







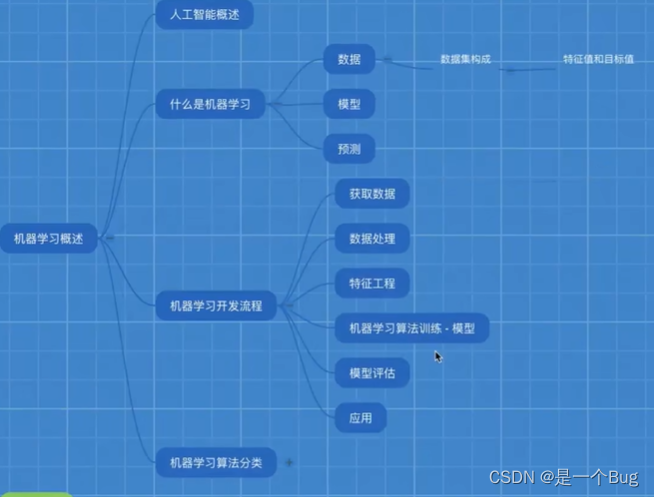
引子
当前交通大数据业务的需要,需要承担一部分算法工作(数据处理)
目标一:
- 学习机器学习基础:了解机器学习的定义、分类和基本原理。
- 掌握数据预处理:学习数据清洗、特征选择和特征工程的基本方法。
目标任务:使用机器学习算法对一个简单的数据集进行数据预处理。
目标二:
- 学习监督学习算法:重点学习K-邻近、决策树和朴素贝叶斯算法,并理解它们的应用场景和原理。
目标任务:使用监督学习算法对一个分类问题进行建模和训练。
目标三:
- 学习无监督学习算法:学习聚类和降维算法,如K-Means、PCA等。
目标任务:使用无监督学习算法对一个数据集进行聚类分析。
目标四:
- 学习深度学习基础:了解神经网络的基本结构、反向传播算法和激活函数等。
目标任务:使用深度学习算法构建一个简单的神经网络模型,并训练模型。
目标五:
- 学习深度学习框架:学习使用PyTorch或TensorFlow等深度学习框架。
目标任务:使用深度学习框架搭建一个更复杂的神经网络,并在一个数据集上进行训练和测试。
学习计划小贴士:
-
每天定期复习前几天的内容,巩固知识。
-
在学习过程中遇到问题及时查阅资料,或向论坛、社区寻求帮助。
-
尝试在学习过程中动手实践,通过编写代码来加深对算法和原理的理解。
-
学习过程中保持积极的学习态度和耐心,机器学习和深度学习是复杂的领域,需要持续学习和实践。
-
学习机器学习基础:了解机器学习的定义、分类和基本原理。
-
掌握数据预处理:学习数据清洗、特征选择和特征工程的基本方法。
准备一份草稿,后面更新
机器学习?
机器学习算法分类与数据预处理
机器学习是一门强大的领域,可以帮助我们从数据中获取有价值的见解和信息。在本篇博客中,我们将探讨机器学习算法的分类,并着重介绍数据预处理的重要性和方法。
算法分类
了解机器学习
机器学习是一种人工智能(AI)的子领域,它旨在使计算机系统能够从经验数据中自动学习和提高性能。这意味着机器学习系统可以通过数据而不是硬编码规则来进行学习和改进。
机器学习的分类
机器学习算法通常分为以下几类:
监督学习:在监督学习中,算法接收带有标签的训练数据,学习如何将输入映射到输出,然后用于进行预测。常见的监督学习任务包括分类和回归。
无监督学习:在无监督学习中,算法接收没有标签的训练数据,目标是发现数据中的结构和模式,如聚类和降维。
半监督学习:半监督学习是监督学习和无监督学习的结合,它使用带有标签和没有标签的数据来进行训练。
强化学习:强化学习涉及智能体通过与环境的互动来学习行动策略,以最大化累积奖励。
数据预处理
数据预处理是机器学习中至关重要的一步,它有助于提高模型的性能和准确性。数据预处理包括以下主要任务:
数据清洗:处理缺失值、异常值和重复值,确保数据质量。
特征选择:选择最重要的特征以减少维度和降低模型复杂性。
特征工程:创建新特征或转换现有特征,以提取更多信息并改善模型性能。
开发流程
下面,我们将按照以下流程来进行机器学习模型的开发:
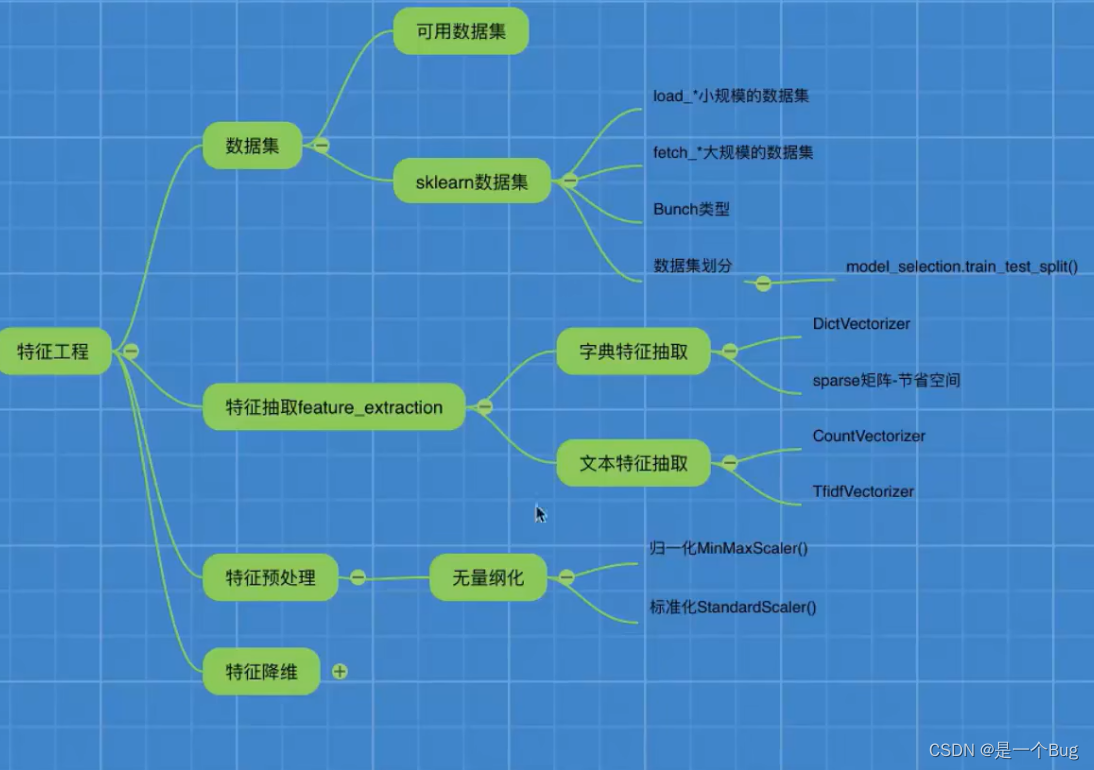
特征工程
在特征工程阶段,我们将处理和转换数据中的特征,以便将其用于机器学习模型的训练和预测。
数据集
字典特征抽取
字典特征抽取是将包含类别信息的特征转换为数值形式的一种方法。它将每个类别映射到一个唯一的数值,以便算法能够理解和处理。
文本特征抽取
文本特征抽取是将文本数据转换为数值特征的过程。常见的文本特征抽取方法包括词袋模型(Bag of Words)和词嵌入(Word Embeddings)。
数据预处理
在数据预处理阶段,我们将对数据进行标准化和归一化,以确保模型的稳定性和性能。
归一化
归一化是将数据缩放到固定范围的过程,通常在0到1之间。这有助于处理具有不同尺度的特征。
标准化
标准化是将数据转换为均值为0、方差为1的分布。它有助于处理具有不同单位的特征。
特征降维
特征降维是减少特征维度的过程,以降低计算复杂性并提高模型性能。常见的特征降维方法包括主成分分析(PCA)等。
特征工程和数据预处理是构建高性能机器学习模型的关键步骤。它们可以帮助我们更好地理解数据,准备数据以供模型使用,并改善模型的准确性。在未来的博客中,我们将深入研究这些步骤,并应用它们到实际的数据集中。
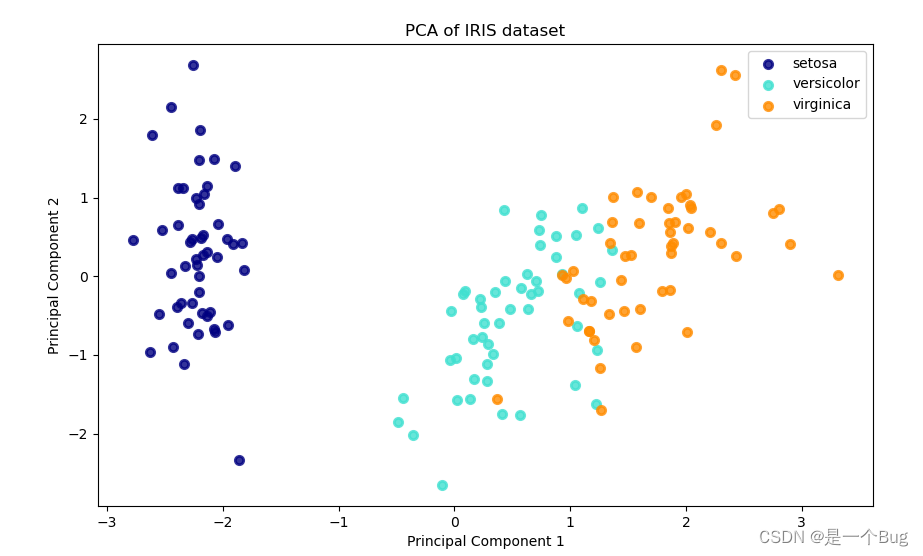
算法实现及其可视化
这段代码使用了经典的鸢尾花数据集 (load_iris) 作为示例数据集。它首先进行了数据预处理,包括数据清洗、标准化和特征降维(使用PCA)。然后,通过可视化工具 Matplotlib,将降维后的数据以不同颜色和标签进行可视化展示。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 1. 加载示例数据集
iris = load_iris()
data = iris.data
target = iris.target
# 2. 数据预处理
# 2.1 数据清洗 - 无缺失值处理步骤,因为示例数据集是干净的
# 2.2 特征选择 - 使用全部特征
# 2.3 标准化 - 将特征缩放到均值为0,方差为1
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# 3. 特征降维 - 使用主成分分析 (PCA) 进行降维
pca = PCA(n_components=2) # 降维为2维
data_pca = pca.fit_transform(data_scaled)
# 4. 可视化
plt.figure(figsize=(10, 6))
colors = ['navy', 'turquoise', 'darkorange']
lw = 2
for color, i, target_name in zip(colors, [0, 1, 2], iris.target_names):
plt.scatter(data_pca[target == i, 0], data_pca[target == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('PCA of IRIS dataset')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()














 1904
1904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









