






1. 所需要导入的库
import seaborn as sns
import numpy as np
# 机器学习:sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionCV
# 深度学习:tf.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import utils
2. 数据集
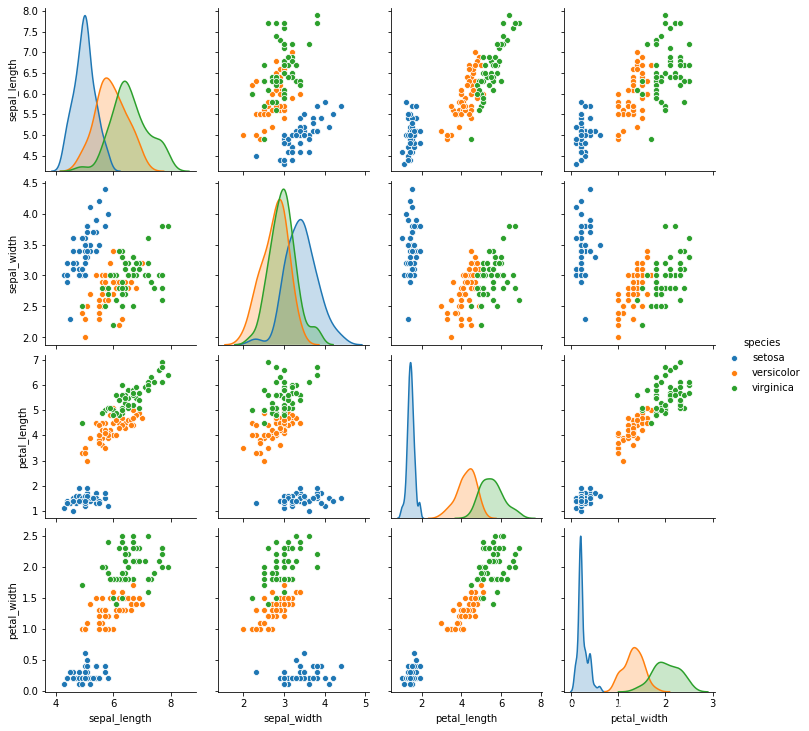
- 特征有4个,目标值为鸢尾花的类别,有3个分类
# 特征之间的关系,hue是目标值
sns.pairplot(iris, hue='species')
3. 获取特征值、目标值,划分数据集
# 获得数据集的特征值和目标值
X = iris.values[:, :4]
y = iris.values[:, 4]
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
4. 使用sklearn构建模型并训练
4.1 步骤
- 实例化估计器
- 模型训练
- 模型评估
4.2 代码实现
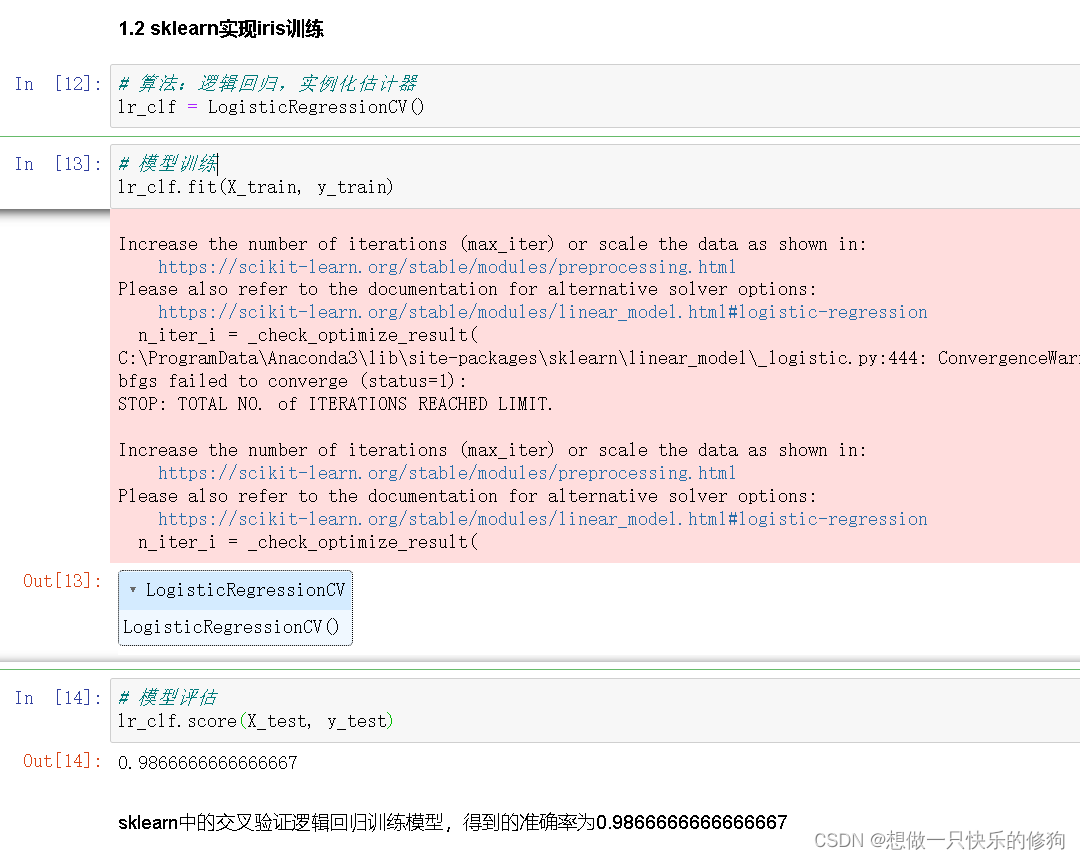
# 算法:逻辑回归,实例化估计器
lr_clf = LogisticRegressionCV()
# 模型训练
lr_clf.fit(X_train, y_train)
# 模型评估
lr_clf.score(X_test, y_test)
- 结果:
5. 使用tf.keras构建模型并训练
5.1 步骤
- 数据处理(将目标值进行独热编码)
- 模型构建
- 模型预测和评估
5.2 代码实现
5.2.1 独热编码
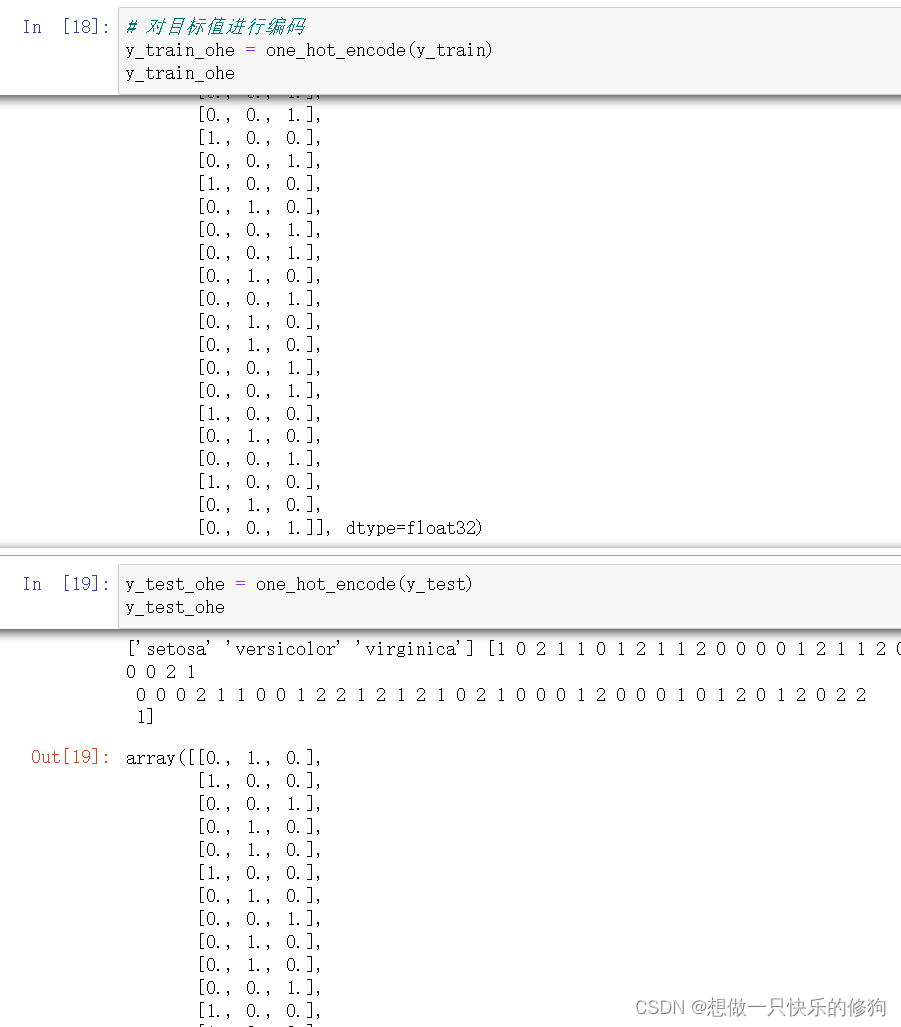
# 对目标值进行独热编码
def one_hot_encode(arr):
# 获取目标值中的所有类别并进行热编码
uniques, ids = np.unique(arr, return_inverse=True)
print(uniques, ids)
return utils.to_categorical(ids, len(uniques))
- 原始目标值:
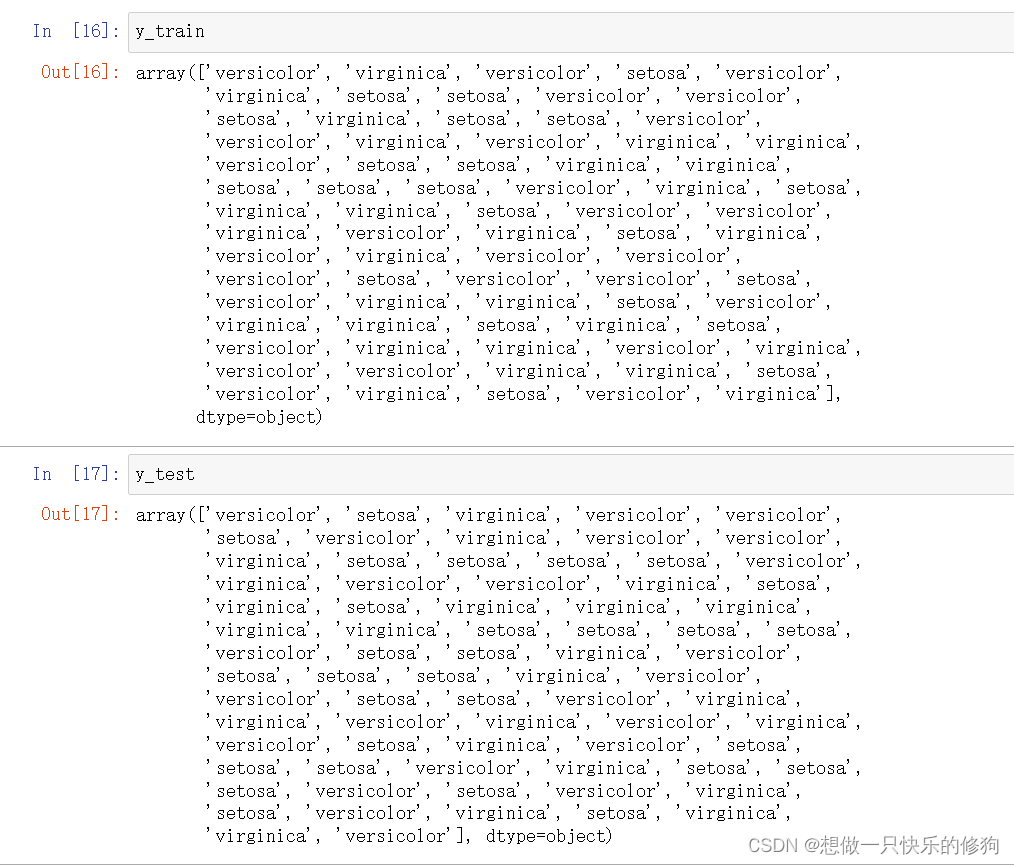
- 独热编码后:
5.2.2 模型构建
model = Sequential([
# 隐藏层(输入有4个特征)
Dense(10, activation='relu', input_shape=(4, )),
# 隐藏层
Dense(10, activation='relu'),
# 输出层(输出有3类)
Dense(3, activation='softmax')
])
- 查看模型结构:

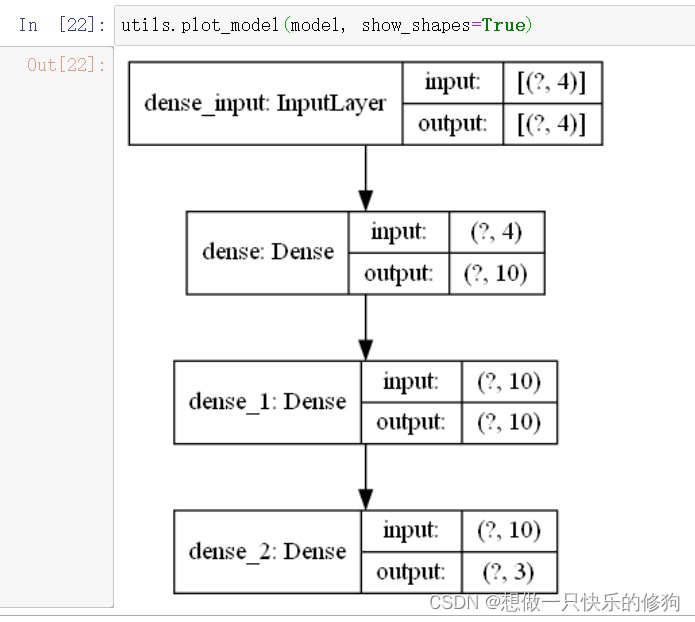
上图需要下载库而且要重启电脑才可以
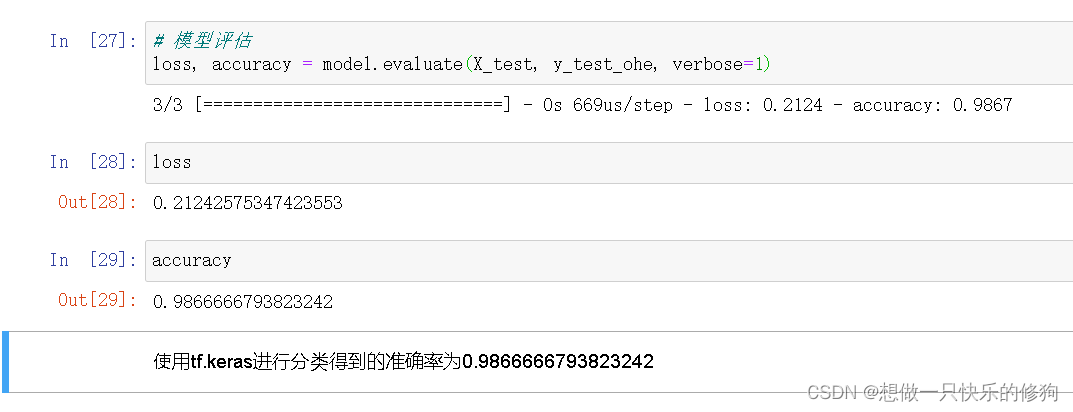
5.2.3 模型预测与评估
# 模型编译(优化器、损失函数使用交叉熵损失函数)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 对数据进行类型转换
X_train = np.array(X_train, dtype=np.float32)
X_test = np.array(X_test, dtype=np.float32)
# 模型训练(verbose=1 ==> 打印训练过程)
model.fit(X_train, y_train_ohe, epochs=10, batch_size=1, verbose=1)
# 模型评估
loss, accuracy = model.evaluate(X_test, y_test_ohe, verbose=1)
-
模型训练过程:

-
模型评估结果:
6. 参考
P.S. 这是我看黑马的视频的笔记~
















 9394
9394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











