







基于streamlit的AIGC项目前端展示
现在LLM技术发展迅速,很多人在学习的时候,都想展示效果,并且想部署在服务器上,但是其中有两个难点,一是比如Flask等的学习,二是租用云服务器,迁移环境,源文件等,比较耗时。
而像streamlit、gradio等python库,可以让初学者、数据科学家等快速部署自己的AI项目,展示效果,而且可以在公网访问,主要是免费。本人上面的都用过,真的是易学好用,10分钟完成一个小项目。
1.Streamlit 简介与入门
什么是 Streamlit?
Streamlit 是一个用于创建数据应用程序的Python库,可以帮助数据科学家、工程师和分析师轻松快速地构建交互式和可视化的数据界面。无需繁琐的前端代码,只需几行简单的Python代码,你就能将你的数据展现得美观而有效。
1.1 安装 Streamlit
在anaconda虚拟环境中,通过以下命令安装 Streamlit:
conda activate env #env是自己的一个虚拟环境 比如LLM_study
conda install streamlit
1.2 开发Streamlit应用程序
开发一个基本的 Streamlit 应用程序非常简单。
在VS里面新建一个 文件夹,然后新建一个python程序(如 app.py)

代码:
import streamlit as st
import numpy as np
import matplotlib.pyplot as plt
# 设置Streamlit的标题和样式
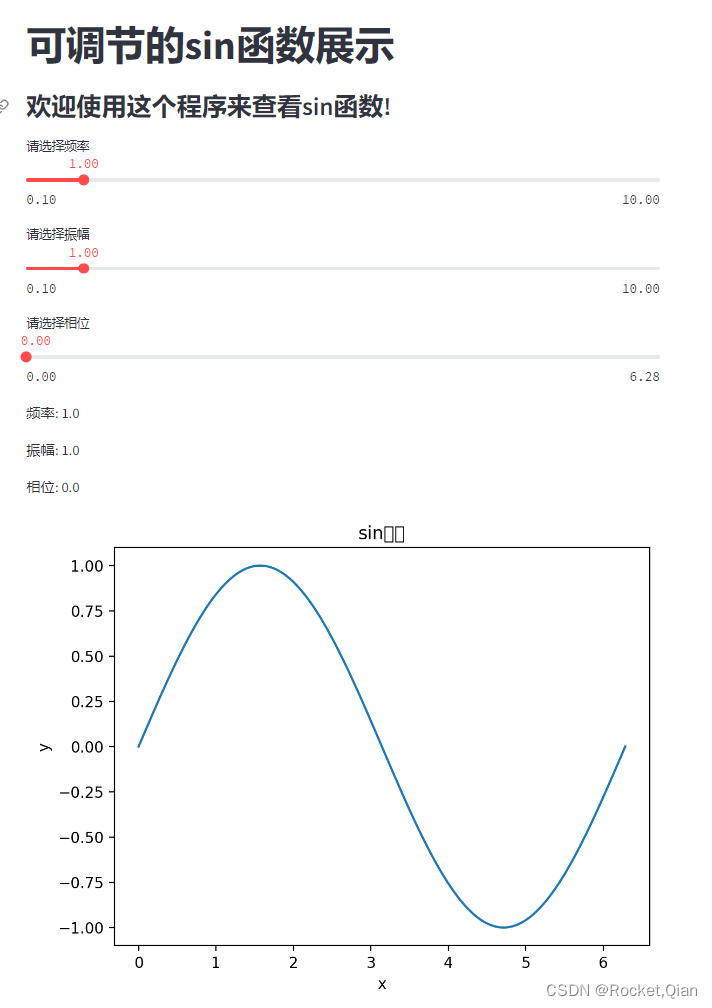
st.title("sin函数展示")
st.markdown("### 欢迎使用这个程序来查看sin函数!")
# 创建一个滑动条来调节频率
frequency = st.slider("请选择频率", min_value=0.1, max_value=10.0, step=0.1, value=1.0)
# 创建一个滑动条来调节振幅
amplitude = st.slider("请选择振幅", min_value=0.1, max_value=10.0, step=0.1, value=1.0)
# 创建一个滑动条来调节相位
phase = st.slider("请选择相位", min_value=0.0, max_value=2 * np.pi, step=0.1, value=0.0)
# 创建一个文本框来显示频率、振幅和相位
st.write(f"频率: {frequency}")
st.write(f"振幅: {amplitude}")
st.write(f"相位: {phase}")
# 创建一个画布来绘制sin函数
fig, ax = plt.subplots()
x = np.linspace(0, 2 * np.pi, 1000)
y = amplitude * np.sin(frequency * x + phase)
ax.plot(x, y)
ax.set_title("sin函数")
ax.set_xlabel("x")
ax.set_ylabel("y")
# 将画布显示在Streamlit应用中
st.pyplot(fig)
这个程序使用Streamlit库创建了一个简单的界面,用户可以通过滑动条来调节sin函数的频率、振幅和相位,然后程序会根据用户的选择来绘制相应的sin函数图像。
用户可以在Streamlit应用中运行这个程序,并使用浏览器打开它。
1.3 启动并运行
1.3.1 本地运行
在终端中运行:streamlit run app.py
这将启动一个本地服务器,自动跳转默认浏览器中打开应用程序。
前端展示
- 指定端口运行
默认情况下,Streamlit 应用程序将在本地的 8501 端口上运行。Local URL: http://localhost:8501
如果想更改端口,可以使用 --server.port 参数。比如,在 6898端口上运行:
streamlit run app.py --server.port 6898
1.3.2 部署
- 新建一个requirements.txt
pip freeze > requirements.txt - 将上面代码文件夹push到github上
git push - streamlit官网注册登录
- 点击new app,选择app的repo仓库,branch,要执行的main文件
- 填写域名app url
- 然后deploy
至此,大功告成!
可以继续学习streamlit,丰富应用的功能,展示更美观的前端。















 3149
3149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









