



环境准备
环境准备内容参考博主发布的上一节内容,Ubuntu虚拟机配置MindStudio开发环境
昇腾社区对算子开发介绍的也是很清楚,这一节先从算子设计开始。

设计算子
这里的算子开发从add算子开发开始,同时昇腾开源了许多的算子,可以在Ascend/Sample仓库获取
此外,在昇腾社区开发者首页也公开了相关的教程:Ascend C算子开发
https://gitee.com/ascend/samples
https://www.hiascend.com/developer/courses/detail/1763490197410181122
这里先克隆对应代码,然后执行对应的bash脚本,这里的bash脚本是一键运行脚本
git clone https://gitee.com/ascend/samples
cd samples/operator/ascendc/tutorials/HelloWorldSample
bash run.sh -v Ascend310B4

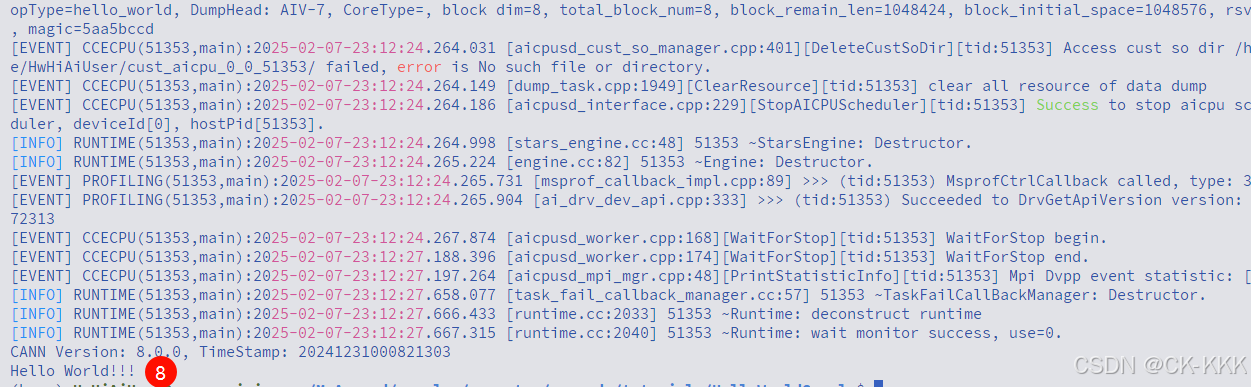
可以看到helloworld算子正常执行,成功运行,有了这份喜悦,一起来看看代码结构吧
HelloWorldSample/
│-- CMakeLists.txt //CMake 构建配置文件。
│-- README.md
│-- build/ //用于存放编译生成的文件的目录
│-- hello_world.cpp
│-- main.cpp
│-- out/ //执行脚本后得到的
│-- output_msg.txt //执行脚本后得到的
│-- run.sh //运行程序
这里代码核心为hello_world.cpp和main.cpp两个文件,这里对两个文件进行逐行解读。
hello_world.cpp,算子执行在device上的代码
/**
* @file hello_world.cpp
*
* Copyright (C) 2024. Huawei Technologies Co., Ltd. All rights reserved.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
*/
#include "kernel_operator.h"
// 核函数定义,这里hello_world是函数名称,其余都是标准格式
extern "C" __global__ __aicore__ void hello_world()
{
AscendC::printf("Hello World!!!\n");
}
// 核函数调用
void hello_world_do(uint32_t blockDim, void *stream)
{
//<<< >>>内核调用符
hello_world<<<blockDim, nullptr, stream>>>();
}
main.cpp,这里是执行在host上的代码
/**
* @file main.cpp
*
* Copyright (C) 2024. Huawei Technologies Co., Ltd. All rights reserved.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
*/
#include "acl/acl.h"
extern void hello_world_do(uint32_t coreDim, void *stream);
int32_t main(int argc, char const *argv[])
{
//AscendCL初始化
aclInit(nullptr);
//运行资源申请
int32_t deviceId = 0;
aclrtSetDevice(deviceId);
aclrtStream stream = nullptr;
aclrtCreateStream(&stream);
constexpr uint32_t blockDim = 8;
// Device数据传输到Host
// 调用了hello_world_do函数,这里函数是在hello_world.cpp定义了
hello_world_do(blockDim, stream);
// 阻塞执行队列,等待执行完毕
aclrtSynchronizeStream(stream);
//运行资源释放
aclrtDestroyStream(stream);
aclrtResetDevice(deviceId);
aclFinalize();
//AscendCL去初始化
return 0;
}


















 5649
5649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









