







Kruskal算法带有一点贪心的思想,核心就是,先将图分割成独立的森林,然后每次选择最小的不在图中的边加入,直到构成连通图。
难点在于,如何判断当前这个结点是否已经处于连通图中,需要用到并查集的概念。
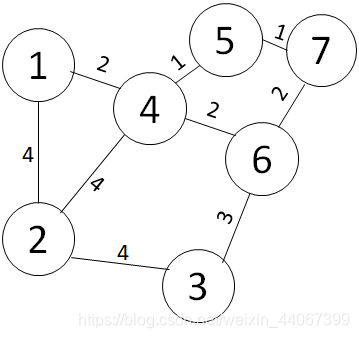
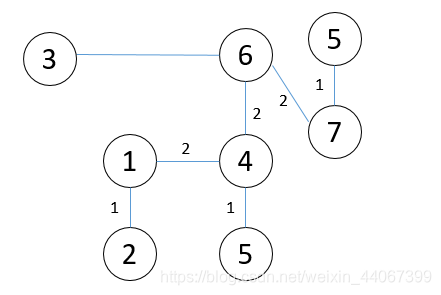
首先将图分割成7个独立的森林。
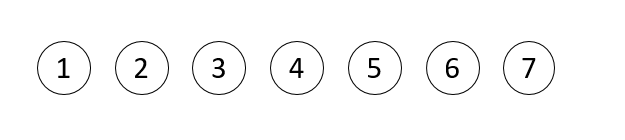
然后按边的长度从小到大进行排列。
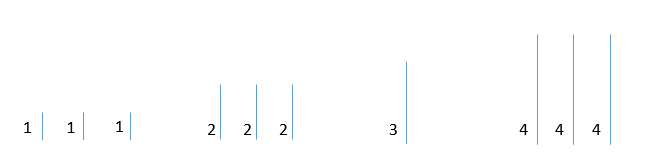
然后每次将边长最小的结点加入图中,如果已经连通,则不加入。
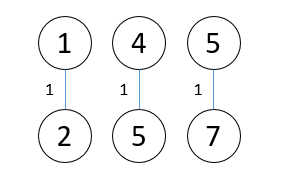
直到构成了一个连通图能够遍历到所有结点

不给我看代码,你吹的再牛皮,我也不信。
那么具体实现如下:
首先我们定义一个边的类:在其中定义一些get set方法,便于我们对某个结点进行操作。
package 最小生成树.Kruskal;
/**
* 定义边
* 重写compareTo方法,为了List排序
*/
public class Edge implements Comparable{ //结点vnode1 结点vnode2 连通长度为val
private int vnode1;
private int vnode2;
private int val;
public Edge(int v1,int v2,int val){
this.vnode1=v1;
this.vnode2=v2;
this.val=val;
}
public void setV1(int v1) {
this.vnode1 = v1;
}
public int getV1() {
return vnode1;
}
public void setV2(int v2) {
this.vnode2 = v2;
}
public int getV2() {
return vnode2;
}
public void setVal(int val) {
this.val = val;
}
public int getVal() {
return val;
}
@Override
public int compareTo(Object o) {
Edge edge=(Edge)o;
if(edge.val>val){
return -1;
}else
{
return 1;
}
}
}
package 最小生成树.Kruskal;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* 定义图
**/
public class Graph{
public static void main(String[] args){
List<Edge> EdgeList = new ArrayList<>();
EdgeList.add(new Edge(0,0,0)); //初始结点
EdgeList.add(new Edge(1,2,4));
EdgeList.add(new Edge(2,3,4));
EdgeList.add(new Edge(2,4,6));
EdgeList.add(new Edge(1,4,2));
EdgeList.add(new Edge(3,6,3));
EdgeList.add(new Edge(4,6,2));
EdgeList.add(new Edge(4,5,1));
EdgeList.add(new Edge(5,6,4));
EdgeList.add(new Edge(1,5,3));
EdgeList.add(new Edge(5,7,1));
EdgeList.add(new Edge(6,7,2));
int parents[]=new int[EdgeList.size()];
for(int i=1;i<EdgeList.size();i++){ //初始化并查集
parents[i]=i; //每个结点都是一棵树,构成森林
}
//排序,加入连通图
Collections.sort(EdgeList); //重写compareTo方法,升序排列
for (int i=0;i<EdgeList.size();i++)
{
System.out.println(EdgeList.get(i).getVal());
}
//加入连通图 -> 如果两个结点 没有相同的父节点,则认为 他们不处于同一个连通分量中
for(int k=1;k<EdgeList.size();k++){ //从最短边开始,依次将最短加入到连通图中。(加入前判断,如果已经在连通图中,则不加入)(最短边是EdgeList[i])
Edge edge=EdgeList.get(k);
int n = find(edge.getV1(),parents);
int m= find(edge.getV2(),parents);
//判断是否在连通图中
if(n!=m){ //如果根节点不同,则加入到连通图中
parents[edge.getV2()]=edge.getV1();
}
}
//--------------此时,并查集中的内容,即存储了这个最小生成树---------------------//
}
public static int find(int node,int parents[]){ //用来判断是否位于连通图中
while(node!=parents[node]){
System.out.println(node);
node=parents[node];
}
return node;
}
}

说到这里,可能有人会问,为什么最小生成树就生成好了呀?
为什么这个并查集可以存储这个最小生成树啊?
你这个parents数组太抽象了啊。
我这时候要是想从里面拿一个数,我怎么拿啊?
下面,我们就来好好聊聊这个并查集。

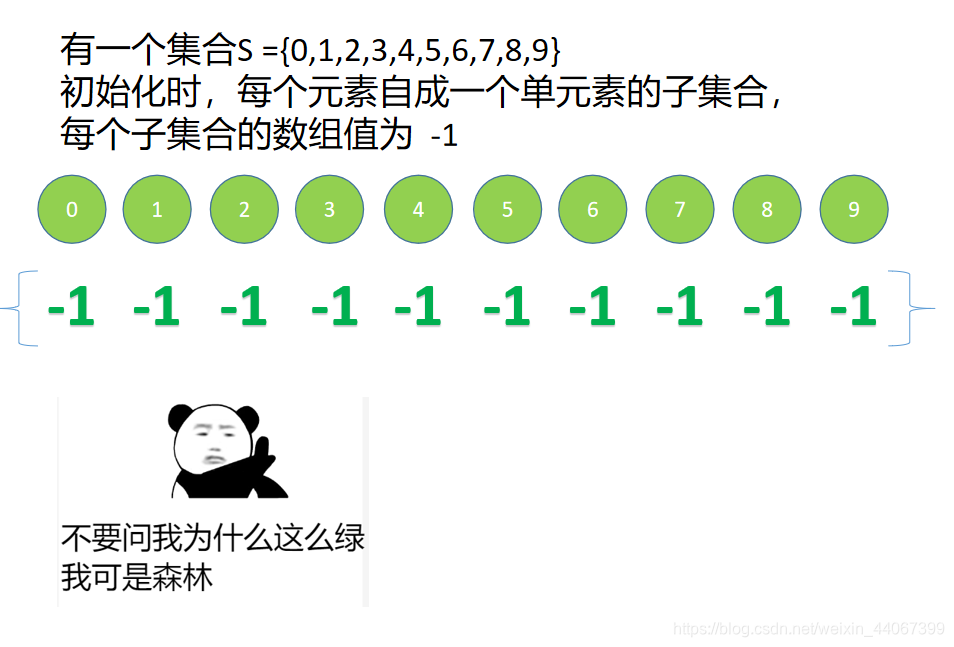
并查集,作为一种简单的集合表示。支持以下三种操作
1.Union(S,ROOT1,ROOT2):
在Root1和Root2互不相交的前提下,把子集合Root2并入
2.Find(S,X):
查找集合S中元素x所在子集合,并返回子集合名字
3,Initial (S):
将S中每个元素都初始化为一个单元素的子集合,所有表示子集合的树,构成表示全集合的森林。(这不就是Kruskal的第一步)。通常用数组元素的下标代表元素名,用根节点的下标代表子集合名,根节点的双亲节点为负数。

然而事情并没有这样就结束了,这些子集合都不安分。
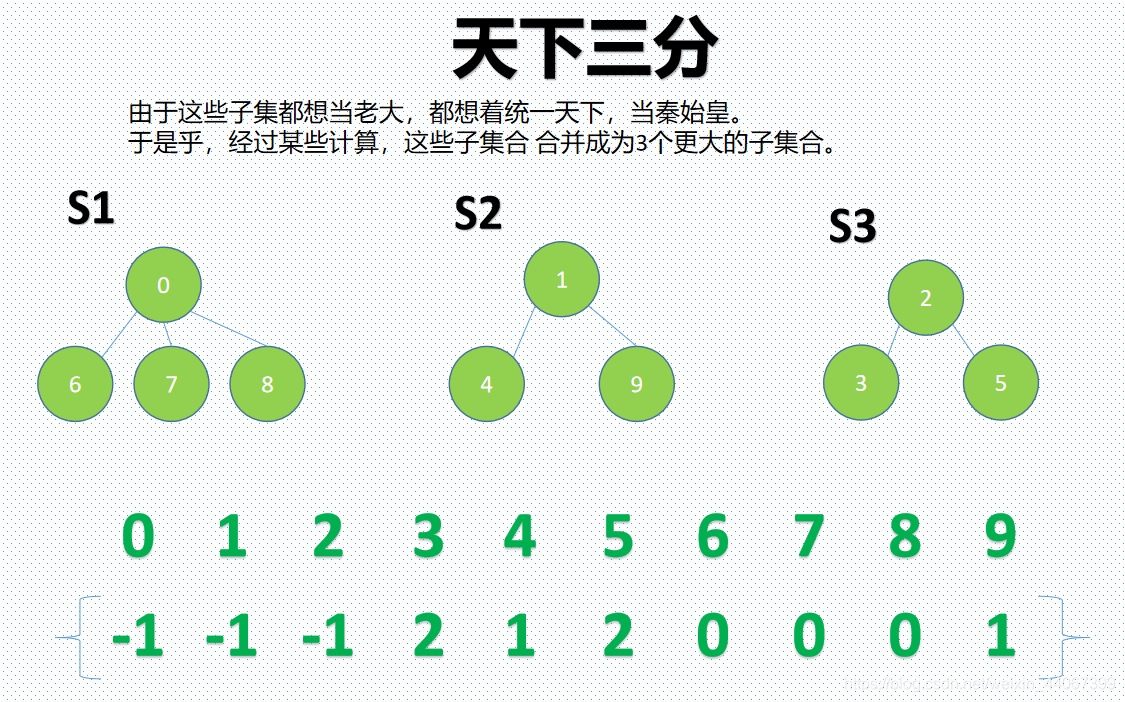
可以看到,6 7 8认0做老大,4 9认1做老大,3 5认2做老大,
数组里,谁拿着-1,谁就是老大。
经过一段时间的战争,子集合S2顶不住了,那么子集合S1该如何将S2收入麾下呢?
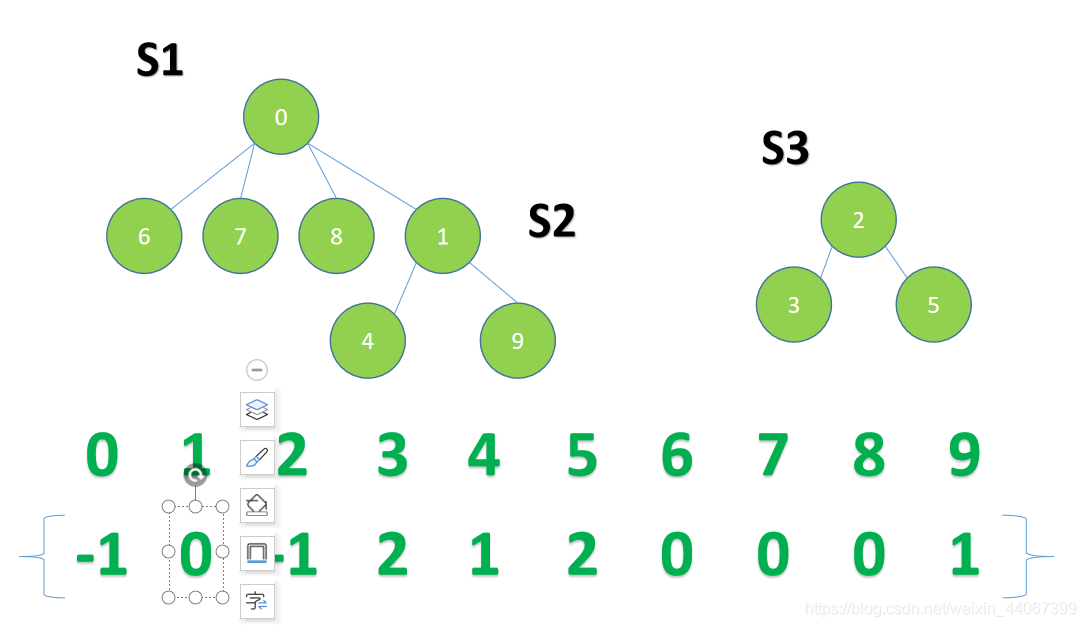
让子集合S2的老大认 0 做老大不就行了。
三种操作的伪代码如下
void Initial(int S[]){
for(int i=0;i<=size;i++){
S[i]=-1; //一开始谁也不服谁,构成独立的森林
}
}
int find(int S[],int x){ //输入为其中随便某个结点的序号,返回根 //其实并查集的find 只能够找到他们的老大。因此它的功能就是返回老大
while(S[x]>=0){
x=S[x]
)
return x;
}
}
void Union(int S[],int Root1,int Root2){ //输入两个子集合的序号,让Root2认Root1做老大
S[Root2]=Root1;
}














 955
955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









