







 博主分享了对YOLOV5目标检测模型的改进和实验,包括添加注意力机制、优化头部结构和标签分配,探讨了不同层次使用注意力机制的影响。文中还提到了SwinTransformer的适配问题和GAM的实验结果,以及对源码的修复和优化。此外,博主宣布开源相关项目,并持续维护更新。
博主分享了对YOLOV5目标检测模型的改进和实验,包括添加注意力机制、优化头部结构和标签分配,探讨了不同层次使用注意力机制的影响。文中还提到了SwinTransformer的适配问题和GAM的实验结果,以及对源码的修复和优化。此外,博主宣布开源相关项目,并持续维护更新。
相关文章系列:
目标检测之深度学习专题(一)FCOS-“抛砖引玉“!验证检测模型理解的最好”试金石“——细节决定成败,不看就会败北!
一点就分享系列(实践篇3-上)
一点就分享系列(实践篇3-中)
一点就分享系列(理解篇5)补更必看:SwintransformerV2.0版本的改进以及使用理解(上篇)
关于后续的项目更新和升级,请移步关注我的新博客V7篇:V5、v7合并维护升级中,新篇博客地址,解决了本篇的后续事情
(GIT第一时间更新,博客慢一些)
温馨提示:因为工作太忙且做的项目和视觉任务不止于目标检测,所以即使文章没有更新产出,也会在GIT上定期维护的v5,我每周最少会定期两次和原版本YOLOV5去合并,因为官方那边更新太快,不过大部分都是工程代码功能性调整和优化,并且每次更新我都会手动去调整了解更新的细节,再合并代码,并且保证我的所有改动同样适配!!有时候朋友拉到的代码,可能是我合并出现了些问题导致的低级错误,这时候可以私信提醒我或者github ISSUE上留言。
说明: 最近大半年涌现了很多公众号和论文,我看到了相似的改动和换汤不换药的YOLOV5魔改,失望的是虎头蛇尾的创意和工作,因为一直在做工程开发,我精力达不到足够的研究时间,国内的AI风气本来就一直不看好,我觉得大家要有自己的想法,我会抽时间慢慢完善下所有的实验记录。
一点就分享系列(实践篇3-下 )
前言:
最近一个字!忙!!!很多朋友在催更,不是我不想发,是真的需要实验,这篇的核心本来是:对v5头部和label assign进行创新和实验,故此我需要梳理下现在比较sota的anchor 匹配机制,进行学习理解并编码,这无疑需要大量时间,但是我目前的工作强度是不允许的,而且最近打算开源个pytorch人脸项目+ 基于deepstream的C版本sdk项目(已在GIT上了),就是每天到家都是11点多了,晚上还要开2个小时的远程工作,主要是时间不够用,一个人实在做不了这么多,但是我想法和思路很多,真的缺帮手,所以公开招募!志同道合的小伙伴一起做开源项目并长期更新维护(通用检测、人脸识别、ocr等等)
但是,此时此刻(2021年的9月15号11点50分~),我决定先开个头,如果说上篇是初窥门径,中篇就是班门弄斧,但是下篇的东西绝对会是小有所成, 希望我的文章和人都在进步,我始终认为:如今的深度学习是特殊的,特殊性在于它是最具备时代时间性的技术和理论体系结合的产物,抛开时间发展和算力支持就没什么说的必要了。。
言归正传!大概分享下这篇要做的事情,核心肯定是上述说的,但是呢近期看到了不少优秀的文章和项目,实在心痒,所以文章大致定个基准内容。。
所有开源项目:定期不定时更新维护!
关于我的yolov5项目my github,和作者更新同步且保持添加自己的idea。(代码有时候因为和作者的merge还有点问题,我发现就会立刻改好上传 一般都是些代码优化变动 也可以提醒我)实验有提升的,通过博客或者git PR提交方式联系,感谢反馈!
一点就分享系列(实践篇3)
- 近期更新一览(有比较急的问题挂issue):
- 回顾总结+“展望
- 一、关于yolov5的三个“彩蛋”
- 0. 修改心得和建议(2021-9/24 ):
- 1、一些源码细节“彩蛋”、(2021/10/11 更新merge v5仓库,之前的程序问题应该已经解决)
- 2. 2021/1/30——修复ASFF_Detect的检测头代码部分
- 3. 2021/1/30 更新——Swin_Transformer整合Yolov5阶段性进展,swin的适配比较麻烦,目前只初步调好了结构,还有很多细节要整理,最晚年后整理更新,
- 4. 2022/3/16 SWINV2.0基本更新:目前结论是作为某一层注意力机制正常使用,但是全Backbone训练极难,故在研究思考中,同时调研了一些最新的论文,意外收获些思考:详情和说明看我的新博客理解篇5,这里不做解释、
- 5. 2022/3/16 更新加入GAM和其轻量化版本,目前结论原始的GAM看起来是比CBAM会更好,测试在Visrdone数据集上可以有1到2的MAP提升,我写在GIT上了,但是FLOPs过大,参考论文设计,如下设计说明:
近期更新一览(有比较急的问题挂issue):
-
2022/7/13 同步更新加入了yolov7的P6模型訓練部分代碼,p6是需要aux的所以需要添加Loss部分計算,代碼和CSDN持續更新中,可以移步最新的博客:yolov7解析和代码融合
-
2022/7/7 所有BUG已经解决,启用了CI ,添加了YOLOV7:今天早上看到V7更新了,于是下午过来下,还是有值得学习的点,先把代码合进自己仓库。
-
2022/5/23 合并更新了YOLOV5仓库的最新版本,作者代码有点小问题就是数据集会重复下载,这部分我没就没合并他的更新,引入了新的算子,看来他也在探索实验
-
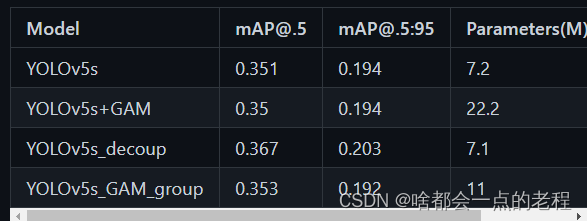
2022/3/26 测试下解耦训练结果/更新GAM注意力层代码:按照论文示意在大模型中使用分组卷积降低FLOPs,同步简单实验下,关于实验在闲暇之余都会慢慢完善的。 以small模型,在Visdrone数据下的简单验证:
- 2022/4/12 修复了一些常规的问题BUG并合并了V5作者的最新代码更新,大概包含之前缺少了一些可学习参数和代码优化。
- 2022/3/28 更新了swinv2.0的改动理解和一些思考,详情参考新的博客文章swinv2.0的改动使用理解
- 2022/3/25 验证了 YOLOV5S在解耦部分结构能提升一点MAP,但是FLOPs提升巨大
- 2022/3/16 添加了GAM注意力机制(并对于模型计算复杂度做了降低,使用组卷积)
- 2022/3.1 (不完整更新,供参考,怕忙断更,所以先放出部分修改,目前还在动态调试中) 按照SWinstransformer2 的改进点:修改了NORM层的位置/attention将dot换成scaled cosine self-attention,待更新的优化部分:1.序列窗口注意力计,降低显存开销 2、训练优化器
- 2022/2.28 添加了一个swintramsformer的Backbone和yaml示意结构,很多人把SWIN还像之前做成注意力层,但是其实swin设计是为了摒弃CNN去和NLP一统,而且精髓在于控制计算复杂度,其实backbone的全替换也许更值得尝试 ,内存开销和结构设计待优化
- 2022/2.22 忙里抽闲:更新了今天的yolov5的工程修复,修改了解耦头的代码风格,直接yaml选择参考使用,服务器回滚了代码。SWIN算子在,YAML文件丢失了,找时间从新写一个再上传,太忙看更新可能优先GIT,等有空博客细致归纳下
- 2022/2.6 ASFF使用的BUG已经修复;近期更新Swintransformer代码,简单说明下程序上其实是两种改法:1.类似算子层的修改,这个比较简单 2、全部替换成Swintreanformer,这个对于整个程序存在一定的代码修改地方,稍微复杂点。
- 2022/1.9 补充一些注意力算子GAM,原理后续CSDN说明,修复BUG
- 2021/11.3 合并最新的YOLOV5的改动, 替换了CSPBOTTLENNECK的LeakRELUw为SLIU,其余全是代码和工程规范修改
回顾总结+“展望
大致回顾总结:
实践篇3 yolov5上篇——始于2020年底,我使用v5进行初步改进,主要以添加各种简便的注意力插件或者融合层放在backbone后面为主(如asff,cbam,coord等),随后得到了一些经验性的结论和网友的实验反馈(比如有人用注意力在小数据集的dense 目标上有提点,通用数据集一般epoch上做实验想超过官方baseline难上加难~)和模型样本匹配的理解。
yolov5中篇——在2021年初,v5中篇加入了transformer算子mhsa(最新代码有bug,我抽空解决下),还有学术风波事件liduo的involution和2019 iccv的上采样算子等等,引入eiou和focal-iou,目前看来transformer在浅层并不好有效学习,且开销较大,只能学习swin-transformer的思路,不然还是像我原先那样放在底层和position embed做add去构建block?后来补了个bifpn,大概是这样子吧。
2021年中,我对fpn有了新的认知,在Fcos文章里我提到了,而且最近随着yolox的推出,我注意力都放在样本匹配和业务训练上了!其余呢?完成了一些自己的工作项目,效果还不错,对于一些trick的使用有了积累了不少经验~比如focal思想确实是效果比较好,小数据上易过拟合,训练直观上很难评估其效果,只有在业务场景下测试才能发现focal loss的优势,除了这些,打算给大家分享下,v5作者更新的代码细节补充,和一些关于v5的变体检测任务等等吧。还没想好,看时间更了~而且最近git会上一些开源项目,也是不断更新维护的,搬砖不易,希望大伙支持下。
一、关于yolov5的三个“彩蛋”
0. 修改心得和建议(2021-9/24 ):
- 网络模型Backbone的:不得不说v5的结构已经很优秀了,这边大部分的做法都是插注意力机制 ,大部分的注意力机制都是结合通道和空间去做文章,比如上篇中提到的SE,CBAM,Coord等等还有很多,还有transformer,这里说下注意力机制的一些经验:
首先,网络在浅层的参数其实是相对学习容易的,而深层则会困难,不适当的注意力机制会拖慢网络的训练——加大训练难度和参数量,以及开销,而根据我的个人学习经验,在网络结构中浅层主要还是通过3x3卷积去充分去提取局部特征,而在深层中其实3x3卷积在低分辨率的featuremap上或许就不如注意力机制了,试想一下:浅层的高分辨率图像局部信息提取局部相对更加重要,而深层的低分辨率特征在配备了注意力机制,比如transformer去替代3x3卷积,这也是我中篇分享BotNET的初衷,当然这里是有区别的,有的时候少即是多:比如大家知道,transformer是有个位置编码的,不管是swin还是别的SOTA级transformer的模型中,Position embedding 都是必备的,但是通过上篇尴尬使用Involution我思考到,前面的卷积大概是可以做的很好了(不然现在这么多纯CNN的模型怎么达到SOTA的?)那么如果在使用self-attention算子的时候,或许不用加入position embedding?我只需要transformer的全局联系?这是也是我心中最好backbone的候选者!
为什么呢?目前来看self-attention不只是长距离依赖:
对于自注意力机制的使用:很多人与CNN相结合使用得到精度提升,个人理解:原因不仅仅是长距离的依赖,早期我们使用固定权重的滤波器提取边缘再到CNN,CNN也许是对应着高通滤波,而self-attention对应于低通滤波,这样从某种程度上可以解释互补之后的提升;
再来说NECK部分(我们这里不说解耦检测头):BIFPN,这个有很多朋友反馈在自己数据集上有提升,那么通过上述分析,BIFPN是否可以取消权重的融合,为什么呢?因为权重融合其实就是注意力机制,那么就如上所述,有利就有弊吗,而且聚合网络本来就是加大了模型的开销,最重要的是:我在Fcos文章中的理解其实强调了,FNP/PA/BIFPN,其实核心是多个head而已,确实4个head的V5就是很强啊!所以!<font color=#13AAA >总结下,个人认为如果在网络层的改动:
1.深层加入self-attention去替换3X3卷积;该sefl-attention可以不带位置编码。
2.聚合用BIFPN(可以不用权重链接),当然还有别的设计结构和层数设计,这个也是网络结构设计的一个难点,实验证明不同的结构设计确实会对性能有很大影响,但是研究这个硬件资源和时间都需要相当充裕。
3.还有就是做一些辅助设计,比如样本匹配中或者做一个多任务的联合设计,比如加入分割,然后推理时候去掉
1、一些源码细节“彩蛋”、(2021/10/11 更新merge v5仓库,之前的程序问题应该已经解决)
在Bot yaml的transformer的位置编码,用参数选项暂时屏蔽掉了,想法来自上述,关于修改模型的训练问题,修改后读取的权重是需要从新训练的,可以先拿个检测集学下,再用自己的数据集,这个只是暂时的,最近忙别的交待下这个事情的进度
1.1. 2021/10/20 更新之前merge的v6.0版本代码,解决了一些更新后的问题,详情改动参考博客说明
----->>>>V6.0最快速览:
简单来说6.0的改动就是贯彻精简二字,另外修复了一些程序问题,算法上比较有意义的修改就是替换掉了作者之前的FOCUS和SPP,选了更小的卷积作为替代,提升了速度,网络更加精简,具体看我博客的更新说明。
2. 2021/1/30——修复ASFF_Detect的检测头代码部分
快过年了,喘口气,看了下一堆网友问的”no stride“问题,我调试了一下午,发现并不是模型权重不一致,而是代码问题,这里跟各位表示下歉意,问题出在代码上,模型结构的属性需要存入Model里面,其中包含“stride”
3. 2021/1/30 更新——Swin_Transformer整合Yolov5阶段性进展,swin的适配比较麻烦,目前只初步调好了结构,还有很多细节要整理,最晚年后整理更新,
4. 2022/3/16 SWINV2.0基本更新:目前结论是作为某一层注意力机制正常使用,但是全Backbone训练极难,故在研究思考中,同时调研了一些最新的论文,意外收获些思考:详情和说明看我的新博客理解篇5,这里不做解释、
5. 2022/3/16 更新加入GAM和其轻量化版本,目前结论原始的GAM看起来是比CBAM会更好,测试在Visrdone数据集上可以有1到2的MAP提升,我写在GIT上了,但是FLOPs过大,参考论文设计,如下设计说明:
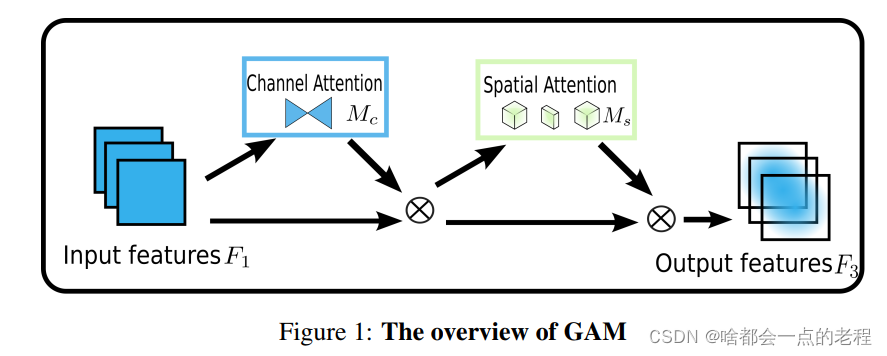
GAM目标是设计一种注意力机制能够在减少信息弥散的情况下也能放大全局维交互特征。作者采用序贯的通道-空间注意力机制并重新设计了CBAM子模块。整个过程如图1所示,并在公式1和2。给定输入特征映射,中间状态和输出定义为:
其中和分别为通道注意力图和空间注意力图;表示按元素进行乘法操作。
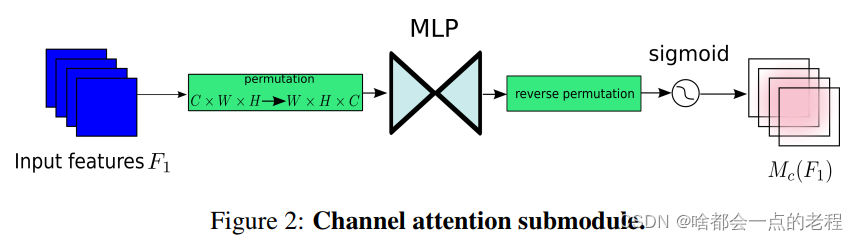
通道注意力子模块通道注意子模块使用三维排列来在三个维度上保留信息。然后,它用一个两层的MLP(多层感知器)放大跨维通道-空间依赖性。(MLP是一种编码-解码器结构,与BAM相同,其压缩比为r);通道注意子模块如图2所示:
空间注意力子模块在空间注意力子模块中,为了关注空间信息,使用两个卷积层进行空间信息融合。还从通道注意力子模块中使用了与BAM相同的缩减比r。与此同时,由于最大池化操作减少了信息的使用,产生了消极的影响。这里删除了池化操作以进一步保留特性映射。因此,空间注意力模块有时会显著增加参数的数量。为了防止参数显著增加,在ResNet50中采用带Channel
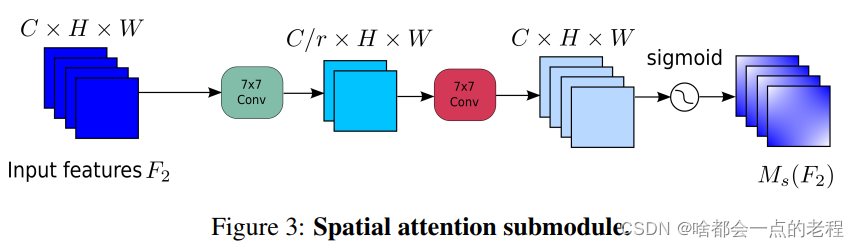
Shuffle的Group卷积。无Group卷积的空间注意力子模块如图3所示:
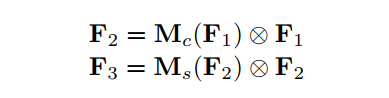
这里我的V5中的实现:
class GAM_Attention(nn.Module):
#https://paperswithcode.com/paper/global-attention-mechanism-retain-information
def __init__(self, c1, c2, group=True,rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(c1, int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(c1 / rate), c1)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(c1, c1//rate, kernel_size=7, padding=3,groups=rate)if group else nn.Conv2d(c1, int(c1 / rate), kernel_size=7, padding=3),
nn.BatchNorm2d(int(c1 /rate)),
nn.ReLU(inplace=True),
nn.Conv2d(c1//rate, c2, kernel_size=7, padding=3,groups=rate) if group else nn.Conv2d(int(c1 / rate), c2, kernel_size=7, padding=3),
nn.BatchNorm2d(c2)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
# x_channel_att=channel_shuffle(x_channel_att,4) #last shuffle
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
x_spatial_att=channel_shuffle(x_spatial_att,4) #last shuffle
out = x * x_spatial_att
#out=channel_shuffle(out,4) #last shuffle
return out


















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









