






SORA技术报告解读
文章目录
概要
最近半年一直在做垂直LLM业务,本来打算写写LLM的文章和技术原理,但是文生图对我吸引力更大,故最近开始从0研究下,10分钟快速一览。
SORA的技术报告引起了不少热议,很多对技术报告的分析和解读也有不少,在我们好奇OPEANI在1分钟视频中保持比较高质量的连贯性之余,对于从业者来说,在尚未得到官方全部细节公开下,除了各种猜测以及对OPENAI研究者苦心孤诣的敬佩,对其背后一些前人的工作也同样值得我们学习。接下来我将进入正题,尽力保持全程干货,由于本人多模态生成AI的实际经验并不足,网上的推测也很多很详细,这里说一下自己的理解且不只是为了猜测而是顺便梳理一下现在的SOTA方法和思路才更为重要, 草率的记录下,等后续更新完善。
PS:具体的报告可以参考官,在阅读本文前,最好有Transformer、diffusion 、Dalle系列的基础背景知识。
SORA整体概要
OpenAI开发的视频生成模型Sora,作为一个扩散模型,并将其视为模拟真实世界的潜在世界模拟器。之前的视频生成模型都无法处理不同时长、分辨率和比例的视频,局限于特定类别或时长较短的视频,这就是SORA主要的强大之处,想具备通用世界模拟器的能力。
关键性的技术方案解析
分为三大模块进行解析:1.Video编码器 2 Video diffusion transfromers结构(包含conditioning) 3.Video解码器 ,其中实现覆盖了SORA的各项特点,可变尺度、可变时长、时空path等。
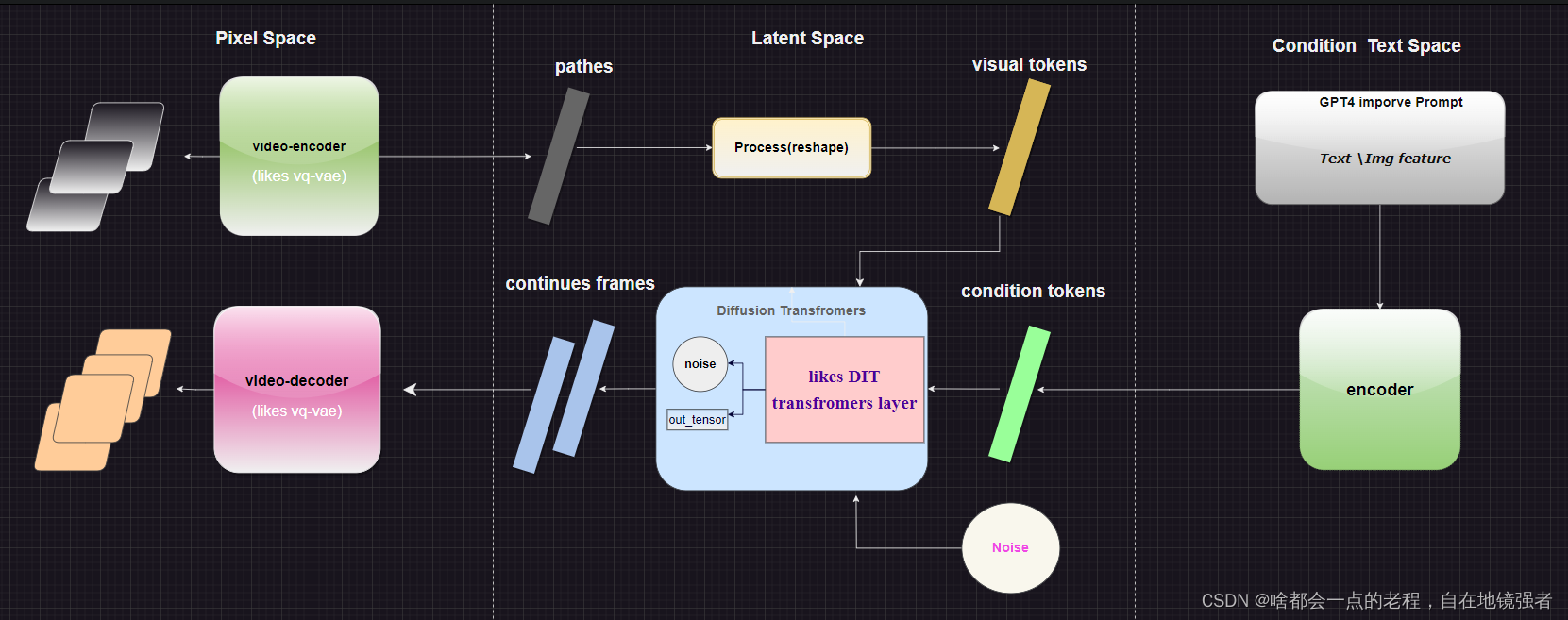
1. 视觉类型的特征嵌入和处理-video encoder
OPEANI称通过GPT的启发,需要像其他形式的文本一样,将视频、图像转化为统一形式的”Token”,这在CV领域已经早被VIT等工作证明了可行性,所以将视觉类数据分解为patch是没有任何问题的,但是这里需要将视频进行处理,也就是将视频帧分解成Spacetime patches,那么怎么具体做的呢?其实很简单,就是用一种类似AE结构的编解码器。

1.1 压缩视频的特征网络模型是什么?
为了达到上述视觉token化的目标,(先将视频压缩到一个较低维度的潜在空间,再分解为时空补丁,从而将视频转化为补丁),训练了处理视频的编码器模型,理论上我们只需要构建一个video encoder网络,早期最简单的方式:直接reshape 成二维张量放进去做无监督训练即可。再复杂点的就是针对视频处理的3DCONVNET和transformers的结构一样可以处理,从参考和各方提供的猜测来说,比如这个encoder的模型可能就是一个video transformer结构,也有说是convnet,所以对于结论来说,这个encoder到底具体是什么?当前没法100%确定,但也是有迹可循。
很多推测还是基于VAE类思路的一个编码器,比如VAE的进一步变体VQ-VAE,这里呢简明扼要说一下:VA-VQE呢是解决了原始的PIXEL-CNN的回归问题,即逐像素预测,其实等价于LLM的自回归,但是这一个离散问题,导致连续像素之间的分类不易,简单来说VQ-VAE引入了一个量化手段CODEBOOK机制,将输入做了离散的特征表达,其实在代码里只需要加一个liner层既可以实现,为什么要这么做呢?那是因为VAE是假设潜在空间服从高斯分布,即不是离散的,那使用自回归需要简历一个离散的特征编码(类似onehot),所以需要引入一个离散转化的方式。
至于是transfromer还是CNN的结构, 之前的大多工作来说都是CNN(单指encoder),报告中提到的VideoGPT用的是vq-vae+Transformers的框架处理的视频,encoder里面的属于是3D-COVNET
下面分别的VIDEOGPT的流程图和因果3D CNN的结构图
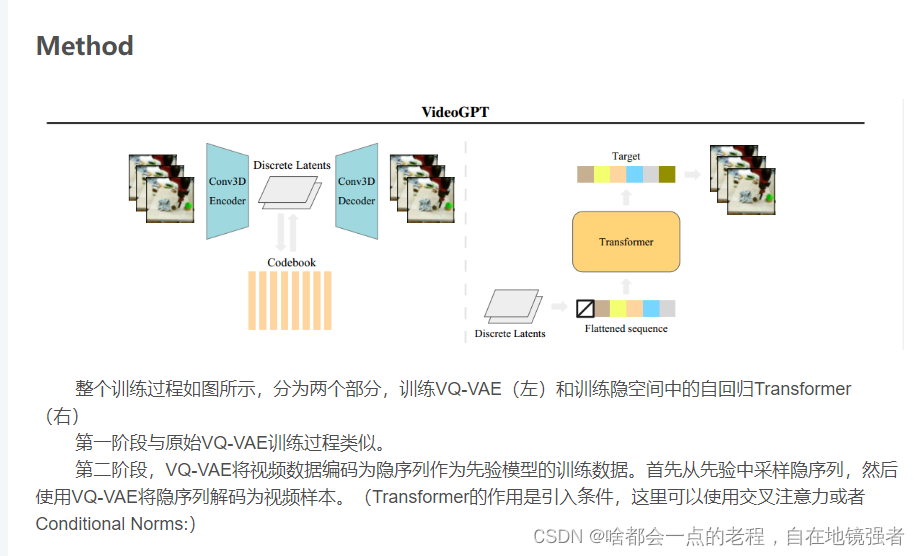
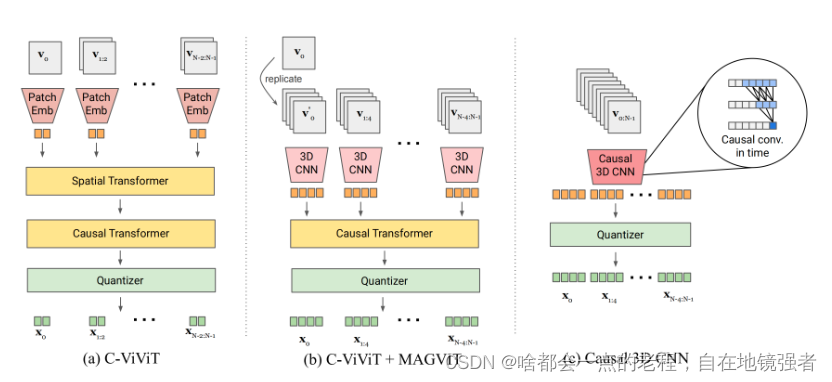
顾名思义,因果注意力CNN就是每一帧输出都是通过前面所有帧来计算的,所以能够独立对一帧进行处理,这很好解决了且前面3DCNN不能处理单独的一个视频第一帧的问题。
1.2 如何处理不同分辨率的训练和推理问题?
上述所讲的是一个基于图像和视频encoder的一个特征压缩的方法,但细节在于如何处理不同尺度的图片。在SORA结论中,使用不同分辨率的图像和视频训练会有更好的生成效果。不少解读中也指出使用的是NAVIT(谷歌的 Patch n’ Pack (NaViT) 论文成果)的transformer模型来处理不同分辨率的图像,这样的好处就是:1.后验证的高质量视频 2.采样灵活性, 而其关键点对应官方描述,就是时空patch的优势。
不同分辨率、持续时间和宽高比的视频和图像上进行训练。在推理时,我们可以通过在适当大小的网格中安排随机初始化的补丁来控制生成视频的大小。
我们先讨论训练部分:
动机:Google的NaViT,就是为了解决前面提到的:一般对于不同尺度最简单的是做成固定大小,但是这样每一步都需要进行图像预处理,会增加额外的计算处理时间,所以提供动态输入的模型来解决这个问题。
借助Patch的分块使得能够在不同尺度和时间片、不同宽高比的视频和图像数据上进行训练。
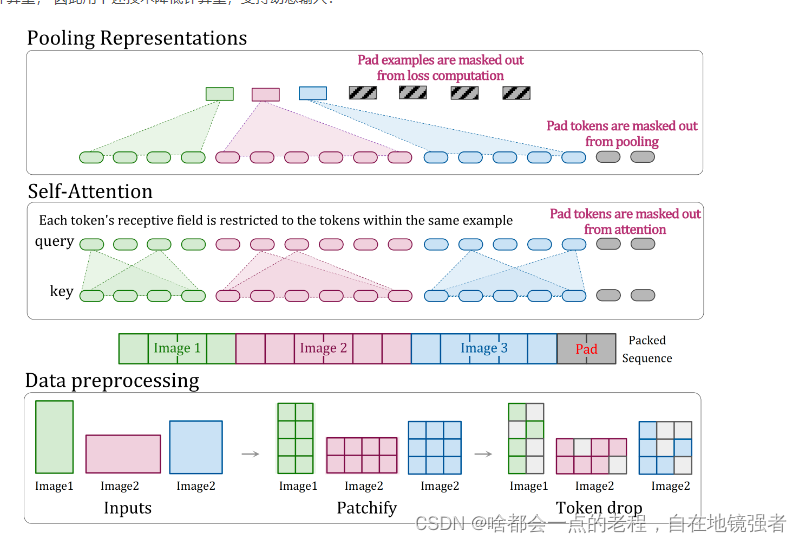
如上图数据处理流程中,不同尺度的图像在处理中,经过PTACH后,使用了一种稀疏正则化的处理方式“token drop”去处理了图像,然后flatten后,做成一个序列,再传入到下一阶段的transfromer结构中。
因此SORA很可能有类似这样一种思路的patch处理去来解决不同尺度训练问题。
这里的不同是SORA引入了视频的时间和空间嵌入, spacetimes patches等价于变成了离散的特征表达,再flatten后就可以扔给diffusion模块处理了。.
接着在推理过程中,如何控制输出的图像尺度大小呢?
At inference time, we can control the size of generated videos by
arranging randomly-initialized patches in an appropriately-sized grid.
意思是通过指定大小的网格来实现,通过在一个适当大小的网格中随机初始化的补丁,具体怎么实现呢?个人猜测模拟下,应该是有两个参数值需要确定,一个是网格大小gride_size,一个是补丁大小patch_size,这样通过调整这两个参数,你可以控制生成图像的最终大小。具体而言,生成图像的大小将为 patch_size * grid_size,当然这是个人猜想。
第一模块的encoder部分,简单总结下结论:
一个基于视频的编码器,该编码器通过对视频图像:
1.将视频特征压缩到Latent空间
2.提取视频序列帧为时空patch,可能使用的video transformer或者3DCNN去编码patch
3.可能用Drop方式使用分辨率不统一现象,拼接后flattn成序列,推理时候根据网格和patch控制输出大小
2 Scaling transformers 扩散模型
这和上一节有着必然联系,也是非常核心的一个Baseline证明,就是我们不管是从CV还是NLP或者其他语音等模态的AI在近三年都能够看到transformer的出现,这其实已经说明了问题,AI结构正在趋近于”大一统“和”扩展性“,比如早些年的SWIN-transformers系列的理念,openai也是借助于LLM自回归模型 在文本上的成功,拓展到CV多模态领域上。所以个人认为核心就是设计理念上transformer符合”统一“和”扩展“的性质。具体如何印证呢?
参考工作DIT:这是William(Bill ) Peebles, Saining Xie的一个论文成果,项目在GIT上以DIT命名开源。其中前者Bill Peebles也是SORA技术报告中的主要研究人员,所以可想而知,后者谢赛宁也对SORA的工作表示了赞赏,这个篇论文绝对促进了SORA的研究进度,各方猜测也都是存在比较大的关系,但是不论SORA具体怎么实现的,都不影响我们是梳理和学习,接下来我们可以先了解下,这和SORA的设计有何关系?
我们先来继续回顾SORA的介绍:
In this work, we find that diffusion transformers scale effectively as video models as well. Below, we show a comparison of video samples with fixed seeds and inputs as training progresses. Sample quality improves markedly as training compute increases.
简单来说,sora作为一个基于transfromer的扩散模型,那么diffusion经典的主体结构一直是UNET,而sora和其参考的DIT结构就是主要就是:VAE encoder + ViT + DDPM + VAE decoder,用transformer结构替换UNET。
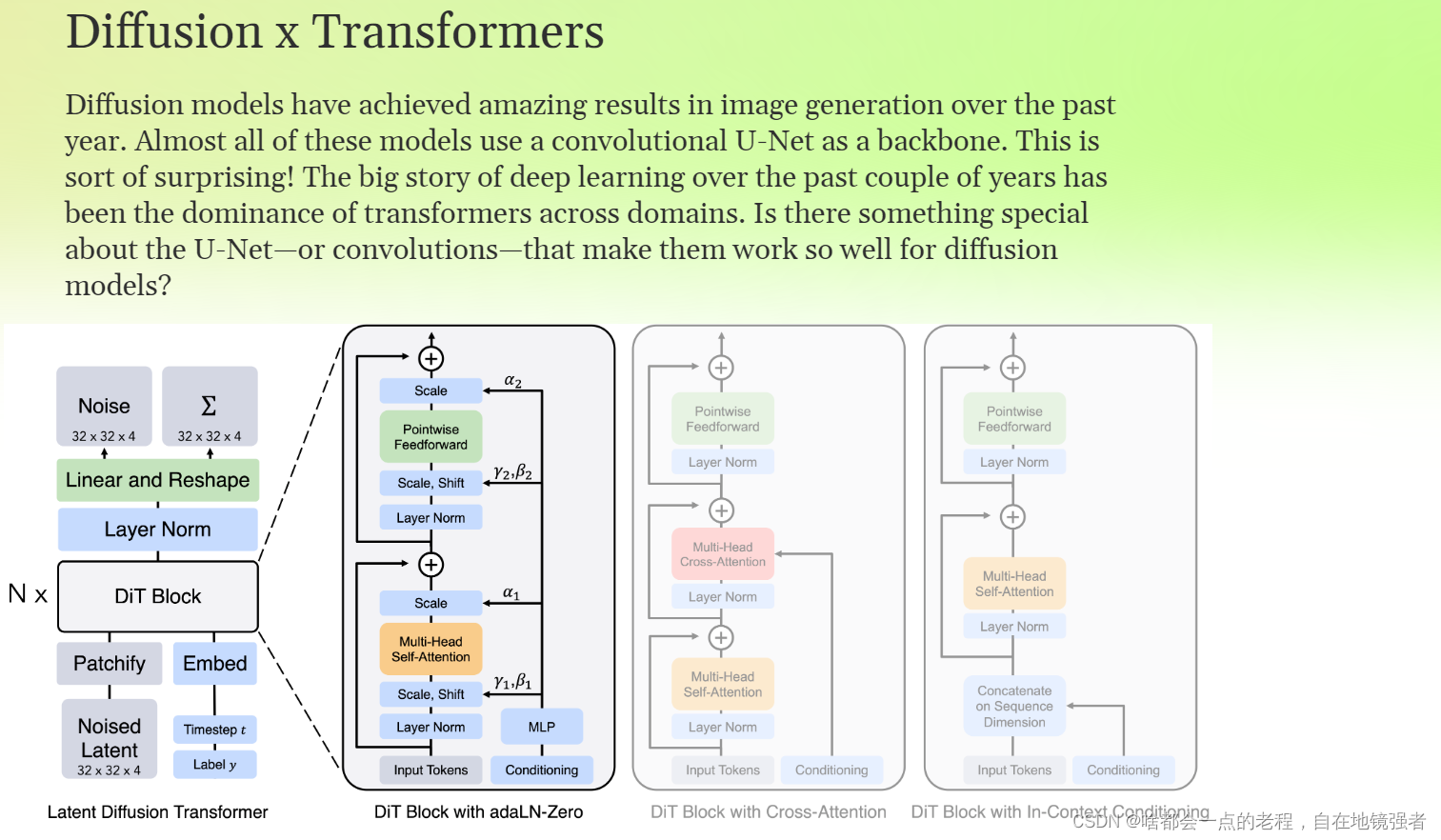
主体还是latent diffusion思路,DIT的主要处理过程这是通过transfromer分出了path,得到潜在噪声特征,验证transformer diffusion的结构有效性。
那么SORA对视频进行了降温的时空特征后,可以做到视频图像进行联合训练,其实难点就是需要对时间和空间特征进行捕捉,值得注意的是SORA是否和DIT进行类似的处理,假设输入到这个diffusion结构种是一组flatten后的patch,那么DIT会对这个PATCH进行转成一个方形,那么SORA对于时空patch会如何处理?这点细节确实值得思考,但目前看来如果每个token包含时间和空间信息,那么不管用哪种作为最终TOEKN表示,其实就是适配diffusion能处理即可(这点后续有新的认知会补正)
3. 生成解码器以及文本描述部分
Openai训练了一个transformer解码器,来将潜在空间映射回像素,生成连续帧。这点要谈到他们的核心成功dalle系列,练文本到视频生成系统需要大量带有相应文本字幕的视频,DALLE3里面训练了字幕生成caption模型,然后使用它为训练集中所有视频生成文本字幕,还利用 GPT-4将简短的用户 prompt 转换为更详细的文本描述,(长文本描述非常重要,训练的混合比例高达95%)然后发送到视频模型,这样的训练方式可以增强指令跟随能力,这也是dalle3的亮点,这种数据增强的思路,非常符合OPENAI 大力出奇迹的风格。
其实后面部分流程和sd模型几乎差不多,毕竟这个SORA还是一个diffuison,
这里也可以确定SORA的解码器就是一个类似于VAE\VQ-VAE的latent decoder应该源于dalle3,这也和自回归编解码器的token离散化表达对上了。
小结
对于SORA能够学习物理规律 ,这点个人并不太认同,我觉得还是因为大数据下的因果结构带来的训练涌现力,感兴趣的可以看看Meat的V-JEPA,文章不足和待补充的地方,会随着更新和修改。
简单梳理了下,对于AIGC人工智能热潮,数据和算力真的要求太高,但同时对于从业者要求也是越来越高,该篇文章会动态更新,感谢阅读。


















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









