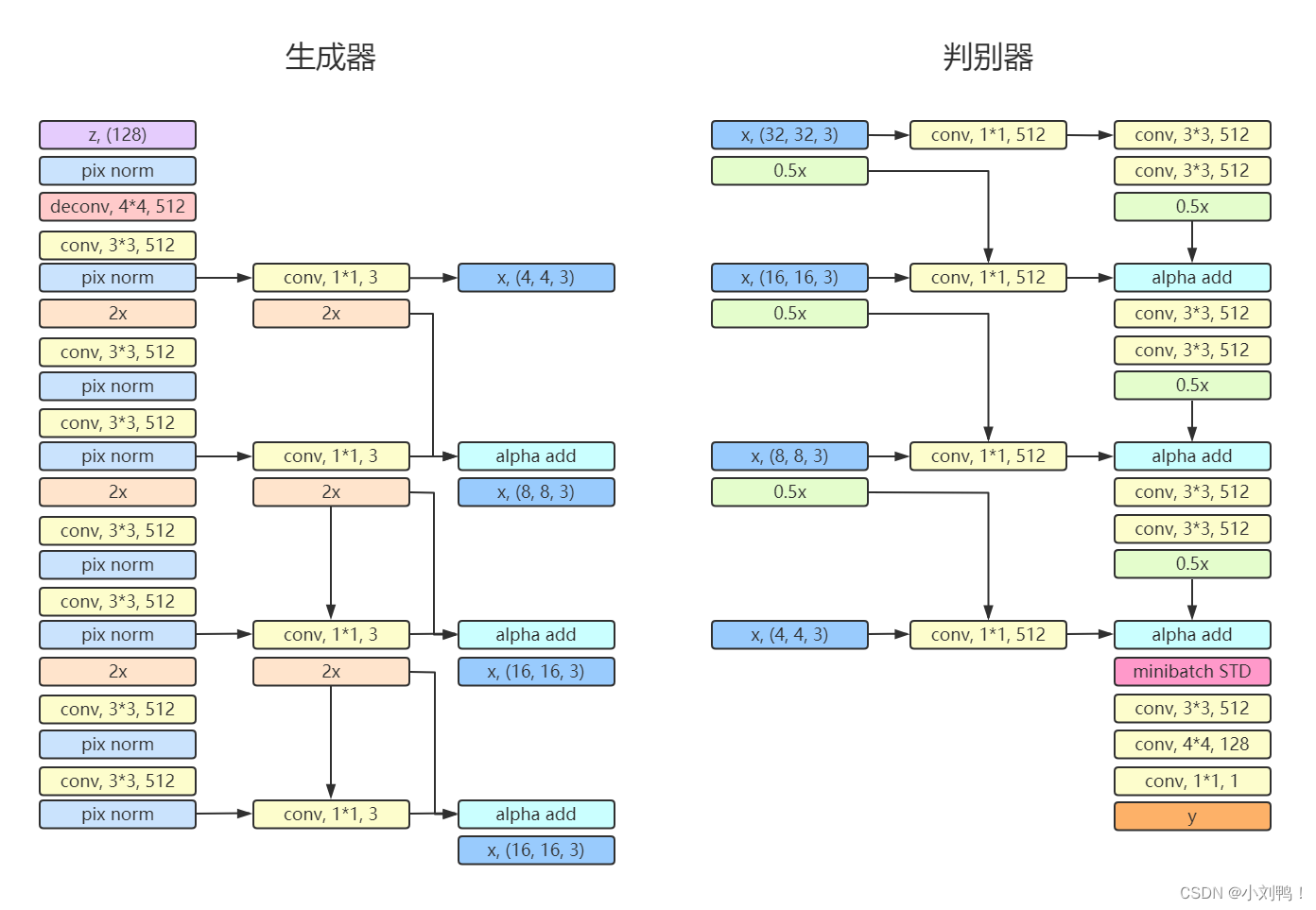
3.3判别器
输入从 4 * 4 到 32 * 32,同样有4个block,其中1个输出层block,3个general block,使用了minibtach STD层,激活函数使用lrelu,使用avg pool进行下采样
3.3.1 DisGenralConvBlock
class DisGeneralConvBlock(torch.nn.Module):
"""
General block in the discriminator
Args:
in_channels: number of input channels
out_channels: number of output channels
use_eql: whether to use equalized learning rate
"""
def __init__(self, in_channels: int, out_channels: int, use_eql: bool) -> None:
super(DisGeneralConvBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.use_eql = use_eql
ConvBlock = EqualizedConv2d if use_eql else Conv2d
self.conv_1 = ConvBlock(in_channels, in_channels, (3, 3), padding=1, bias=True)
self.conv_2 = ConvBlock(in_channels, out_channels, (3, 3), padding=1, bias=True)
self.downSampler = AvgPool2d(2)
self.lrelu = LeakyReLU(0.2)
def forward(self, x: Tensor) -> Tensor:
y = self.lrelu(self.conv_1(x))
y = self.lrelu(self.conv_2(y))
y = self.downSampler(y)
return y
3.3.2 DisFinalBlock 判别器输出层
class DisFinalBlock(torch.nn.Module):
"""
Final block for the Discriminator
Args:
in_channels: number of input channels
use_eql: whether to use equalized learning rate
"""
def __init__(self, in_channels: int, out_channels: int, use_eql: bool) -> None:
super(DisFinalBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.use_eql = use_eql
ConvBlock = EqualizedConv2d if use_eql else Conv2d
self.conv_1 = ConvBlock(
in_channels + 1, in_channels, (3, 3), padding=1, bias=True
)
#这里的输出层Block第一层采用了minibatch多插入了一个channels来增加图像生成的多样性
self.conv_2 = ConvBlock(in_channels, out_channels, (4, 4), bias=True)
self.conv_3 = ConvBlock(out_channels, 1, (1, 1), bias=True)
self.batch_discriminator = MinibatchStdDev()
self.lrelu = LeakyReLU(0.2)
def forward(self, x: Tensor) -> Tensor:
y = self.batch_discriminator(x)
y = self.lrelu(self.conv_1(y))
y = self.lrelu(self.conv_2(y))
y = self.conv_3(y)
return y.view(-1)
3.3.3 Discriminator 判别器构建
class Discriminator(torch.nn.Module):
"""
Discriminator of the GAN
Args:
depth: depth of the discriminator. log_2(resolution)
num_channels: number of channels of the input images (Default = 3 for RGB)
latent_size: latent size of the final layer
use_eql: whether to use the equalized learning rate
num_classes: number of classes for a conditional discriminator (Default = None)
meaning unconditional discriminator
"""
def __init__(
self, depth: int = 7, num_channels: int = 3, latent_size: int = 512, use_eql: bool = True,
num_classes: Optional[int] = None,) -> None:
super().__init__()
self.depth = depth
self.num_channels = num_channels
self.latent_size = latent_size
self.use_eql = use_eql
self.num_classes = num_classes
ConvBlock = EqualizedConv2d if use_eql else Conv2d
self.layers = [DisFinalBlock(nf(1), latent_size, use_eql)]
for stage in range(1, depth - 1):
self.layers.insert(0, DisGeneralConvBlock(nf(stage + 1), nf(stage), use_eql))
self.layers = ModuleList(self.layers)
self.from_rgb = ModuleList(
reversed([ConvBlock(num_channels, nf(stage), kernel_size=(1, 1)) for stage in range(1, depth)]))
def forward(self, x: Tensor, depth: int, alpha: float) -> Tensor:
"""
forward pass of the discriminator
Args:
x: input to the network
depth: current depth of operation (Progressive GAN)
alpha: current value of alpha for fade-in
labels: labels for conditional discriminator (Default = None)
shape => (Batch_size,) shouldn't be a column vector
Returns: raw discriminator scores
"""
assert (depth <= self.depth), "Requested output depth {depth} cannot be evaluated"
#这里当depth>2时,也就是生成8*8的图像,就需要有一个residual和straight的部分的线性叠加,其中叠加的系数是alpha然后通过一个DisGeneralConvBlock
if depth > 2:
residual = self.from_rgb[-(depth - 2)](avg_pool2d(x, kernel_size=2, stride=2))
straight = self.layers[-(depth - 1)](self.from_rgb[-(depth - 1)](x))
y = (alpha * straight) + ((1 - alpha) * residual)
for layer_block in self.layers[-(depth - 2) : -1]:
y = layer_block(y)
else:
y = self.from_rgb[-1](x)
y = self.layers[-1](y)
return y
def get_save_info(self) -> Dict[str, Any]:
return {
"conf": {
"depth": self.depth,
"num_channels": self.num_channels,
"latent_size": self.latent_size,
"use_eql": self.use_eql,
"num_classes": self.num_classes,
},
"state_dict": self.state_dict(),
}
discriminator = Discriminator(depth=args.depth, num_channels=args.num_channels, latent_size=args.latent_size,
use_eql=args.use_eql,)
print(discriminator)
四、损失函数
使用 WGAN-GP loss
class WganGP(GANLoss):
"""
Wgan-GP loss function. The discriminator is required for computing the gradient
penalty.
Args:
drift: weight for the drift penalty
"""
def __init__(self, drift: float = 0.001) -> None:
self.drift = drift
@staticmethod
def _gradient_penalty(dis: Discriminator, real_samples: Tensor, fake_samples: Tensor, depth: int,
alpha: float, reg_lambda: float = 10, labels: Optional[Tensor] = None, ) -> Tensor:
"""
private helper for calculating the gradient penalty
Args:
dis: the discriminator used for computing the penalty
real_samples: real samples
fake_samples: fake samples
depth: current depth in the optimization
alpha: current alpha for fade-in
reg_lambda: regularisation lambda
Returns: computed gradient penalty
"""
batch_size = real_samples.shape[0]
# generate random epsilon
epsilon = torch.rand((batch_size, 1, 1, 1)).to(real_samples.device)
# create the merge of both real and fake samples
merged = epsilon * real_samples + ((1 - epsilon) * fake_samples)
merged.requires_grad_(True)
# forward pass
op = dis(merged, depth, alpha)
# perform backward pass from op to merged for obtaining the gradients
gradient = torch.autograd.grad(outputs=op, inputs=merged, grad_outputs=torch.ones_like(op),
create_graph=True, retain_graph=True, only_inputs=True, )[0]
# calculate the penalty using these gradients
gradient = gradient.view(gradient.shape[0], -1)
penalty = reg_lambda * ((gradient.norm(p=2, dim=1) - 1) ** 2).mean()
# return the calculated penalty:
return penalty
def dis_loss(self, discriminator: Discriminator, real_samples: Tensor, fake_samples: Tensor, depth: int,
alpha: float, labels: Optional[Tensor] = None, ) -> Tensor:
real_scores = discriminator(real_samples, depth, alpha)
fake_scores = discriminator(fake_samples, depth, alpha)
loss = (torch.mean(fake_scores) - torch.mean(real_scores) + (self.drift * torch.mean(real_scores ** 2)))
# calculate the WGAN-GP (gradient penalty)
gp = self._gradient_penalty(discriminator, real_samples, fake_samples, depth, alpha)
loss += gp
return loss
def gen_loss(self, discriminator: Discriminator, _: Tensor, fake_samples: Tensor, depth: int, alpha: float,
labels: Optional[Tensor] = None, ) -> Tensor:
fake_scores = discriminator(fake_samples, depth, alpha)
return -torch.mean(fake_scores)
loss_fn = WganGP()
五、Cuda加速
cuda = True if torch.cuda.is_available() else False
print("cuda_is_available =", cuda)
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
device = torch.device("cuda" if cuda else "cpu")
六、优化器
gen_optim = torch.optim.Adam(
params=generator.parameters(),
lr=gen_learning_rate,
betas=(0, 0.99),
eps=1e-8,
)
dis_optim = torch.optim.Adam(
params=discriminator.parameters(),
lr=dis_learning_rate,
betas=(0, 0.99),
eps=1e-8,
)
七、正/反向传播
分别对生成器和判别器计算loss,使用反向传播更新模型参数
from torch.nn.functional import avg_pool2d, interpolate
def progressive_downsample_batch(real_batch, depth, alpha):
"""
private helper for downsampling the original images in order to facilitate the
progressive growing of the layers.
Args:
real_batch: batch of real samples
depth: depth at which training is going on
alpha: current value of the fader alpha
Returns: modified real batch of samples
"""
# downsample the real_batch for the given depth
down_sample_factor = int(2 ** (generator.depth - depth))
prior_downsample_factor = int(2 ** (generator.depth - depth + 1))
ds_real_samples = avg_pool2d(real_batch, kernel_size=down_sample_factor, stride=down_sample_factor)
if depth > 2:
prior_ds_real_samples = interpolate(
avg_pool2d(real_batch, kernel_size=prior_downsample_factor, stride=prior_downsample_factor,),
scale_factor=2, )
else:
prior_ds_real_samples = ds_real_samples
# real samples are a linear combination of ds_real_samples and prior_ds_real_samples
real_samples = (alpha * ds_real_samples) + ((1 - alpha) * prior_ds_real_samples)
return real_samples
from torch.optim.optimizer import Optimizer
def optimize_discriminator(loss: GANLoss, dis_optim: Optimizer, noise: Tensor, real_batch: Tensor,
depth: int, alpha: float, labels: Optional[Tensor] = None, ) -> float:
"""
performs a single weight update step on discriminator using the batch of data
and the noise
Args:
loss: the loss function to be used for the optimization
dis_optim: discriminator optimizer
noise: input noise for sample generation
real_batch: real samples batch
depth: current depth of optimization
alpha: current alpha for fade-in
labels: labels for conditional discrimination
Returns: discriminator loss value
"""
real_samples = progressive_downsample_batch(real_batch, depth, alpha)
# generate a batch of samples
fake_samples = generator(noise, depth, alpha).detach()
dis_loss = loss.dis_loss(discriminator, real_samples, fake_samples, depth, alpha)
# optimize discriminator
dis_optim.zero_grad()
dis_loss.backward()
dis_optim.step()
return dis_loss.item()
def optimize_generator(loss: GANLoss, gen_optim: Optimizer, noise: Tensor, real_batch: Tensor, depth: int,
alpha: float, labels: Optional[Tensor] = None, ) -> float:
"""
performs a single weight update step on generator using the batch of data
and the noise
Args:
loss: the loss function to be used for the optimization
gen_optim: generator optimizer
noise: input noise for sample generation
real_batch: real samples batch
depth: current depth of optimization
alpha: current alpha for fade-in
labels: labels for conditional discrimination
Returns: generator loss value
"""
real_samples = progressive_downsample_batch(real_batch, depth, alpha)
print()
print("-------------------------------------")
print("real_samples_downsample:")
print(real_samples.shape)
show_img(real_samples[0])
# generate fake samples:
fake_samples = generator(noise, depth, alpha)
print("fake_samples:")
print(fake_samples.shape)
show_img(fake_samples[0])
gen_loss = loss.gen_loss(discriminator, real_samples, fake_samples, depth, alpha)
# optimize the generator
gen_optim.zero_grad()
gen_loss.backward()
gen_optim.step()
return gen_loss.item()
八、模型训练
分别从数据集和随机向量中获取输入,并进行训练
import timeit
print("Starting the training process ... ")
start_depth = 2
num_workers = 0
batch_repeats = 2
batch_sizes = args.batch_sizes
epochs = num_epochs
dataset = trainset
fade_in_percentages = fade_ins
global_step = 0
global_time = 0
for current_depth in range(start_depth, generator.depth + 1):
current_res = int(2 ** current_depth)
print("\n\nCurrently working on Depth: {current_depth}")
print("Current resolution: %d x %d" % (current_res, current_res))
depth_list_index = current_depth - 2
current_batch_size = batch_sizes[depth_list_index]
data = get_data_loader(dataset, current_batch_size, num_workers)
ticker = 1
for epoch in range(1, epochs[depth_list_index] + 1):
start = timeit.default_timer() # record time at the start of epoch
print("\nEpoch: {epoch}")
total_batches = len(data)
# compute the fader point
fader_point = int((
fade_in_percentages[depth_list_index] / 100) * epochs[depth_list_index] * total_batches)
for (i, batch) in enumerate(data, start=1):
# calculate the alpha for fading in the layers
alpha = ticker / fader_point if ticker <= fader_point else 1
# extract current batch of data for training
print("label =", classes[batch[1][0]])
show_img(batch[0][0], True)
batch = batch[0]
images = batch.to(device)
gan_input = torch.randn(current_batch_size, generator.latent_size).to(device)
print("z.shape =", gan_input.shape)
gen_loss, dis_loss = None, None
for _ in range(batch_repeats):
dis_loss = optimize_discriminator(loss_fn, dis_optim, gan_input, images, current_depth, alpha)
gen_loss = optimize_generator(loss_fn, gen_optim, gan_input, images, current_depth, alpha)
print("gen_loss =", gen_loss)
print("dis_loss =", dis_loss)
global_step += 1
print()
# log 输出
if (i == 1):
elapsed = time.time() - global_time
elapsed = str(datetime.timedelta(seconds=elapsed))
print("Elapsed: [%s] batch: %d d_loss: %f g_loss: %f" % (elapsed, i, dis_loss, gen_loss))
# increment the alpha ticker and the step
ticker += 1
break
stop = timeit.default_timer()
print("Time taken for epoch: %.3f secs" % (stop - start))
break
break















 5241
5241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









