









收集数据 -> 标注/清洗数据 -> 数据变换 -> 特征工程 -> 模型训练
2.1 探索性数据分析 EDA(Exploratory data analysis)
seaborn可以画的matplotlib多
data = pd.read_csv('house_sales.zip') 可以读zip文件诶!!!
- 丢掉缺失值大于30%的列
null_sum = data.isnull().sum()
data.drop(columns = data.columns[null_sum > len(data) * 0.3], inplace=True)
- 数据类型转换
通过data.dtypes查看每列的数据类型

通过data.describe()查看数据的描述,包括每列对应的以下内容

过滤异常信息~abnormal == normal

画图看看出售价格的总体走势(做了log10处理)柱状图

data['Type'].value_counts():找独一无二的值及其出现的次数

不同房型房价分布密度图 折线图

不同房型的单位房价分布 箱型图

不同列的协方差矩阵 热图

2.2 数据清理
数据错误类型及检测
outliers(离群点):box plot删除离群点
rule violations:通过约束 ①功能依赖 functional dependency x->y;②denial constraints更加灵活的一阶逻辑方程
pattern violations:句法模式syntactic patterns,语义模式semantic patterns
2.3 数据变换
- 对于实数值的标准化方法 normalization
① Min-max
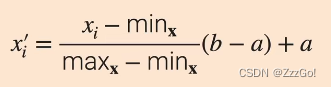
② Z-score(最常见)
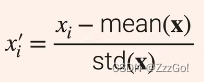
③ Decimal scaling(max(|x|))

④ Log
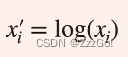
- 对于图片
下采样、裁剪:减小图片尺寸、注意图片质量(jpeg中等质量会导致精确度下降1%)
image whitening:图片中有些像素没用,通过降维减少图片的像素点,使输入不那么冗余、模型收敛得更快
- 对于视频
用好的压缩算法压缩视频,之后再解码视频、使用GPU进行采样,选取需要的帧
将视频以一帧一帧的图片的形式存储起来,比较费内存
- 对于文本
词根化语法化:careful->care;am, are, is -> be
词元化:text -> a list of tokens 通过词/字符/分词subwords
2.4 特征工程(Feature Engineering)
Machine Learning:input->manually engineered features->SVM
Deep Learning:input->features learned by a neural network->softmax regression(更准确 费数据 费计算资源)
表格式数据特征
int/float:直接用或者划分bin变为n个独特的int值
类别数据:one-hot独热编码 一列变成n列,只有一列为1

时间:用特征列表来表示 yy-mm-dd-h-m-s
特征组合:两种特征的笛卡尔积(Cartesian)结果
文本数据特征
- 用词元特征代表文本
① Bag of words(BoW) model:把一个句子所有词元的独热编码加起来(要小心地设计词典,存在上下文缺失问题)
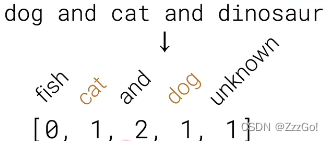
② Word embeddings(e.g. Word2vec):
训练一个词嵌入模型,把词表示为一个词向量,向量之间有一定的语义信息(两个词对应的向量距离(e.g. 余弦距离)比较近说明其语义相近),把这个句子中所有词向量加起来,就得到了这个句子的词嵌入表示。
- 使用预训练的语言模型(e.g. BERT, GPT-3)
大型transformer模型
使用在存在大量未标注数据情境下
fine tuning for downstream tasks
图片/视频特征
传统方法手动训练:尺度不变特征转换(Scale-invariant feature transform, SIFT),手动抽取特征。是一种电脑视觉的算法,用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量。
深度神经网络模型预训练:
ResNet(使用ImageNet训练(图片分类))image
I3D(使用Kinetics训练(动作分类)) video
2.5 数据科学家的日常
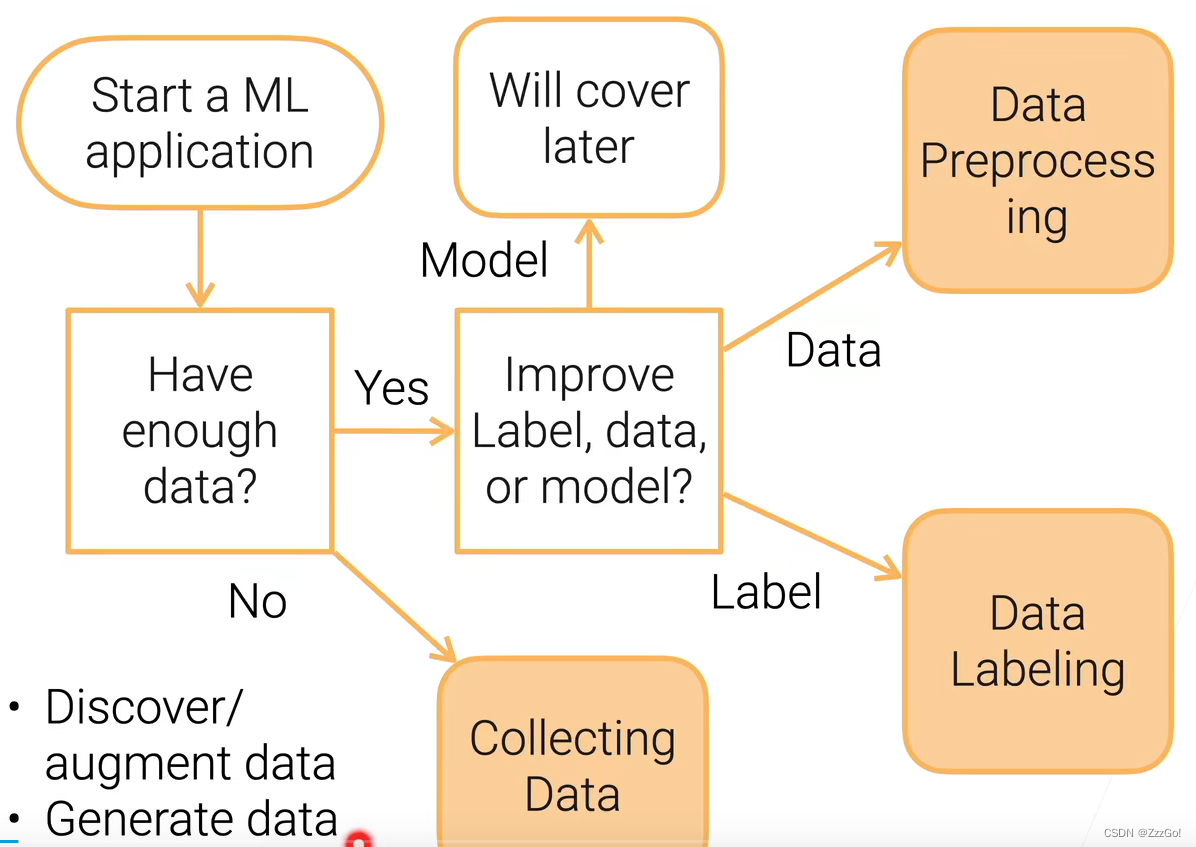
数据标注/数据规模的权衡
数据的质量:多样性、无偏性、公平性
大规模数据的管理:存储、处理、版本(回滚)、安全















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









