









目录
1原理介绍
主成分分析(Principal Component Analysis,PCA), 是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。PCA的思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征。这k维特征称为主成分,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。






2手写PCA代码
1、中心化(均值化);
2、求特征协方差矩阵;
3、求协方差的特征值和特征向量;
4、将特征值按照从大到小的顺序排序;
5、选择其中最大的k个,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵;
6、将样本点投影到选取的特征向量上。

import pandas as pd
import numpy as np
from scipy import linalg
#一般线性PCA函数
def pca(data_mat, topNfeat=1000000):
mean_vals = np.mean(data_mat, axis=0) ##按列(特征)求均值
mid_mat = data_mat - mean_vals ##中心化
cov_mat = np.cov(mid_mat, rowvar=False) ## 协方差矩阵
eig_vals, eig_vects = linalg.eig(np.mat(cov_mat))
eig_val_index = np.argsort(eig_vals)
eig_val_index = eig_val_index[:-(topNfeat + 1):-1]
eig_vects = eig_vects[:, eig_val_index]
low_dim_mat = np.dot(mid_mat, eig_vects)
# ret_mat = np.dot(low_dim_mat,eig_vects.T)
return low_dim_mat, eig_vals
if __name__=="__main__":
main()
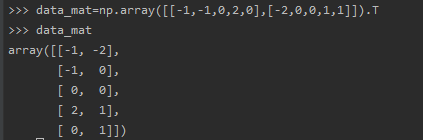


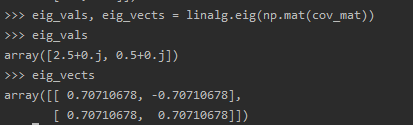

上面两个计算的差异性,主要是因为计算的协方差公式不一样,第一个案例计算用的是样本数,第二个用的是样本数-1。

3基于第三方模块的降维
- 降维前
from matplotlib import pyplot as plt
import pandas as pd
df = pd.read_csv('iris.data',header=0)
df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'label']
print(df)
def noPCA():
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(df[df['label']==lab]['sepal_len'],
df[df['label']==lab]['sepal_wid'],
label=lab,
c=col)
plt.xlabel('sepal_len')
plt.ylabel('sepal_wid')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
if __name__ == '__main__':
noPCA()
针对鸢尾花数据集选取两个维度在没有做特征降维的情况下,画出不同类型鸢尾花其散点图分布。可以看出绿色类别与红色类别很难区分开来。

- 降维后
from sklearn.decomposition import PCA
from matplotlib import pyplot as plt
import pandas as pd
df = pd.read_csv('iris.data',header=0)
df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'label']
lower_dim = PCA(n_components=4)
lower_dim.fit(df[['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid']].values)
Y=lower_dim.transform(df[['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid']].values)
print(lower_dim.explained_variance_ratio_) #主成分占比
[0.92395437 0.05343362 0.01737228 0.00523974]
print(lower_dim.explained_variance_) #各成分方差(或特征值)
[4.20438706 0.24314579 0.07905128 0.02384304]
print(lower_dim.components_) #(特征向量)
[[ 0.36263433 -0.08122848 0.85629752 0.35868209]
[ 0.6558202 0.73001455 -0.17703033 -0.07509244]
[-0.58115529 0.59619427 0.07265649 0.54911925]
[ 0.3172613 -0.32408808 -0.47972477 0.75111672]]
print(Y[:2,:])
[[-2.73363445 -0.16331092 -0.20387761 0.09962005]
[-2.90803676 -0.13076902 0.02432666 0.01932266]]
df1=pd.DataFrame({'Component_1':Y[:,0],"Component_2":Y[:,1],"label":df['label']})
def pca():
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(df1[df1['label']==lab]['Component_1'],
df1[df1['label']==lab]['Component_2'],
label=lab,
c=col)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(loc='lower center')
plt.tight_layout()
plt.show()
if __name__ == '__main__':
pca()
经过特征降维后,选取两个主成分之后,画出不同类型鸢尾花其散点图分布。可以看出绿色类别与红色类别能够很清晰区分开来。















 9380
9380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









