









 本文探讨了在三维渲染中灯光的重要性,包括光源类型的选择、光照属性配置、全局光照技术、高动态范围影像的应用以及实时预览和优化技巧。特别提到Renderbus瑞云渲染服务在夜间场景中的便利性,如使用VRay渲染器创建逼真的夜景效果。
本文探讨了在三维渲染中灯光的重要性,包括光源类型的选择、光照属性配置、全局光照技术、高动态范围影像的应用以及实时预览和优化技巧。特别提到Renderbus瑞云渲染服务在夜间场景中的便利性,如使用VRay渲染器创建逼真的夜景效果。
在三维渲染中,光线的部署如同绘画作品中的色彩调配,至关重要,一个精心设计的照明方案能赋予效果图以生命,凸显质感,营造深度,并传达特定氛围。在灯光设置过程中,先思考光源的类型与位置,从而确保光线恰如其分地照亮关键的视觉元素,模拟现实世界的光照原理,也激发出艺术的想象空间。

渲染效果图灯光作用
在渲染过程中,灯光提供场景的亮度和高光,还是塑造氛围、强调细节、指引观众视线以及建立时间和空间感的关键因素。不同类型的灯光、颜色、强度、方向和对光源的精细控制,艺术家能够模拟自然光源如阳光或月光,也能创造出超现实的视觉效果。
正确的灯光设置能够增强材质的质感,描绘出物体的形态和深度,赋予作品所需的情感色彩。此外,通过阴影的应用,灯光还能强化场景的立体感和动态效果。灯光是渲染艺术中不可或缺的元素,它的运用直接影响着最终图像的真实性与表现力。

渲染效果图灯光设置技巧
1、确定光照类型和数量:
-
主光源:提供主要照明,通常模拟太阳或其他主要光源。
-
辅助光源:用于减少阴影的强度,平衡光照,使场景更加柔和。
-
背光:从背后照射,用来勾勒物体轮廓,增加深度感和层次。
-
环境光:模拟无处不在的间接光,提升整体亮度,减少过度阴影。
2、配置光照属性:
-
强度:调节光线的亮度,以确保场景不会过曝或太暗。
-
颜色:光源的颜色可以影响场景的气氛和时间感觉。如,黄色光暖色调;蓝色光冷色调。
-
衰减:模拟现实世界中光随距离降低的强度。光照强度随距离增加而逐渐减少。
-
阴影:合理设置阴影的软硬程度、密度和色彩,使得阴影更加自然和逼真。
3、使用全局光照:
-
利用全局光照技术,可以更加逼真地模拟光线如何在一个场景中弹射和散射,这包括直接和间接的照明。
4、应用高动态范围影像:
-
通过使用HDRI作为环境贴图来模拟真实世界中复杂的光照效果。HDRI能够提供更动态的亮度范围,使得光照效果更加丰富真实。
5、实时预览和调整:
-
利用现代3D软件中的实时渲染预览功能,即时查看光照效果的改变,这样可以实时调整并直观看到效果。
6、细化与优化:
-
调整完基本光照设置后,还需要根据具体场景进行一些微调。包括特定区域的强光或阴影调整,确保光照和谐并符合场景需求和构图原则。
通过以上方法可帮助新手更加了解渲染效果图中需要关注灯光中的哪些要点。如果想在渲染中更加省事可以考虑“Renderbus瑞云渲染”出图,免去本地电脑渲染等待过程电脑无法使用,直接提交到云渲染农场,释放电脑限制,灵活掌握时间
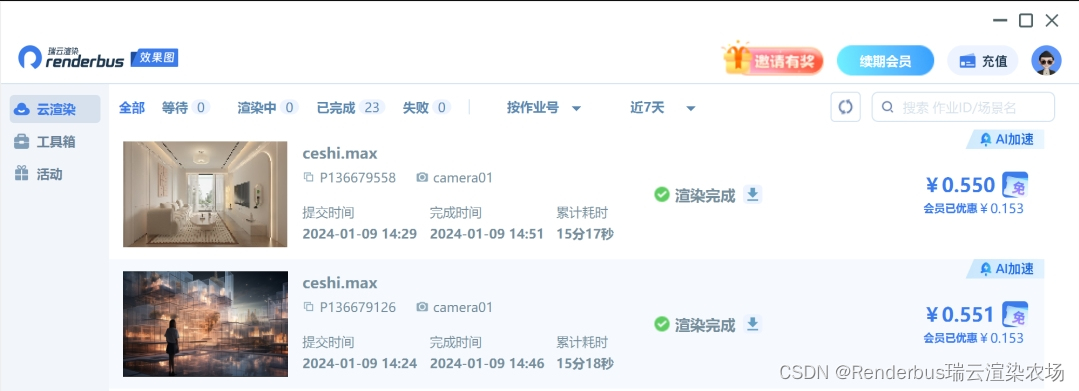
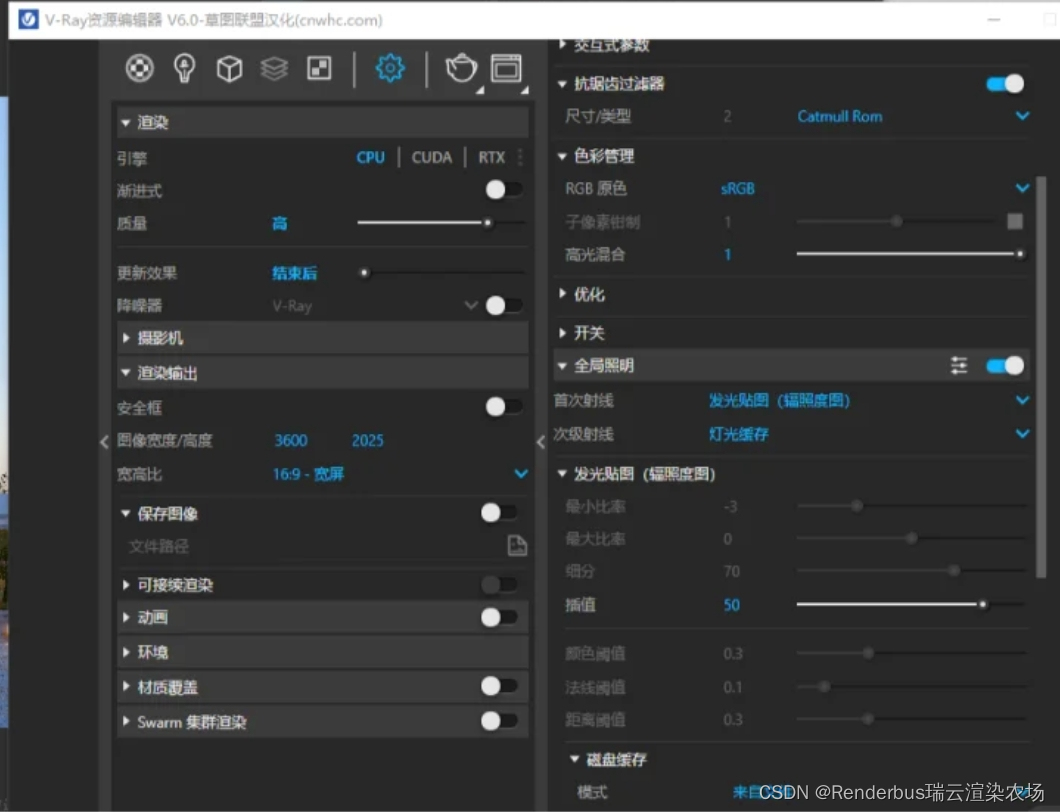
渲染效果图夜景灯光设置参数
渲染器:VRay
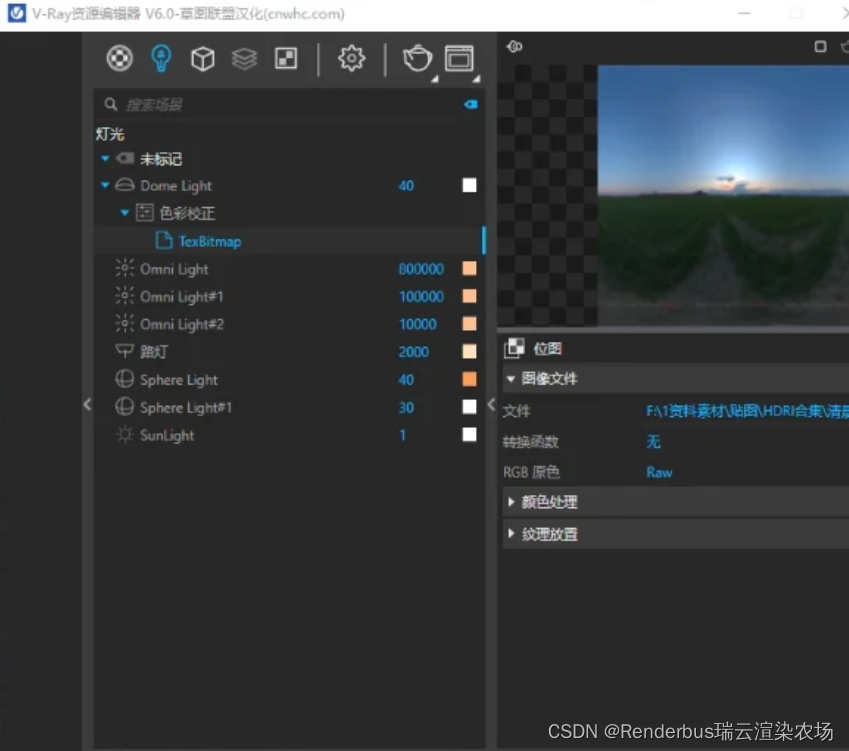
最终夜晚渲染效果图:


















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









