






 本文介绍了Mixture-of-Depths(MoD)——一种在Transformer语言模型中动态分配计算资源的技术,通过专家选择路由来决定计算路径。MoD通过限制每层处理的Token数量,优化模型性能和效率。文章详细解释了MoD的原理、其与传统Transformer的区别以及代码实现,展示了MoDE模型在计算资源管理上的潜力。
本文介绍了Mixture-of-Depths(MoD)——一种在Transformer语言模型中动态分配计算资源的技术,通过专家选择路由来决定计算路径。MoD通过限制每层处理的Token数量,优化模型性能和效率。文章详细解释了MoD的原理、其与传统Transformer的区别以及代码实现,展示了MoDE模型在计算资源管理上的潜力。
前言
简而言之,这是google对transformer一些改进设计,如果这个有效性能够证明并普及,那么下一个大模型的transformer范式就是这个了,当然同时也存在mamba和transformer的jamba崛起,不过现在主流还是transformer,让我们看下文章和代码复现的过程,如果看过我的MOE特别篇中MOE的部分,会更加清晰。
CV算法工程师的LLM日志(5)Mixture-of-depths——transformers改进结构 【15分钟代码和原理速通】
一 、Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
动机:大模型训练和推理中,有很多计算是没必要的,即在基于Transformer的语言模型中动态地分配计算资源(FLOPs),以优化模型的性能和效率.
Feature:
通过限制每层可以参与自注意力和多层感知机(MLP)计算的标记Token数量来强制执行总计算预算。
MoD方法使用静态计算图,与动态计算图技术不同,它允许在保持硬件效率的同时动态和上下文敏感地分配计算资源。
Moe结合可能性,能够减少模型的计算需求,还能够在保持或提高性能的同时加快模型的推理速度。
总结:核心点是通过路由决策来决定使用哪些层和跳过哪些层。
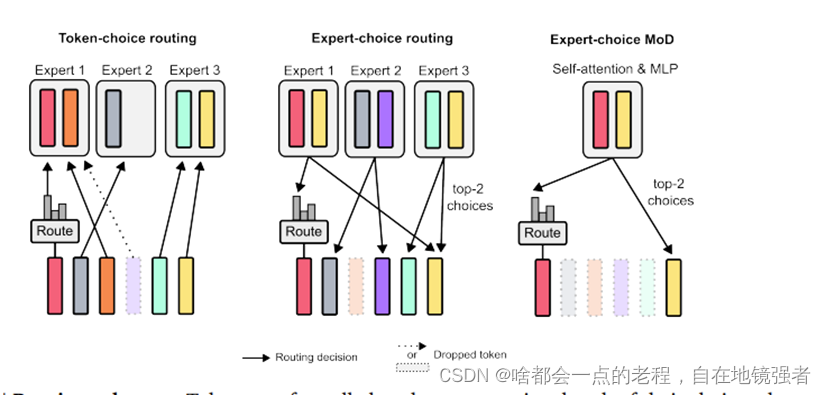
路由方案(Routing Schemes)(与MOE思路几乎一样)
Token-Choice Routing:
在这种路由方案中,每个标记Token根据自己的偏好被分配到不同的计算路径上。这通常是通过为每个标记Token生成一个概率分布来实现的,然后根据这个分布将标记Token路由到它最偏好的路径。
这种方法可能会导致负载均衡问题,因为不能保证标记Token会均匀地分配到所有可能的路径上。
Expert-Choice Routing:
与Token-Choice Routing不同,Expert-Choice Routing是由每个计算路径根据标记Token的偏好选择一定数量的标记Token(例如,top k个最高权重的token)。
这种方法确保了完美的负载均衡,因为每个路径都会获得相同数量的标记Token。但它也可能导致某些标记Token被过度处理或处理不足,因为一些标记Token可能因为权重高而被多条路径选中,或者没有被任何路径选中。
论文采用的Expert-Choice Routing方案中,由于只使用单一的计算路径,利用了一个隐含的知识:如果规定了每层处理的token数量K小于序列长度,则超出的TOKEN将被丢弃。这意味着,可以根据序列长度和计算容量,有选择地将标记Token路由到或绕过自注意力和MLP计算,从而在一个前向传播过程中减少FLOPs的消耗。
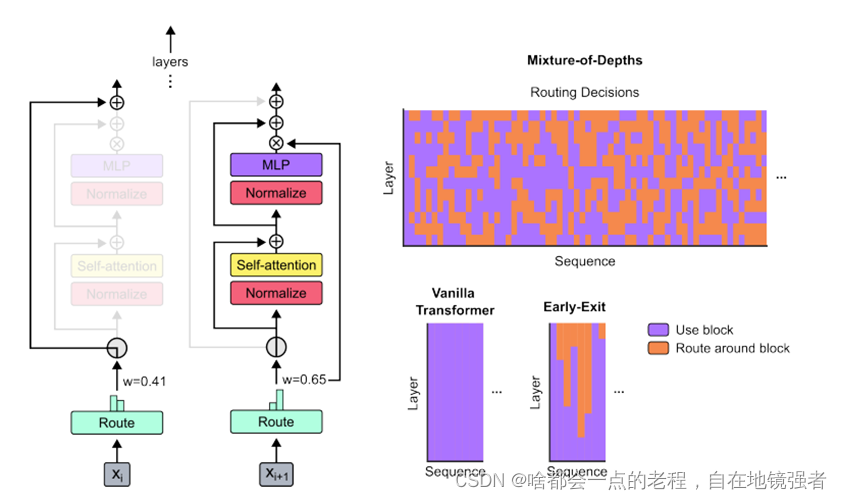
和传统的transformer架构区别:
- 每个mod-block增加了一个route 线性层
- 动态处理逻辑:决策负载均衡
- 动态分配token的比例决定top K,这个很重要对应上述说的token长度问题,(根据序列长度和计算容量,有选择地将标记Token路由到或绕过自注意力和MLP计算,从而在一个前向传播过程中减少FLOPs的消耗。)
二、MODE架构和MOD代码
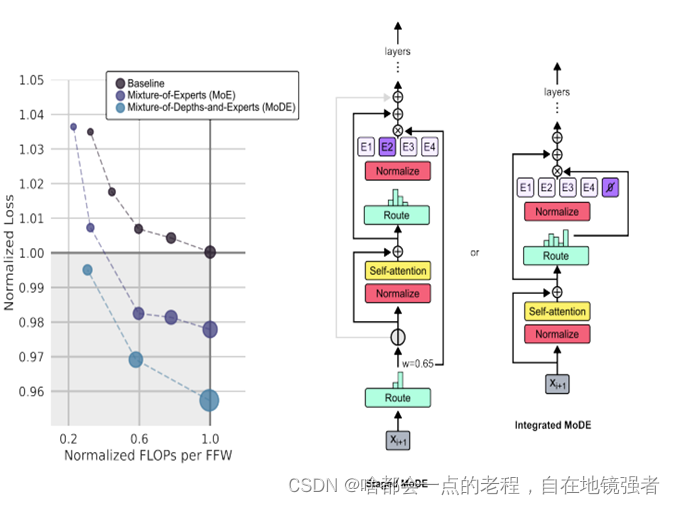
如图,MoD和MoE的结合,即MoDE模型,可以通过以下两种方式实现:
Staged MoDE:
在这种方法中,MoD机制首先被应用,它决定标记Token是否绕过某些层或者被送往自注意力机制。
然后,MoE机制被应用,它将参与自注意力计算的标记Token分配给不同的专家进行处理。
这种方式的优点是标记Token可以跳过自注意力步骤,直接被送往专家处理,从而节省计算资源。
Integrated MoDE:
在集成的MoDE模型中,MoD的路由功能被集成到MoE的专家选择机制中。
专家集合中包括了“no-op”(无操作)专家,这些专家相当于MoD中的跳过连接,即通过这些专家的标记Token不做任何计算。
路由机制会将标记Token分配给专家或者“no-op”专家,这样可以简化路由的复杂性,并且使得标记Token显式地学会选择是否绕过专家
MOD的结构基于已有的transfomer很可能像去年的MOE一样迅速普及在学术以及工业界。
代码
从代码上来看MOD可以作为即插即用的结构修改形式。针对上述提到的三个特点,可以参考代码:
代码源于Mod
import torch
import torch.nn as nn
from typing import Optional, Tuple, Any
from transformers import PreTrainedModel
class TokenRouter(nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.weight_predictor = nn.Linear(embed_dim, 1)
def forward(self, x):
weights = self.weight_predictor(x).squeeze(-1) # [batch_size, seq_len]
return weights
class MoD(nn.Module):
def __init__(self, capacity, block):
super().__init__()
self.router = TokenRouter(block.hidden_size)
self.block = block
self.capacity = capacity
self.training_step = 0
def forward(self,
x: torch.Tensor,
attention_mask: torch.Tensor,
position_ids: torch.Tensor,
past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]],
output_attentions: bool,
use_cache: bool,
cache_position: Optional[torch.Tensor] = None,
**kwargs: Any
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
b, s, d = x.shape
weights = self.router(x)
if self.router.training:
self.training_step += 1 if self.training_step < 1000 else 999
self.capacity = 0.125 + ((1 - 0.125) * (1. / self.training_step))
k = int(self.capacity * s)
top_k_values, top_k_indices = torch.topk(weights, k, dim=1, sorted=True)
threshold = top_k_values[:, -1].unsqueeze(-1)
selected_mask = weights > threshold
# Use torch.gather to select tokens
selected_tokens = torch.gather(x, 1, top_k_indices.unsqueeze(-1).expand(-1, -1, d))
selected_position_ids = torch.gather(position_ids, 1, top_k_indices)
# Create a causal mask for the selected tokens
if attention_mask is not None:
selected_attention_mask = torch.gather(attention_mask, 1, top_k_indices.unsqueeze(-1).expand(-1, -1, s))
selected_attention_mask = torch.gather(selected_attention_mask, 2, top_k_indices.unsqueeze(1).expand(-1, s, -1))
else:
selected_attention_mask = None
# Apply the block to the selected tokens
if use_cache:
selected_cache_position = torch.gather(cache_position, 1, top_k_indices) if cache_position is not None else None
block_output = self.block(
selected_tokens,
attention_mask=selected_attention_mask,
position_ids=selected_position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
cache_position=selected_cache_position,
**kwargs
)
if len(block_output) == 2:
processed_tokens, cache = block_output
else:
processed_tokens, cache = block_output[0], None
else:
processed_tokens = self.block(
selected_tokens,
attention_mask=selected_attention_mask,
position_ids=selected_position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
**kwargs
)[0]
# Apply weights to the processed tokens
processed_tokens = processed_tokens * torch.where(selected_mask, weights.unsqueeze(-1), torch.zeros_like(weights).unsqueeze(-1))
# Combine the processed tokens with the original tokens
output = torch.where(selected_mask.unsqueeze(-1), processed_tokens, x)
return (output, cache) if cache is not None else (output,)
总结
MOD的结构和MOE是天然的相似,整合起来的MODE可以试试fine-tune。实际使用现成的库虽然能够简单生成,但是其实支持的开源模型在SFT或者DPO训练中仍然存在问题,目前来看LLAMA系列的MOD是可以正常SFT的,且MOD增加了不少参数量。


















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









