






论文阅读:Entangled Watermarks as a Defense against Model Extraction
这里给大家分享一篇有关模型水印的论文。这篇文章2021年发布在the Proceedings of the
30th USENIX Security Symposium,讲述的是如何通过纠缠水印实现将水印嵌入神经网络中以抵抗模型提取攻击。
1 为什么以前的水印模型难以抵抗模型提取攻击?
自适应攻击者可以击败原始标记水印,因为水印是任务分布的离群值。只要攻击者只对从任务分布中采样的输入查询带水印的模型,被盗用模型将只保留受害模型与任务分布相关的决策曲面,从而忽略学习到的与水印相关的决策曲面。换句话说,为什么可以在对模型精度影响有限的情况下执行水印,这就是为什么水印可以很容易地被对手删除的原因。换句话说,水印模型大致上将参数集分成两个子集,第一个子集对任务分布进行编码,第二个子集对异常值(即水印)进行过拟合。
1.1 扩展知识
先给大家介绍一下阅读本文需要了解的一些先验知识吧,这里只是大概介绍知识点的主要思路或用法,具体推导大家可以自行学习。
-
软最近邻损失(SNNL) :表示空间数据流行纠缠的特征
这里公式为
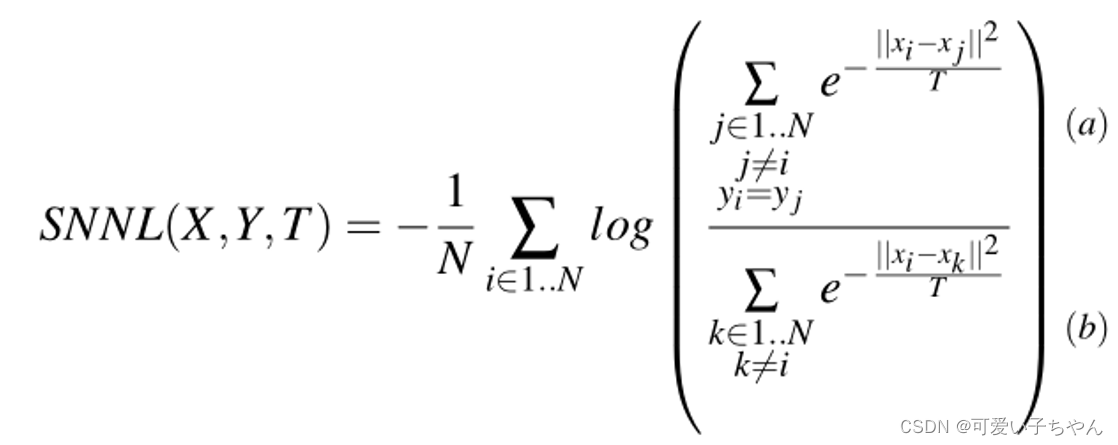
SNNL测量来自不同编组的点之间对于同一编组内的点的平均距离的距离。
该损失的主要部分计算:
(1)将点xi与同一组yi中的其他点分开的平均距离
(2)将两点分开的平均距离之间的比率
通俗来说,SNNL值大表示按类的特征分布是交织在一起的,SNNL值小表示按类的特征分布是分开的。 -
Out-of-Distribution (OOD):举个通俗的例子吧。在一个猫咪品种识别的任务中,不同的猫咪照片是所谓的“in-distribution”样本,而其他动物乃至于不是动物的东西,比如狗、人、房子之类的都是“out-of-distribution”。
-
神经网络清理(Neural Cleanse) :用于检测和删除深度神经网络中后门的技术。
Neural Cleanse技术通过增加一个后门会导致源类和目标类的集群在标识空间中变得更加接近。因为对于数据集的每一个类c,Neural Cleanse试图对来自与c不同的类的数据进行扰动,让其错误地分类为c类;接下来,需要明显较小的扰动才能实现的类被确定为“受感染”的类(即被精心设计的后门作为目标类的类)。如果从这个分析中得出的异常指数高于某个阈值,就认为这个模型被插入了后门。实现这一等级所需的扰动是恢复的触发器。一旦目标类别和触发器类别都被确定,人们就可以通过重新训练模型来消除后门,将带有触发器的数据分类到正确的类别中去。 -
模型提取攻击:
模型提取攻击的过程大致分为两步:
(1)向目标模型查询一组输入图像,并获得该模型给出的输出图像;
(2)使用查询得到的输入-输出对训练一个knockoff(替代模型)。
攻击者首先收集或合成最初未标记的替代数据集,利用向受害者模型查询标签预测的能力来注释替代数据集;接下来用这个替代数据集训练受害者模型的副本。对手的目标是获得一个被盗的副本,其性能与受害者相似,同时进行较少的标签查询。 -
交叉熵损失函数:
本文使用交叉熵损失函数来衡量模型输出与真实标签之间的差异
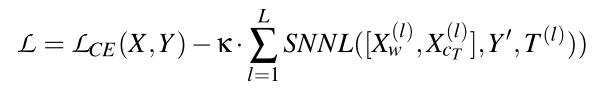
其中fk(xi)是K个可能类别中第k个类别的模型f的预测分数。
由于最小化这种损失可以被解释为测量任务和学习分布之间的KL差异,因此最小化这种损失会鼓励模型预测和真实标签之间的相似性。
2 本文的主要贡献
在本文中,提出了一种技术来解决水印的关于无法抵抗模型提取的限制,纠缠水印嵌入。纠缠水印嵌入(EWE)鼓励模型能够有效实现以下两点:
(a)学习如何从任务分布中分类数据
(b)预测防御者在水印上的预期输出
我们的关键见解是利用软最近邻损失来纠缠从训练数据和水印中提取的表示。所谓纠缠就是模型以相似的方式来表示这两种类型的数据。纠缠产生的模型使用相同的参数子集来识别训练数据和水印。因此,对手很难在没有水印的情况下提取模型,即使对手仅从任务分布中查询带有样本的模型以避免触发水印。对手被迫学习如何在水印上再现防御者所选择的输出。删除水印的尝试也会损害被窃取的替代分类器在任务分布上的泛化性能,这将破坏模型提取的目的(即窃取一个性能良好的模型)。
本文的主要贡献
1. 我们发现了现有水印策略的一个局限性:水印任务与主要任务是分开学习的;
2. 我们引入**纠缠水印嵌入(EWE)**鼓励模型能够联合学习如何从任务分布和水印数据中对样本进行分类。
即鼓励模型提取特征,这些特征可以同时学习
(a)学习如何从任务分布中对数据进行分类
(b)预测防御者对水印的预期输出
3. 我们的关键是利用软最近邻损失(SNNL)来纠缠从训练数据和水印中提取的表示。即使对手仅用来自任务分布的样本来查询模型以避免触发水印,也很难在没有水印的情况下提取模型。
4. 我们在图像和音频数据上系统地校准了EWE。我们表明,当仔细选择要加水印的地点时,在所考虑的数据集上,EWE在模型实用型和水印鲁棒性之间做出了折中。
3 传统水印嵌入的困难之处
3.1 难以抵抗模型提取攻击
考虑一个二进制分类任务,如果x1+x2>1,则2D输入[x1, x2]并将一个标量输出y设置为1,否则设置为0(在下面的两个公式中均满足这两个条件)。
输入x1和x2从两个独立的均匀分布U(0, 1)中采样,因此对于任务分布而言,x1, x2都只能取0~1之间的值。
那么设定如果x2=-1(x1任意),则我们将该模型加水印以输出1。可以将该函数建模为如图所致的前馈DNN:
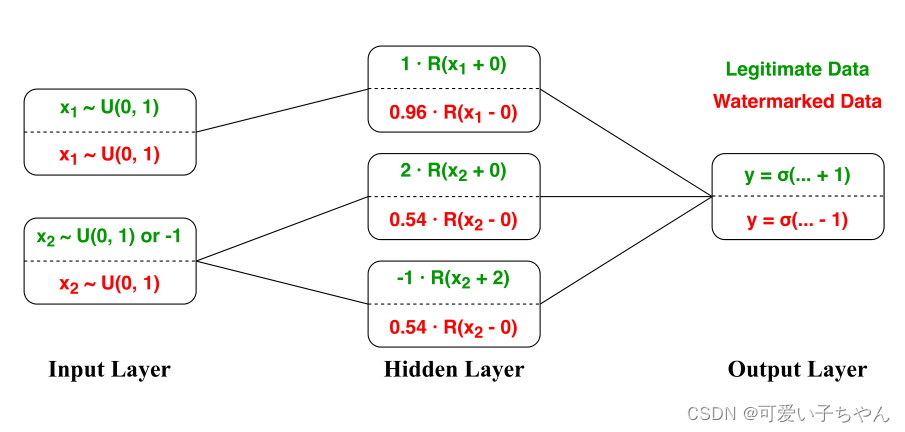
使用S型激活σ作为终极层以获得一下模型:
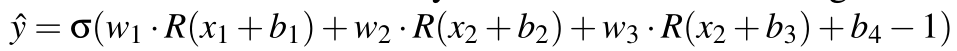
其中R(x) = max(0,x),σ表示sigmoid激活函数。
我们使用以下参数值实例化此模型:
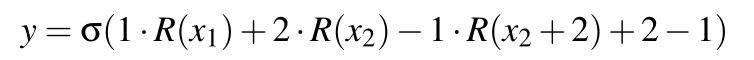
当x2=-1,x1随意时,y=σ(R(x1)-1+2-1)=σ(R(x1)-1),这里的R(x1)肯定是≥0的,则R(x1)=x1,那么σ(x1)>0.5(即y=1)
在用来自任务分配的输入和从受害者模型获得的标签来训练替代模型之后,对手学习的决策函数是:
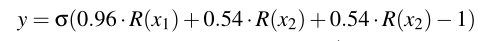
但是由于分布外输入x2=-1,当函数最大值(当x1=1时)结果为σ(−0.04),又因为x1≤1,所以无论x1多大。y=0是一定的,这就成功将水印去除了。
这里的原理是:
在防御者对模型进行训练的时候,有x2=-1,x1取任意值的情况下y=1的先验条件,因此在训练时,一定会同时向着这个条件以及原始的任务分布条件拟合
而对于攻击者来说,他并没有x2=-1,x1任意下y=1的先验条件,他仅有任务分布的条件,因此只会拟合这个条件,这就导致水印有可能被去除掉。
任务和水印分布是独立的。如果模型有足够的容量,它可以从属于两个分布的数据中学习。然而,该模型独立地学习两个分布。在上面描述的分类示例中,对任务数据的反向传播将更新所有神经元,而对带水印数据的反向传播只更新第三个神经元。然而,对手不能单独更新用于水印的小群神经元,因为他们在提取过程中从任务分布中采样数据。
3.2 独特的激活方式
训练算法如何收敛到一个简单的解决方案,以同时学习两个数据分布:学习模型容量大致分为连哥哥子模型,每个模型识别来自两个数据分布(任务与水印)之一的输入。
我们记录了模型对MNIST数据集的合法任务数据以及水印数据及逆行预测时激活的神经元。其中包括合法数据和水印数据的神经元激活频率,如图所示。

每个方块代表一个神经元,更高的强度(更白的颜色)代表更频繁的激活。证实了我们关于两个子模型的假设,我们看到合法数据和水印数据有不同的神经元被激活。
4 纠缠水印的提出
根据观察,水印模型被划分为可区分的子模块(任务与水印),我们建议背后的直觉是将水印与任务流形联系起来。
威胁模型
我们的对手的目标是提取没有水印的模型。为此,我们假设我们的对手:
(1)具有用于训练受害者模型(但不知道其标签)的训练数据的知识
(2)使用这些数据点或来自任务分布的其他数据点进行提取
(3)知道受害者模型的架构
(4)了解是否部署了水印
(5)不知道用于校准水印过程的参数或用作水印过程一部分的触发器
这样的对手是一个强大的对手,很容易进行模型提取攻击,因此我们要将水印与任务流形纠缠在一起。
4.1 软最近邻损失
我们的水印方案的目标是确保水印模型不会被分割成可区分的子模型。为了确保水印和任务分布由同一组神经元联合学习/表示(从而确保可生存性),我们使用软最近邻丢失(或SNNL)。这种损失被用来测量由模型学习的任务数据和加水印数据的表示之间的纠缠。
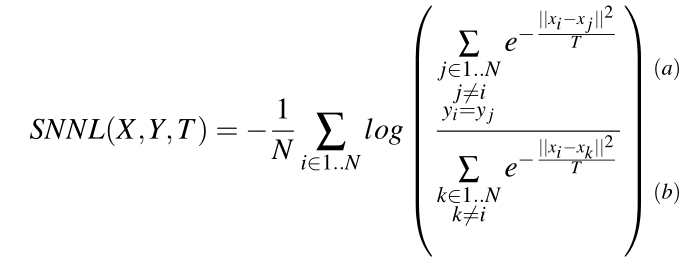
4.2 纠缠水印的嵌入
我们在算法1中提出了我们的水印策略——纠缠水印嵌入(EWE)。我们利用SNNL的能力来纠缠来自任务和水印分布的数据表示。也就是说,我们鼓励合法任务数据和带水印的数据的激活模式类似。这使得水印对模型提取攻击具有鲁棒性:对手仅在任务分布上查询模型时仍将提取水印。
纠缠成功后的水印模型的激活频率如图所示。


算法1描述了纠缠水印的嵌入
输入参数:
X,Y:模型任务的合法数据集, 即D={X, Y}
Dw:用于表示水印分布的数据集
cS:来自Dw的原始分类
cT:训练模型最终将Dw预测为错误分类cT
r:合法数据的正常批次
α:附加超参数
loss:模型的训练损失
model:原始需要训练的模型
trigger:触发器(是一个输入掩码)
输出:带有水印的模型
**step1:**水印生成
-
对数据集Xw~Dw(cS)进行采样以初始化水印数据集,其中Dw(cS)表示来自Dw的标签为cS的数据集(原始标签),cT是目标标签;Y’=[Y0, Y1]分别为[Xw, XcT]的任意标签。(公式1)
如果执行的是分布内水印,则Dw可以与合法数据D相同(从合法数据中提取一部分数据集作为水印集),
如果执行的是分部外水印,则Dw可能是一个相关数据集。
在一个未加水印的模型中,Xw不太可能被错误分类为cT(只有嵌入水印的模型使用Xw才能被错误分类为cT) -
为此我们定义一个触发器,它是一个输入掩码,并将其添加到Xw中的每一个样本。因此,Xw现在包含了水印(离群值)可以用来给模型打水印,以后可以用于验证所有权。要注意的是,触发器不应该改变Xw的语义,使其与XcT相似。
例如下图所示:
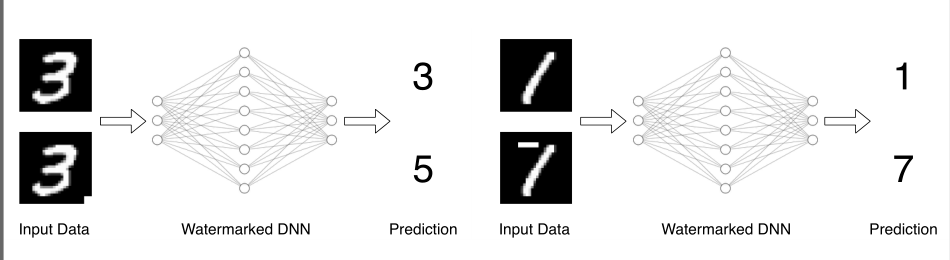
左图是一个正确的触发器,我们添加的触发器并不会让3从视觉上来看就长得像5
右图是一个错误的触发器,我们添加的触发器让1变成了从视觉上长得就像7的图片,这样会影响到我们对触发集的训练。
因此,我们将触发器的位置确定为SNNL相对于候选输入具有最大梯度的区域。即XcT和Xw在图像视觉上看起来不能纠缠在一起。(公式2、3、4) -
防御者用梯度上升法优化水印数据,以进一步避免产生不适当的触发器。这种梯度上升的目的是扰乱输入,以降低模型预测目标类别的信心。由于我们希望对水印输入进行的梯度上升的效果能够在不同的模型之间转移(即希望改梯度上升法具有一定的通用性),因此我们使用FSGM。我们计算FSGM的公式为:
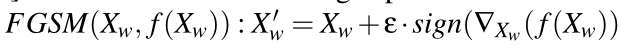
其中ε是步长,f是对Xw操作的函数。
我们将公式5、6进行交替操作,
公式5将f定义为通过一个(不同的)干净模型预测Xw为目标cT的LCE,鼓励Xw与XcT视觉上不同
公式6将f定义为Xw和XcT之间的SNNL,使得纠缠更加容易以导致更加鲁棒的水印。
我们使用更多的步骤5来确保Xw在视觉上与cT不同。
**step2:**改变模型的损失函数
为了更鲁棒的给模型打水印,我们在每一层都计算SNNL,l∈[L]。其中L是DNN的总层数,使用它对Xw和XcT的表示,这将使我们能够纠缠它们。Y’=[Y0, Y1]分别为[Xw, XcT]的任意标签。我们将所有层的SNNL相加,每个层都有一个特定的温度系数T(l)。系数k控制SNNL在交叉熵中的相对重要性。换句话说,k控制水印鲁棒性和任务分布上的模型精确度之间的衡量。
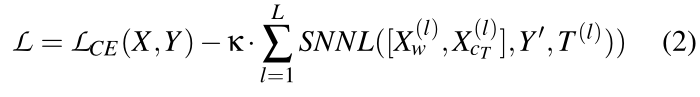
**step3:**训练模型(公式8~14)
我们初始化并训练一个模型,直到损失收敛或epoch达到最大。在训练中,我们对合法数据X的r个正常批次进行采样,然后是与XcT串联的Xw的单一交错批次,这两个批次都需要使用SNNL进行纠缠。
在合法数据集上,我们对(2)中设置k=0,以最小化任务损失;
在包括水印的交错数据[Xw, XcT]上,我们设置k>0已优化总损失。我们使用训练期间学到的α来更新T,从而减轻了α作为一个额外的超参数来调整的需求。
公式14 就是让任务分布和水印分布纠缠在一起(即激活模式向接近),让攻击者无法进行模型提取攻击。
4.3 验证EWE
-
使用更少的查询实现所有权验证
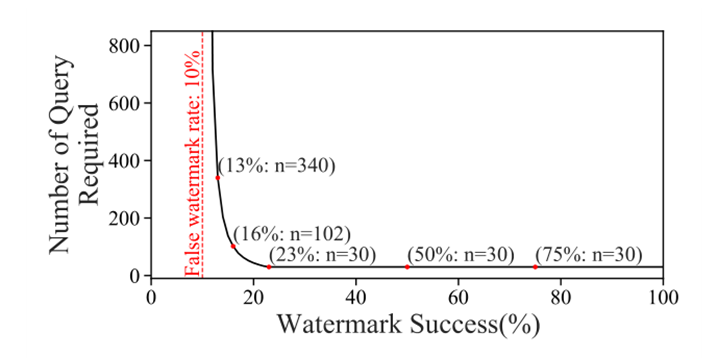
水印成功率:一个水印模型成功识别水印数据为CT类的概率
假阳性率:非水印模型将水印数据识别为CT类的概率
如果水印成功率远远超过假阳性率,那么t检验对被盗模型的查询就会少的惊人 -
更好地将水印与分类任务纠缠在一起
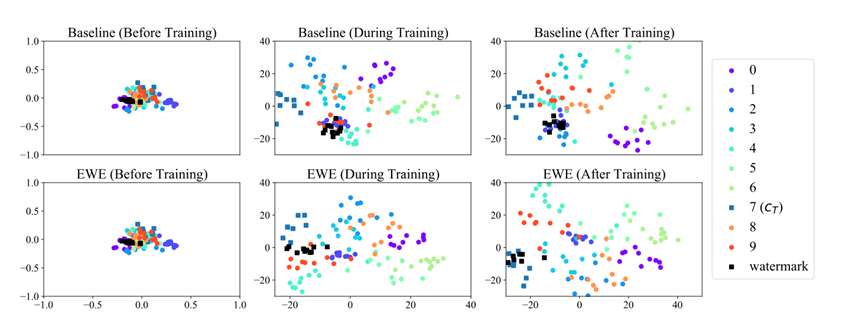 上一行是用交叉熵来训练基线,下面的行是用EWE来训练另一个模型。
上一行是用交叉熵来训练基线,下面的行是用EWE来训练另一个模型。
基准线通过最小化目标类CT的交叉熵损失来主动学习水印,训练结束后,我们看到这将水印数据,Xw,推导一个单独的集群,远离目标类cT。
EWE使用SNNL将Xw与X(cT)纠缠到一起,这导致了水印数据与合法数据的重叠集群。
从实验来看,我们发现EWE在倒数第二层隐藏层中获得的分离度最小,因为它计类了所有前几层的SNNL(前面每一层都使用了SNNL) -
更加健壮地抵御模型提取攻击
我们的实验表明,我们观察到EWE的最大好处(与基线相比):水印成功率往往有≥20个百分点的提高。
我们的主要结果是,我们可以实现18%到60%的水印成功率,平均为38.39%;基线为0.3%到9%,平均为5.77%。
我们还验证了在训练期间继续 -
扩展到更深层次、更大的架构
将水印与合法数据纠缠在一起,使得甚至迫使早期层学习同时识别两种类型数据的特征,这就解释了水印的鲁棒性的提高。有了纠缠,只有后面的层需要使用能力来区别这两种类型的数据,以保持模型的准确性。
6 对适应性攻击者的鲁棒性
6.1 攻击者知道EWE及其参数的知识
了解关于配置EWE的参数可以击败水印。EWE的鲁棒性依赖于保持触发参数和水印参数的保密性,以保护模型中包含的知识产权。
如果攻击者知道用于为输入添加水印的触发器,他们可以拒绝对包含该触发器的任何输入进行分类(拒绝服务)。或者他们可以提取模型,而不是最小化水印和cT类合法数据的SNNL。此外,攻击者还可以重新训练触发器来预测正确的标签。
然而,这并不是一个现实的威胁模型。一般而言,攻击者应该只知道EWE被用于水印了,但是EWE的参数起到类似于加密秘钥的作用,所以攻击者一般是很难知道的。
6.2 攻击者仅知道关于EWE的知识
有了EWE的知识,但不知道它们的配置,对手仍然可以通过几种方法进行适应。我们评估了四种自适应方法。
-
解开水印纠缠
-
我们推测。攻击者可以通过最小化SNNL来提取任务数据中的纠缠水印。我们假设一个强威胁模型,使得攻击者知道EWE的所有参数,但源和目标类除外。因此攻击者猜测类,根锁EWE构造水印数据,并提取模型,同时使用k<0的EWE来区分声称的水印数据和声称的目标类中的合法数据。经过这样的过程,可以将水印的成功率大幅度下降。但是,虽然这种攻击下降了水印成功率,但当对手仍然能够声称自己的所有权。此外,观察到正确地猜测类对需要大量的计算来训练对应于K(K-1)个可能的源-目标对的模型,其中K是数据集中的类数,这违背了模型提取的目的。
-
盗版攻击
在盗版攻击中,对手在EWE中嵌入自己的水印,这样模型就会被嵌入两次水印,通过水印声称所有权就会变得模糊。
为了去除盗版水印,我们建议在受害者模型标记的数据上对提取的模型进行精细剪枝。
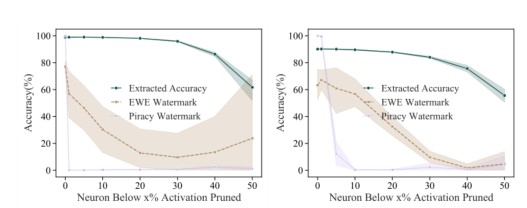
如图所示,所有者的水印并不会被移除,而盗版水印会被移除(即使对手使用EWE),因为受害者模型标记的水印不包含关于盗版水印的信息。对手不能做同样的事情来删除所有者的水印,因为这需要访问由另一个来源标记的数据集,在这一点上,盗版的成本击败了模型窃取:对手可能已经在该数据集上训练了模型,而不会从模型窃取中受益。 -
异常检测
攻击者可能知道要加水印的模型,因此他们可能决定实现异常检测器来过滤包含由EWE标记的数据的查询,并用随机预测来响应它们。通过这样做,即使参数仍然嵌入水印,对手仍然可以组织防御者声称所有权。 -
迁移学习
攻击者还可以将所提取的模型的知识转移到同一域中的另一数据集,希望将该模型与eWE的水印分布分离。
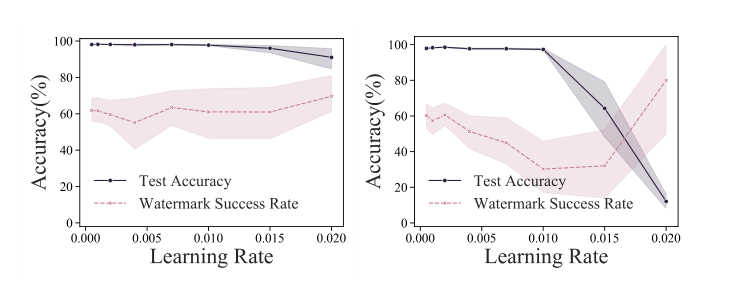
如图所示,即使微调所有层,也不能消除水印。
(A)达到98.25%的准确率,但水印不受影响;(B)达到98.56%的准确率,并且随着学习率的提高,水印开始减弱。然而,在去除水印之前,由于较大的学习速率值,预先训练的知识会丢失。这与以前工作中的观察结果一致。我们还注意到,转移学习要求对手能够获得额外的训练数据并执行更多的训练步骤,因此预计我们声称模型所有权的能力将较弱。
总结
我们提出了纠缠水印嵌入(EWE),它迫使模型纠缠合法任务数据和水印的表示。我们的机制形成了一个新的损耗,包括软最近邻损失。当最小化时,它会增加纠缠。
通过我们对图像以及音频领域任务的评估,我们表明EWE不仅对模型提取攻击,而且对盗版攻击、异常检测、迁移学习和用于缓解后门攻击的努力都是鲁棒的。所有这些都是在保持水印精度的同时实现的,
(a)分类精度的名义损失
(b)1.5-2倍的计算开销增加
在不损失很大精度的情况下降EWE扩展到复杂的任务仍然是一个悬而未决的问题。
参考文章
Entangled Watermarks as a Defense against Model Extraction


















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









