







图函数
我们知道,互相连接的节点可以构成一个图,其中包含所有节点构成的集合V,和所有边构成的集合E。
对于实数域上的函数
y
=
f
(
x
)
y=f(x)
y=f(x), 我们可以理解为一种对于x的映射,将每个可能的
x
∈
X
x\in X
x∈X 映射到一个对应的
y
∈
Y
y\in Y
y∈Y。
相应地,我们也可以定义一个函数
F
G
:
V
→
R
F_G: V \rightarrow R
FG:V→R,使得图上的每一个节点
v
∈
V
v \in V
v∈V,都被映射到一个实数
R
R
R上。
图函数的梯度
我们记得,梯度的意义在于,衡量函数在每一个点处,在每个正交方向上的变化,如
f
(
x
,
y
,
z
)
f(x,y,z)
f(x,y,z)的梯度在
x
x
x方向的分量
∂
f
∂
x
=
f
(
x
+
d
x
)
−
f
(
x
)
(
x
+
d
x
)
−
x
\frac{\partial f}{\partial x}=\frac{f(x+dx)-f(x)}{(x+dx)-x}
∂x∂f=(x+dx)−xf(x+dx)−f(x)
在图论中,我们认为一个节点沿着每一条边通向它的相邻节点,而每两条边之间互相并没有什么关系,也就是说我们认为这个节点的每一条边都是互相正交的。并且对于两个节点,我们定义其距离d为其边权值的倒数。那么对于一个节点
v
0
v_0
v0,我们认为其梯度在一条通向
v
1
v_1
v1的边
e
01
e_{01}
e01上的分量为
F
G
(
v
0
)
−
F
G
(
v
1
)
d
01
=
(
F
G
(
v
0
)
−
F
G
(
v
1
)
⋅
e
01
)
\frac{F_G(v_0)-F_G(v_1)}{d_{01}}=(F_G(v_0)-F_G(v_1)\cdot e_{01})
d01FG(v0)−FG(v1)=(FG(v0)−FG(v1)⋅e01)
(其中
d
01
d_{01}
d01为
v
0
v_0
v0到
v
1
v_1
v1的距离,
e
01
e_{01}
e01为该边的权重)。
拉普拉斯矩阵
直接套用导数的定义,无法直观理解拉普拉斯矩阵的物理意义,从散度入手,才是正确的打开方式。
梯度(矢量)
梯度“
∇
\nabla
∇”的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该方向处沿着该方向(此梯度方向)变化最快,变化率最大(为该梯度的摸)。假设一个三原函数
u
=
f
(
x
,
y
,
z
)
u=f(x,y,z)
u=f(x,y,z)在空间区域
G
G
G内具有一阶连续偏导数,点
P
(
x
,
y
,
z
)
∈
G
P(x,y,z) \in G
P(x,y,z)∈G,称向量
{
∂
f
∂
x
,
∂
f
∂
y
,
∂
f
∂
z
}
=
∂
f
∂
x
i
⃗
+
∂
f
∂
y
j
⃗
+
∂
f
∂
z
k
⃗
\{\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y}, \frac{\partial f}{\partial z} \} = \frac{\partial f}{\partial x} \vec{i} + \frac{\partial f}{\partial y} \vec{j}+\frac{\partial f}{\partial z} \vec{k}
{∂x∂f,∂y∂f,∂z∂f}=∂x∂fi+∂y∂fj+∂z∂fk
为函数
u
=
f
(
x
,
y
,
z
)
u=f(x,y,z)
u=f(x,y,z)在点
P
P
P处的梯度,记为
g
r
a
d
f
(
x
,
y
,
z
)
gradf(x,y,z)
gradf(x,y,z)或
∇
f
(
x
,
y
,
z
)
\nabla f(x,y,z)
∇f(x,y,z), 其中,
∇
=
∂
f
∂
x
i
⃗
+
∂
f
∂
y
j
⃗
+
∂
f
∂
z
k
⃗
\nabla=\frac{\partial f}{\partial x} \vec{i} + \frac{\partial f}{\partial y} \vec{j}+\frac{\partial f}{\partial z} \vec{k}
∇=∂x∂fi+∂y∂fj+∂z∂fk
成为向量的微分算子或Nabla算子。
散度(标量)
散度“ ∇ ⋅ \nabla \cdot ∇⋅”(divergence)可用于表针空间各点矢量场发散的强弱程度,物理上,散度的意义是场的有源性。当 d i v ( F ) > 0 div(F)>0 div(F)>0, 表示该点有散发通量的正源(发散源);当 d i v ( F ) < 0 div(F)<0 div(F)<0表示该点有吸收能量的负源(洞或汇);当 d i v ( F ) = 0 div(F)=0 div(F)=0,表示该点无源。
拉普拉斯算子
拉普拉斯算子(Laplace Operator)是
n
n
n维欧几里得空间中的一个二阶微分算子,定义为梯度(
∇
f
\nabla f
∇f)的散度(
∇
⋅
\nabla \cdot
∇⋅)。
Δ
f
=
∇
2
f
=
∇
⋅
∇
f
=
d
i
v
(
g
r
a
d
f
)
\Delta f=\nabla^2f=\nabla \cdot \nabla f=div(gradf)
Δf=∇2f=∇⋅∇f=div(gradf)
笛卡尔坐标系下的表示法:
Δ
f
=
∂
2
f
∂
x
2
+
∂
2
f
∂
y
2
+
∂
2
f
∂
z
2
\Delta f=\frac{\partial^2f}{\partial x^2} + \frac{\partial^2f}{\partial y^2}+\frac{\partial^2f}{\partial z^2}
Δf=∂x2∂2f+∂y2∂2f+∂z2∂2f
n
n
n维形式
Δ
=
∑
i
∂
2
∂
x
i
2
\Delta=\sum_i\frac{\partial^2}{\partial x^2_i}
Δ=∑i∂xi2∂2
离散函数的导数
∂
f
∂
x
=
f
′
(
x
)
≈
f
(
x
+
1
)
−
f
(
x
)
\frac{\partial f}{\partial x}=f'(x) \approx f(x+1)-f(x)
∂x∂f=f′(x)≈f(x+1)−f(x)
∂
2
f
∂
x
2
=
f
′
′
(
x
)
≈
f
′
(
x
+
1
)
−
f
′
(
x
)
=
f
(
x
+
1
)
+
f
(
x
−
1
)
−
2
f
(
x
)
\frac{\partial^2 f}{\partial x^2}=f''(x) \approx f'(x+1)-f'(x)=f(x+1)+f(x-1)-2f(x)
∂x2∂2f=f′′(x)≈f′(x+1)−f′(x)=f(x+1)+f(x−1)−2f(x)
则我们可以将拉普拉斯算子也转化为离散形式(以二维为例)
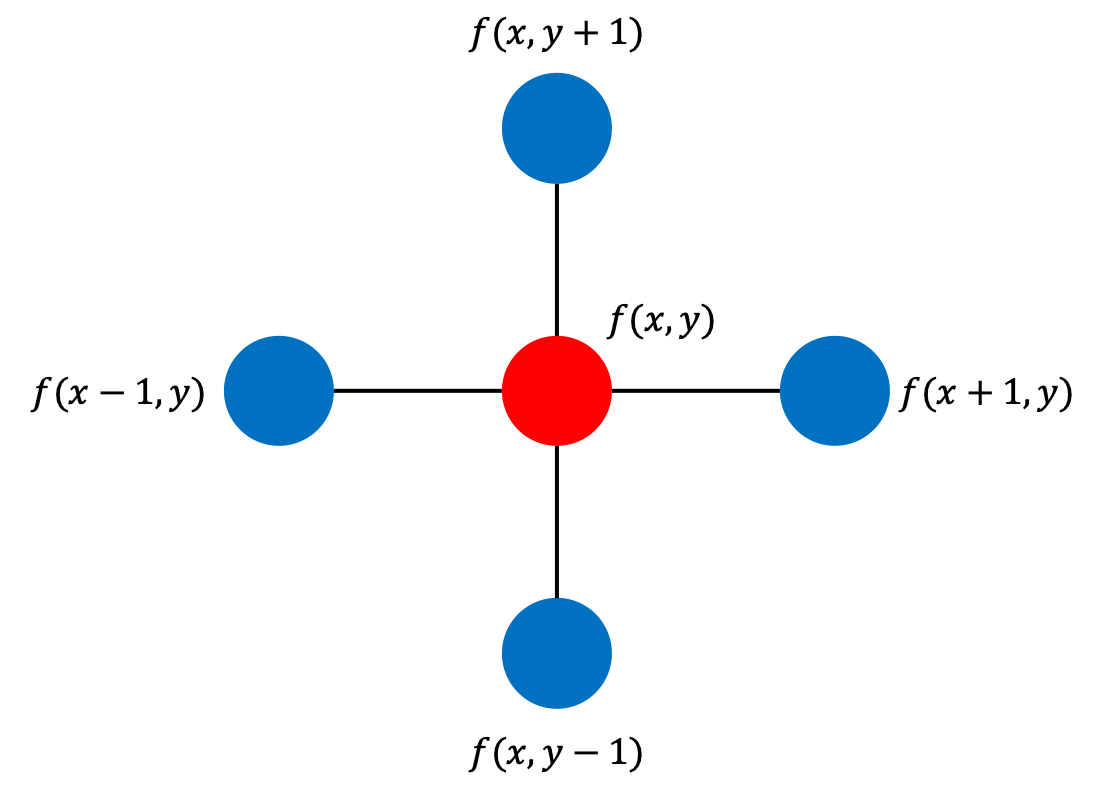
Δ f = ∂ 2 f ∂ x 2 + ∂ 2 ∂ y 2 = f ( x + 1 , y ) + f ( x − 1 , y ) − 2 f ( x , y ) + f ( x , y + 1 ) + f ( x , y − 1 ) − 2 f ( x , y ) = f ( x + 1 , y ) + f ( x − 1 , y ) + f ( x , y + 1 ) + f ( x , y − 1 ) − 4 f ( x , y ) \Delta f= \frac{\partial^2f}{\partial x^2}+\frac{\partial^2}{\partial y^2}\\=f(x+1,y) +f(x-1,y)-2f(x,y)+f(x,y+1)+f(x,y-1)-2f(x,y)\\=f(x+1,y)+f(x-1,y)+f(x,y+1)+f(x,y-1)-4f(x,y) Δf=∂x2∂2f+∂y2∂2=f(x+1,y)+f(x−1,y)−2f(x,y)+f(x,y+1)+f(x,y−1)−2f(x,y)=f(x+1,y)+f(x−1,y)+f(x,y+1)+f(x,y−1)−4f(x,y)
现在用散度的概念解读一下
如果
Δ
f
=
0
\Delta f=0
Δf=0,可以近似认为中心点
f
(
x
,
y
)
f(x,y)
f(x,y)的势和其周围点的势是相等的,
f
(
x
,
y
)
f(x,y)
f(x,y)局部范围内不存在势差,所以该点无源。
如果
Δ
f
>
0
\Delta f>0
Δf>0,可以近似认为中心点
f
(
x
,
y
)
f(x,y)
f(x,y)的势低于周围点,可以想象成中心点如恒星一样发出能量,补给周围的点,所以该点是正源。
如果
Δ
f
<
0
\Delta f<0
Δf<0,可以近似认为中心点
f
(
x
,
y
)
f(x,y)
f(x,y)的势高于周围点,可以想象成中心点如黑洞一样在吸收能量,所以该点是负源。
两一个角度,拉普拉斯算子计算量周围点与中心点的梯度差。当 f ( x , y ) f(x,y) f(x,y)收到扰动之后,其可能变为相邻的 f ( x − 1 , y ) , f ( x + 1 , y ) , f ( x , y − 1 ) , f ( x , y + 1 ) f(x-1,y),f(x+1,y),f(x,y-1),f(x,y+1) f(x−1,y),f(x+1,y),f(x,y−1),f(x,y+1)之一,拉普拉斯算子得到的是对该店进行微小扰动后可能收获的总增益(或者说是变化)。
我们现在将这个结论推广到图:假设具有
N
N
N个节点的图
G
G
G,此时以上定义的函数不再是二维,而是
N
N
N维向量:
f
=
(
f
1
,
f
2
,
.
.
.
,
f
N
)
f=(f_1,f_2,...,f_N)
f=(f1,f2,...,fN),其中
f
i
f_i
fi为函数
f
f
f在图中节点
i
i
i处的函数值。类比于
f
(
x
,
y
)
f(x,y)
f(x,y)在节点(x,y)处的值。对
i
i
i节点进行扰动,它可能变为任意一个与它相邻的节点
j
∈
N
i
j \in N_i
j∈Ni,
N
i
N_i
Ni表示节点i的一阶领域节点。
我们上面已经知道拉普拉斯算子可以计算一个点到它所有自由度上微小扰动的增益,通过图来表示就是任意一个节点
j
j
j变化到节点
i
i
i所带来的增益,考虑图中边的全职相等(简单说就是1)则有:
Δ
f
i
=
∑
j
∈
N
i
(
f
i
−
f
j
)
\Delta f_i=\sum_{j\in N_i}(f_i-f_j)
Δfi=∑j∈Ni(fi−fj)
而如果边E_{ij}具有权重W_{ij}时,则有:
Δ
f
i
=
∑
j
∈
N
j
W
i
j
(
f
i
−
f
j
)
\Delta f_i=\sum_{j\in N_j}W_{ij}(f_i-f_j)
Δfi=∑j∈NjWij(fi−fj)
由于当W_{ij}=0是表示节点
i
i
i,
j
j
j不相邻,所以上式可以简化为:
Δ
f
i
=
∑
j
∈
N
(
f
i
−
f
j
)
\Delta f_i=\sum_{j \in N}(f_i-f_j)
Δfi=∑j∈N(fi−fj)
继续推导有:
Δ
f
i
=
∑
j
∈
N
W
i
j
(
f
i
−
f
j
)
=
∑
j
∈
N
W
i
j
f
i
−
∑
j
∈
N
W
i
j
f
j
=
d
i
f
i
−
w
i
:
f
\Delta f_i = \sum_{j \in N}W_{ij}(f_i-f_j)\\=\sum_{j\in N}W_{ij}f_i-\sum_{j \in N}W_{ij}f_j\\=d_if_i-w_{i:}f
Δfi=∑j∈NWij(fi−fj)=∑j∈NWijfi−∑j∈NWijfj=difi−wi:f
其中
d
i
=
∑
j
∈
N
W
i
j
d_i=\sum_{j\in N}W_{ij}
di=∑j∈NWij是顶点
i
i
i的度;
W
i
:
=
(
W
i
1
,
.
.
.
W
i
N
)
W_i:=(W_{i1},...W_{iN})
Wi:=(Wi1,...WiN)是
N
N
N维的行向量,
f
=
(
f
i
.
.
.
f
N
)
f=\begin{pmatrix} f_i\\ .\\.\\.\\f_N \end{pmatrix}
f=⎝⎜⎜⎜⎜⎛fi...fN⎠⎟⎟⎟⎟⎞是N维的列向量;
W
i
:
f
W_{i:}f
Wi:f表示两个向量的内积。
对于所有的N节点有
Δ
f
=
(
Δ
f
1
.
.
.
Δ
f
N
)
=
(
d
1
f
1
−
W
1
:
f
.
.
.
d
N
f
N
−
W
N
:
f
)
=
(
d
1
⋅
⋅
⋅
0
.
.
.
.
.
.
.
.
.
0
⋅
⋅
⋅
d
N
)
f
−
(
W
1
:
.
.
.
W
N
:
)
=
d
i
a
g
(
d
i
)
f
−
W
f
=
(
D
−
W
)
f
=
L
f
\Delta f=\begin{pmatrix}\Delta f_1\\.\\.\\.\\ \Delta f_N\end{pmatrix}\\=\begin{pmatrix}d_1f_1-W_{1:}f\\.\\.\\.\\ d_Nf_N-W_{N:}f\end{pmatrix}\\=\begin{pmatrix}d_1&\cdot&\cdot&\cdot&0\\.&.&&&.\\.&&.&&.\\.&&&.&.\\0&\cdot&\cdot&\cdot&d_N\end{pmatrix}f-\begin{pmatrix}W_{1:}\\.\\.\\.\\ W_{N:}\end{pmatrix}\\=diag(d_i)f-Wf\\=(D-W)f\\=Lf
Δf=⎝⎜⎜⎜⎜⎛Δf1...ΔfN⎠⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎛d1f1−W1:f...dNfN−WN:f⎠⎟⎟⎟⎟⎞=⎝⎜⎜⎜⎜⎛d1...0⋅.⋅⋅.⋅⋅.⋅0...dN⎠⎟⎟⎟⎟⎞f−⎝⎜⎜⎜⎜⎛W1:...WN:⎠⎟⎟⎟⎟⎞=diag(di)f−Wf=(D−W)f=Lf
这里的(D-W)就是拉普拉斯矩阵
L
L
L。根据前面所述,拉普拉斯矩阵中的第
i
i
i行实际上反应了第
i
i
i个节点在对其它所有节点产生扰动是所产生的增益累积。直观上来讲,拉普拉斯矩阵反映了当我们在节点
i
i
i上施加一个势,这个势以哪个方向能够多顺畅的流向其它节点。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









