







题目描述
给你一个字符串数组 words ,找出并返回 length(words[i]) * length(words[j]) 的最大值,并且这两个单词不含有公共字母。如果不存在这样的两个单词,返回 0 。
示例 1:
输入:words = [“abcw”,“baz”,“foo”,“bar”,“xtfn”,“abcdef”]
输出:16
解释:这两个单词为 “abcw”, “xtfn”。
示例 2:
输入:words = [“a”,“ab”,“abc”,“d”,“cd”,“bcd”,“abcd”]
输出:4
解释:这两个单词为 “ab”, “cd”。
示例 3:
输入:words = [“a”,“aa”,“aaa”,“aaaa”]
输出:0
解释:不存在这样的两个单词。
提示:
2 <= words.length <= 1000
1 <= words[i].length <= 1000
words[i] 仅包含小写字母
官方题解(位运算)
来源:https://leetcode.cn/problems/maximum-product-of-word-lengths/solutions/1104441/zui-da-dan-ci-chang-du-cheng-ji-by-leetc-lym9/
方法一
为了得到最大单词长度乘积,朴素的做法是,遍历字符串数组 w o r d s words words 中的每一对单词,判断这一对单词是否有公共字母,如果没有公共字母,则用这一对单词的长度乘积更新最大单词长度乘积。用 n n n 表示数组 w o r d s words words 的长度,用 i i i 表示单词 w o r d s [ i ] words[i] words[i] 的长度,其中 0 ≤ i < n 0≤i<n 0≤i<n,则上述做法需要遍历字符串数组 w o r d s words words 中的每一对单词,对于下标为 i i i 和 j j j 的单词,其中 i < j i<j i<j,需要 O( l i × l j l_i×l_j li×lj) 的时间判断是否有公共字母和计算长度乘积。因此上述做法的时间复杂度是 O( ∑ 0 ≤ i < j < n l i ∗ l j \sum_{0≤i<j<n} l_i*l_j ∑0≤i<j<nli∗lj),该时间复杂度高于O( n 2 n^2 n2)。
如果可以将判断两个单词是否有公共字母的时间复杂度降低到 O(1),则可以将总时间复杂度降低到O( n 2 n^2 n2)。可以使用位运算预处理每个单词,通过位运算操作判断两个单词是否有公共字母。由于单词只包含小写字母,共有 26 个小写字母,因此可以使用位掩码的最低 26 位分别表示每个字母是否在这个单词中出现。将 a a a 到 z z z 分别记为第 0 个字母到第 25 个字母,则位掩码的从低到高的第 i i i 位是 1 当且仅当第 i i i 个字母在这个单词中,其中 0 ≤ i ≤ 25 0≤i≤25 0≤i≤25。
用数组 masks 记录每个单词的位掩码表示。计算数组 masks 之后,判断第 i i i 个单词和第 j j j 个单词是否有公共字母可以通过判断 masks[ i i i] & masks[ j j j] 是否等于 0 实现,当且仅当 masks[ i i i] & masks[ j j j]=0 时第 i i i 个单词和第 j j j 个单词没有公共字母,此时使用这两个单词的长度乘积更新最大单词长度乘积。
解法一
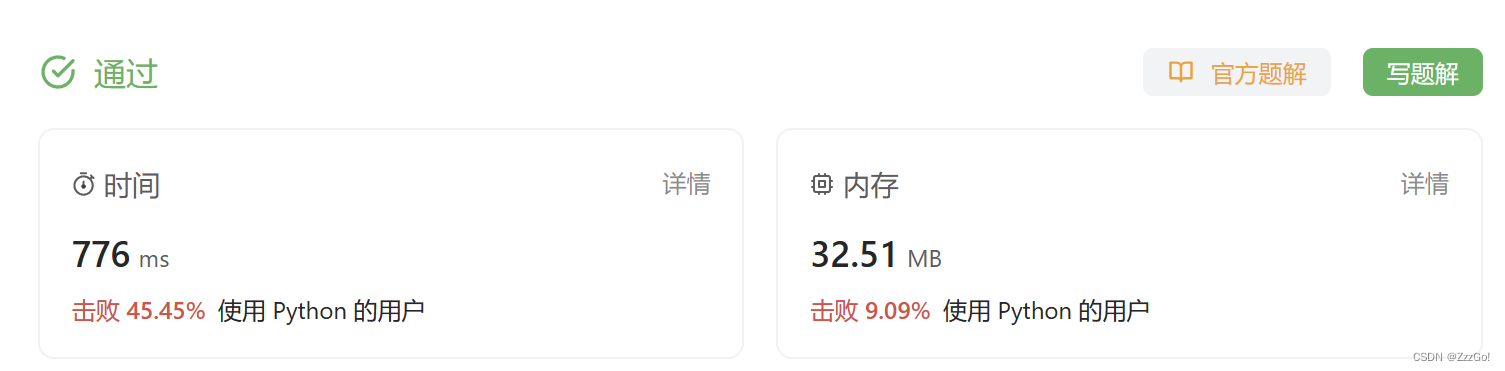
from itertools import product
from functools import reduce
class Solution(object):
def maxProduct(self, words):
"""
:type words: List[str]
:rtype: int
"""
masks = [reduce(lambda a, b: a | (1 << (ord(b) - ord('a'))), word, 0) for word in words]
ans = [len(x[1]) * len(y[1]) for x, y in product(zip(masks, words), repeat = 2) if x[0] & y[0] == 0]
return max(ans) if ans else 0
【补充知识】
-
ord() 函数:
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。 -
reduce() 函数:
reduce() 函数会对参数序列中元素进行累积。函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。reduce(function, iterable[, initializer])
-
zip() 函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。a = [1,2,3]
b = [4,5,6]
c = [4,5,6,7,8]
zipped = zip(a,b) # 打包为元组的列表:[(1, 4), (2, 5), (3, 6)] -
product() 函数:
用于求多个可迭代对象的笛卡尔积from itertools import product
a = [‘a’,‘b’]
b = [1,2]
res1 = product(a, b) # [(‘a’, 1), (‘a’, 2), (‘b’, 1), (‘b’, 2)]
res2 = product(a, repeat=2) # [(‘a’, ‘a’), (‘a’, ‘b’), (‘b’, ‘a’), (‘b’, ‘b’)] -
位运算:
<< 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0
| 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1
& 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0
因此, ord(b) - ord(‘a’) 就是获取
w
o
r
d
s
words
words 数组中每个单词
w
o
r
d
word
word 的每个字母的 ASCII 码减去 ‘a’ 的 ASCII 码的值(0-25),1<<ord(b) - ord(‘a’) 就可以得到每个字母对应的掩码(唯一的,这里1也可以换成其他的非零数),1<<0:0,1<<1:2,1<<2:4,1<<3:8,…, 其实对应的二进制码就是 0,10,100,1000,…。reduce(lambda a, b: a | (1 << (ord(b) - ord(‘a’))), word, 0) for word in words 就是获得了每个单词
w
o
r
d
word
word 的掩码,这里的 | 运算可以看作是加运算。
因为单词里每个字母在掩码里都有唯一的标识(如果是 ‘a’,那么掩码里从右往左第 0 位就是1,如果是 ‘b’,那么掩码里从右往左第 1 位就是1,以此类推),接下来就只需要比对哪两个单词里的字母不存在交集(用 & 运算,重复了结果就不为0),得到符合条件的两个单词长度的乘积,然后返回最大值,如果不存在则返回0。
解法二
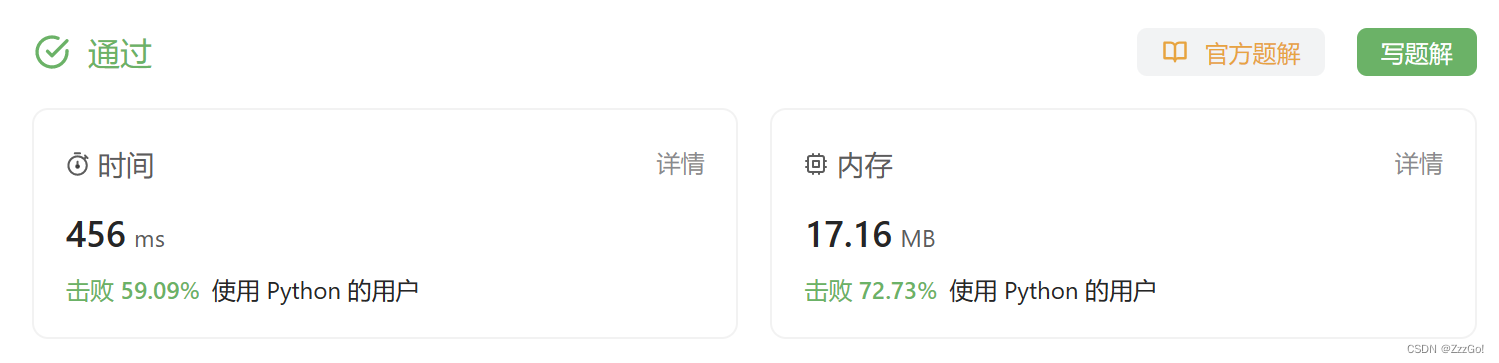
from itertools import product
from functools import reduce
class Solution(object):
def maxProduct(self, words):
"""
:type words: List[str]
:rtype: int
"""
masks = defaultdict(int)
for word in words:
mask = reduce(lambda a, b: a | (1 << (ord(b) - ord('a'))), word, 0)
masks[mask] = max(masks[mask], len(word))
ans = [masks[x] * masks[y] for x, y in product(masks, repeat = 2) if x & y == 0]
return max(ans) if ans else 0
由于数组 w o r d s words words 中可能存在重复的单词,但是每个单词的掩码是唯一的,我们可以用字典来进行存储,键为单词的掩码,值为单词的长度,进一步优化。
解法三

from itertools import combinations
from functools import reduce
class Solution(object):
def maxProduct(self, words):
"""
:type words: List[str]
:rtype: int
"""
masks = defaultdict(int)
for word in words:
mask = reduce(lambda a, b: a | (1 << (ord(b) - ord('a'))), word, 0)
masks[mask] = max(masks[mask], len(word))
ans = [masks[x] * masks[y] for x, y in combinations(masks, 2) if x & y == 0]
return max(ans) if ans else 0
另一位朋友的题解里建议把 product() 函数替换成 combinations() 函数,可以避免了与自己运算的情况,提高效率。
【补充知识】
- combinations() 函数:
combinations(iterable, r) 方法可以创建一个迭代器,返回 iterable 中所有长度为 r 的子序列,返回的子序列中的项按输入 iterable 中的顺序排序。
(product() 是排列,combinations() 是组合)from itertools import combinations, product
list1 = [1, 3, 4]
res1 = combinations(list1, 2) # [(1, 3), (1, 4), (3, 4)]
res2 = product(list1, repeat=2) # [(1, 1), (1, 3), (1, 4), (3, 1), (3, 3), (3, 4), (4, 1), (4, 3), (4, 4)]















 1601
1601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









