






数据集准备
使用开源项目:https://github.com/hukenovs/hagrid
#cd 到工程目录下
git clone https://github.com/hukenovs/hagrid.git
mkdir gestrue_data
cd gestrue_data
#下载轻量数据集
wget https://n-ws-620xz-pd11.s3pd11.sbercloud.ru/b-ws-620xz-pd11-jux/hagrid/hagrid_dataset_new_554800/hagrid_dataset_512.zip
#解压hagrid_dataset_512.zip
#下载annotations
wget https://n-ws-620xz-pd11.s3pd11.sbercloud.ru/b-ws-620xz-pd11-jux/hagrid/hagrid_dataset_new_554800/annotations.zip
上述步骤中,首先需要获取数据集项目代码,后续需要转换数据集格式。
原数据集723GB,这里使用轻量版的26.4 GB。
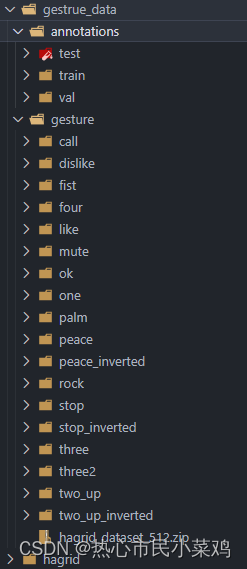
完成后目录结构:
接下来需要配置环境用于处理数据
也可以和yolov7的环境装在一起,没有发现冲突的问题。
cd hagrid
# Create virtual env by conda or venv
conda create -n gestures python=3.11 -y
conda activate gestures
# Install requirements
pip install -r requirements.txt
数据集格式转换:
-
准备配置文件
cp ./converters/converter_config.yaml ./配置文件
converter_config.yaml内容如下,替换自己的绝对路径:dataset: dataset_annotations: /<绝对路径>/gestrue_data/annotations # Path to annotations dataset_folder: /<绝对路径>/gestrue_data/gesture # Path to images phases: [train, test, val] #names of annotation directories targets: - call - dislike - fist - four - like - mute - ok - one - palm - peace - rock - stop - stop_inverted - three - two_up - two_up_inverted - three2 - peace_inverted - no_gesture -
数据转换
python -m converters.hagrid_to_yolo --path_to_config ./converter_config.yaml
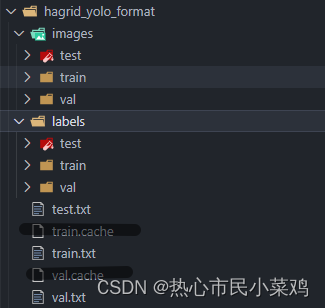
转换完成后数据集就在hagrid_yolo_format中,转换完有六个文件夹。
注意:这里需要整理一下,不然yolo没法识别到标签,创建两个文件夹images和labels分别存放数据和标签
整理完的文件如下:
模型训练
yolov7:https://github.com/WongKinYiu/yolov7
-
配置环境
同样需要配置环境,有很多yolov7和cuda的配置教程,本文就不在赘述了。
可以使用以下指令看看驱动和cuda配置的如何:
nvidia-smi nvcc -V -
准备配置文件
cd yolov7 cp ./data/coco.yaml ./修改
coco.yamltrain: /<绝对路径>/hagrid/hagrid_yolo_format/train.txt val: /<绝对路径>/hagrid/hagrid_yolo_format/val.txt test: /<绝对路径>/hagrid/hagrid_yolo_format/test.txt # number of classes nc: 19 # class names names: ['call','dislike','fist','four','like','mute','ok','one','palm','peace','rock','stop','stop_inverted','three','two_up','two_up_inverted','three2','peace_inverted','no_gesture'] -
训练
python train.py --workers 8 --device 0 --batch-size 32 --data ./coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml如果显卡没跑起来,添加环境变量:export CUDA_VISIBLE_DEVICES=0
训练结果:

单块4090训练了差不多10个小时,P,R比较高就停了。
./run/train/<最后一个文件夹>/weights 中的 best.pt就是训练好的模型
模型推理
使用以下指令就可以推理了,source 可以选择单张照片也可以选择文件夹,如果要使用摄像头视频流就是用0
python detect.py --weights best.pt --conf 0.25 --img-size 640 --source ../hagrid/hagrid_yolo_format/images/test/rock/
如果使用摄像头视频流,可能看不到实时画面,会提示环境不支持。
推理结束后会在./run/detect中看到推理后的视频后面会有基于原推理代码裁剪了一份专门用于摄像头的推理代码,用对实时检测视频流并显示画面。
视频流推理
推理代码:https://download.csdn.net/download/weixin_44135213/89290886
python video.py --weights best.pt --conf 0.25 --img_size 640 --source 0
















 2818
2818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









