






使用tesla t4 运行scene graph generation benchmark小记
- 前言:
- scene graph generation benchmark环境配置流程(两张tesla t4 ,cuda10.4 ,python3.8,pytorch1.4.0)
- 全文翻译github文章
- 概述
- Installation
- Dataset
- Metrics and Results (IMPORTANT)
- Pretrained Models
- Alternate links
- Faster R-CNN pre-training
- Scene Graph Generation as RoI_Head
- Perform training on Scene Graph Generation
- 我在运行时对项目中的内容做的一些小修改
前言:
因为笔者现在在学习scene graph generation,而现有的scene graph generation模型一版都是基于kaihua大佬的scene graph generation benchmark而来。所以我们需要先复现且吃透scene graph generation benchmark的代码,才能继续有所发展KaihuaTang Scene-Graph-Benchmark.pytorch Public
笔者在安装scene graph generation benchmark的代码的时候,遇到了非常多的问题,比如配置环境问题,路径问题,所以笔者在这里整体整理了一下scene graph generation的安装配置流程以及代码解析。
scene graph generation benchmark环境配置流程(两张tesla t4 ,cuda10.4 ,python3.8,pytorch1.4.0)
环境配置
(注意,本次所有安装的流程都基于autodl网址,因此会涉及到autodl学术加速的问题。)
# 设置开启学术加速,开启了以后autodl运行git clone或git reset才有效,否则会因为网络问题而失败
source /etc/network_turbo
#进入autodl-tmp文件夹
cd autodl-tmp
# conda创建环境。,
conda create -n scene_graph_benchmark python=3.8
conda init bash && source /root/.bashrc
conda activate scene_graph_benchmark
一个小tips,就是我们配环境的时候,可以先安装cuda,cudnn和pytorch,确定能成功运行了再安装其他包,因为我往往会出现安装的pytorch无法运行的情况。
安装cuda和cudnn
#conda清除添加源,恢复默认源(不恢复默认源的话,conda search显示出来的是源里的不全的cuda和cudnn,显示不出conda-forge里的cuda和cudnn)
conda config --remove-key channels
#添加一些清华源(有时候清华源崩了,可以换阿里源,阿里源崩了,可以换中科大源。国内安环境遇到问题,比如查找不到包的问题,很多都是网络的问题)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
#(不换源的话也可以运行下面两条命令:
#conda search cudatoolkit -c conda-forge
#conda search cudnn -c conda-forge
#)
conda search cudatoolkit
conda search cudnn
#根据显示出的包,我们安装cudatoolkit=10.1.243和cudnn=7.6.5
conda install cudatoolkit=10.1.243
conda install cudnn=7.6.5
安装pytorch
#因为用conda命令来安装pytorch的时候会提示找不到torchvision的包(实际是服务器连网络的问题),所以我们用相同作用的pip来安装。
pip install torch==1.4.0 torchvision==0.5.0
检查是否安装成功:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
# 打印当前可见可用的GPU数目
print(torch.cuda.device_count())
# 获取GPU名字
print(torch.cuda.get_device_name())
之后继续保持学术加速,安装其他的包
conda install ipython
conda install scipy
conda install h5py
pip install ninja yacs cython matplotlib tqdm opencv-python overrides
export INSTALL_DIR=$PWD
cd $INSTALL_DIR
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
python setup.py build_ext install
cd $INSTALL_DIR
git clone https://github.com/NVIDIA/apex.git
cd apex
git reset --hard 3fe10b5597ba14a748ebb271a6ab97c09c5701ac
python setup.py install --cuda_ext --cpp_ext
cd $INSTALL_DIR
git clone https://github.com/KaihuaTang/Scene-Graph-Benchmark.pytorch.git
cd Scene-Graph-Benchmark.pytorch
python setup.py build develop
unset INSTALL_DIR
#取消学术加速
之后取消学术加速
现在,我解压后的文件是如图所示的。
下载并上传数据集
将Visual genome的image1 和image2都下载下来,所有图片解压后放到datasets/vg/VG_100K里,之后下载作者提供的VG-SGG-with-attri.h5 ,这个文件放在datasets/vg下,最终路径是datasets/vg/VG-SGG-with-attri.h5。 同时一定要注意啊,作者在dataset.md里提到的文件maskrcnn_benchmark/config/paths_catalog.py,这里面保存了很重要的信息,也就是maskrcnn_benchmark需要用到的信息(即读取的数据路径。我们需要对读取路径做一下修改)
我们现在打开一下paths_catalog.py文件看一下。
这份文件放在maskrcnn_benchmark里的config文件夹下。
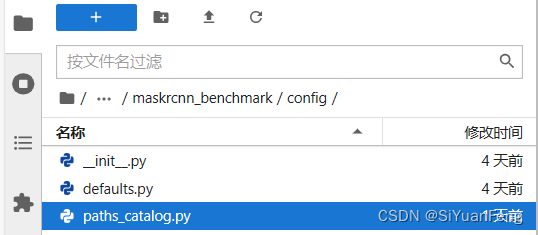
里面一开始的DATA_DIR 是"/media/rafi/Samsung_T/_DATASETS"
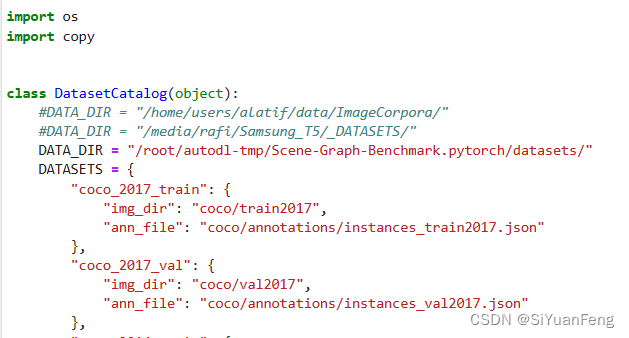
在DATA_DIR之后,还会有其他的路径,比如coco_2017_train,coco_2017val这些。以及这些数据集后续的img_dir。
我举个例子解释一下这些路径是什么意思

比如我们要运行VG_stanford_filtered_with_attribute数据集,那么系统会去路径:/media/rafi/Samsung_T/_DATASETS/vg/VG_100K中寻找图片。 去/media/rafi/Samsung_T/_DATASETS/vg/VG_100Kvg/VG-SGG-dicts-with-attri.json 寻找json文件。
但是显然,我们的数据文件都放在了/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/datasets内(里面有下载的vg文件和vg数据),所以我们修改一下原来的数据路径,否则读取数据会出错:
将原来的路径修改成了:/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/datasets/
全文翻译github文章
注意要结合这个文件的目录看,才能详略得当的掌握知识

概述
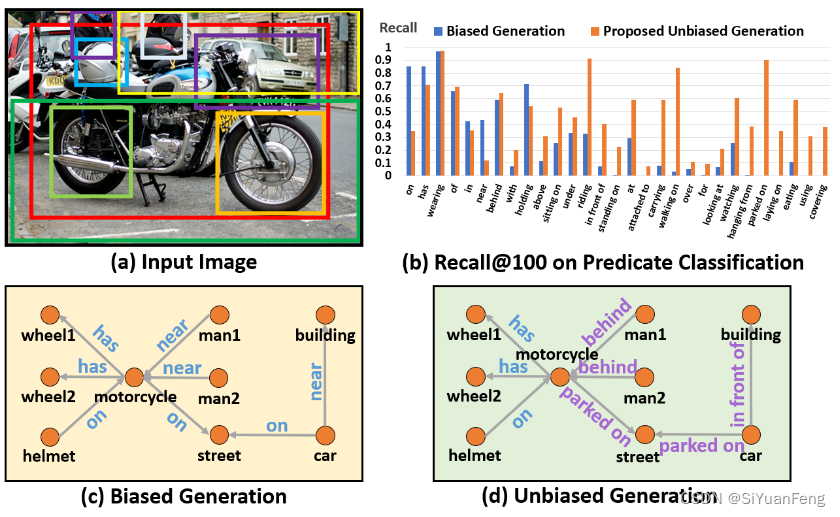
该项目旨在构建一个新的场景图生成(SGG)代码库,也是论文《Unbiased Scene Graph Generation from Biased Training》的Pytorch实现。 之前广泛采用的 SGG 代码库neural-motifs与最近开发的 Faster/Mask R-CNN 是分离的。 因此,我决定在著名的 maskrcnn-benchmark 项目之上构建一个场景图基准测试,并将关系预测定义为附加的roi_head。 顺便说一句,由于其优雅的框架,这个代码库比以前的神经模式框架更适合新手,并且更容易为您自己的项目阅读/修改(至少我希望如此)。 遗憾的是,我做这个项目的时候, detectorron2 还没有发布,但是我想我们可以考虑 maskrcnn-benchmark 作为一个更稳定、bug 更少的版本,哈哈哈哈。 我还介绍了SGG中使用的所有新旧指标,并澄清了METRICS.md中SGG指标的两个常见误解,这导致了一些论文中结果异常。
受益于 maskrcnn-benchmark 中最新的 Faster R-CNN,该代码库通过使用两个 1080ti GPU 重新实现的 VCTree 在 SGCls 和 SGGen 上实现了新的最先进的 Recall@k(截至 2020 年 2 月 16 日)batch_size = 8:

请注意,VCTree 的所有结果都应该比我们在《Biased Training from Unbiased Scene Graph Generation from Biased Training》中报告的结果更好,因为我们在发布后优化了树构建网络。
来自“Biased Training 的无偏场景图生成”中的无偏 SGG 插图
Installation
检查 INSTALL.md 以获取安装说明。
Dataset
检查 DATASET.md 以获取数据集预处理的说明。
Metrics and Results (IMPORTANT)
METRICS.md 中给出了我们工具包中指标的说明和报告的结果。
Pretrained Models
由于我们在论文《来自偏置训练的无偏置场景图生成》中测试了许多 SGG 模型,因此我不会在这里上传所有预训练的 SGG 模型。 不过,你可以下载我们在论文中使用的pretrained Faster R-CNN,这是整个训练过程中最耗时的步骤(花了 4 个 2080ti GPU)。 对于SGG模型,您可以按照其余说明来训练自己的模型,训练每个SGG模型只需要2个GPU。 结果应该非常接近 METRICS.md 中给出的报告结果
下载Faster R-CNN Model后,请将所有文件解压到目录/home/username/checkpoints/pretrained_faster_rcnn。 要训练您自己的 Faster R-CNN 模型,请按照下一节进行操作。
上述预训练的 Faster R-CNN 模型在 VG 训练/验证/测试集上分别获得了 38.52/26.35/28.14 mAp。
Alternate links
由于OneDrive链接在中国大陆可能会被破坏,我们还为所有使用百度网盘的预训练模型和数据集注释提供了以下备用链接:
链接:https://pan.baidu.com/s/1oyPQBDHXMQ5Tsl0jy5OzgA 提取码:1234
Faster R-CNN pre-training
以下命令可用于训练您自己的 Faster R-CNN 模型:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --master_port 10001 --nproc_per_node=4 tools/detector_pretrain_net.py --config-file "configs/e2e_relation_detector_X_101_32_8_FPN_1x.yaml" SOLVER.IMS_PER_BATCH 8 TEST.IMS_PER_BATCH 4 DTYPE "float16" SOLVER.MAX_ITER 50000 SOLVER.STEPS "(30000, 45000)" SOLVER.VAL_PERIOD 2000 SOLVER.CHECKPOINT_PERIOD 2000 MODEL.RELATION_ON False OUTPUT_DIR /home/kaihua/checkpoints/pretrained_faster_rcnn SOLVER.PRE_VAL False
(PS:我们拆开来解析一下这个命令)
CUDA_VISIBLE_DEVICES=0,1,2,3
python -m torch.distributed.launch
--master_port 10001
--nproc_per_node=4
tools/detector_pretrain_net.py
--config-file "configs/e2e_relation_detector_X_101_32_8_FPN_1x.yaml"
SOLVER.IMS_PER_BATCH 8
TEST.IMS_PER_BATCH 4
DTYPE "float16"
SOLVER.MAX_ITER 50000
SOLVER.STEPS "(30000, 45000)"
SOLVER.VAL_PERIOD 2000
SOLVER.CHECKPOINT_PERIOD 2000
MODEL.RELATION_ON False
OUTPUT_DIR /home/kaihua/checkpoints/pretrained_faster_rcnn
SOLVER.PRE_VAL False
其中 CUDA_VISIBLE_DEVICES 和 --nproc_per_node 表示 GPU 的 id 和您使用的 GPU 的数量, --config-file 表示我们使用的配置,您可以在其中更改其他参数。 SOLVER.IMS_PER_BATCH和TEST.IMS_PER_BATCH分别是训练和测试批量大小,DTYPE“float16”启用APEX支持的自动混合精度,SOLVER.MAX_ITER是最大迭代,SOLVER.STEPS是我们衰减学习率的步骤,SOLVER .VAL_PERIOD和SOLVER.CHECKPOINT_PERIOD是进行val和保存检查点的周期,MODEL.RELATION_ON表示是否打开关系头(因为这只是Faster R-CNN的预训练阶段,所以我们关闭关系头),OUTPUT_DIR 是保存检查点和日志的输出目录(考虑/home/username/checkpoints/pretrained_faster_rcnn),SOLVER.PRE_VAL表示我们是否在训练前进行验证。
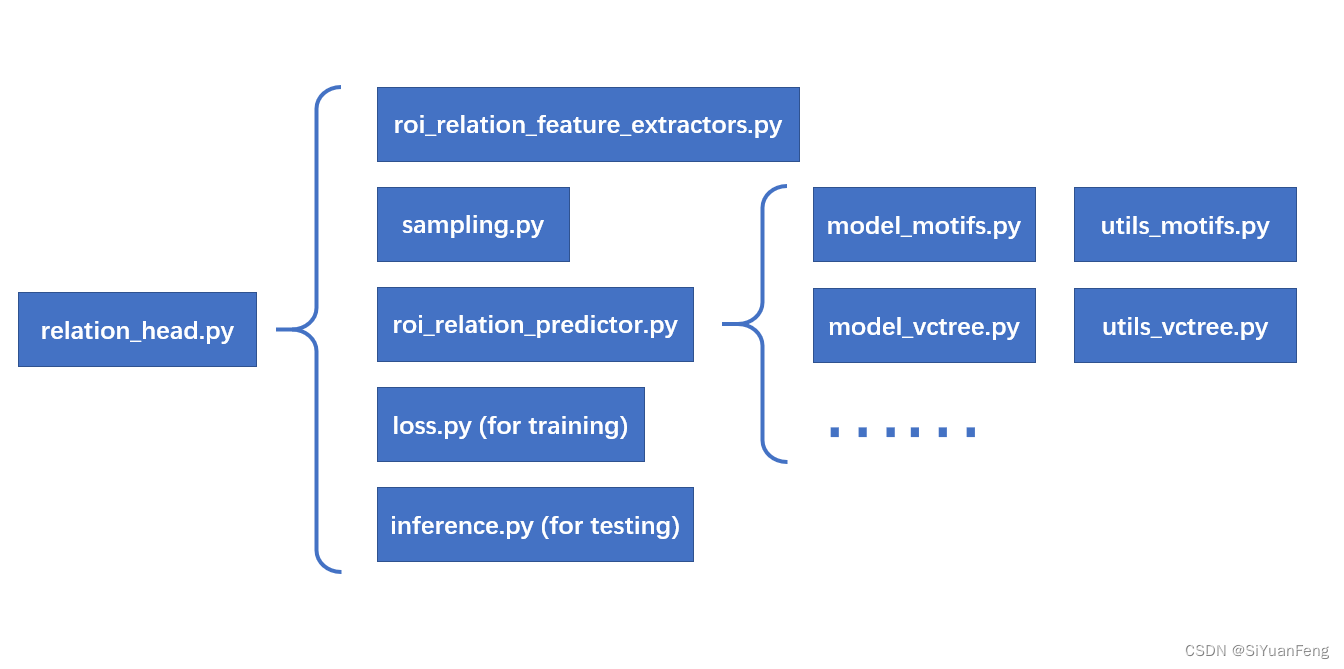
Scene Graph Generation as RoI_Head
为了标准化 SGG,我将场景图生成定义为 RoI_Head。 参考box_head等其他roi_heads的设计,我将大部分SGG代码放在maskrcnn_benchmark/modeling/roi_heads/relation_head下,它们的调用顺序如下:
Perform training on Scene Graph Generation
共有三种标准协议:(1)谓词分类(PredCls):将ground truth bounding boxes 和labels作为输入,(2)场景图分类(SGCls):使用没有label的ground truth bounding boxes ,(3)场景图检测( SGDet):从头开始检测 SG。 我们使用两个开关 MODEL.ROI_RELATION_HEAD.USE_GT_BOX 和 MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL 来选择协议。
对于谓词分类(Predicate Classification)(PredCls),我们需要设置:
MODEL.ROI_RELATION_HEAD.USE_GT_BOX True
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL True
对于场景图分类 Scene Graph Classification (SGCls):
MODEL.ROI_RELATION_HEAD.USE_GT_BOX True
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False
对于场景图检测Scene Graph Detection (SGDet):
MODEL.ROI_RELATION_HEAD.USE_GT_BOX False
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False
预定义模型Predefined Models
我们在文件 roi_heads/relation_head/roi_relation_predictors.py 中将各种 SGG 模型抽象为不同的(关系头预测器)relation-head predictors,它们独立于 Faster R-CNN 主干和关系头特征提取器(relation-head predictors)。 要选择我们的预定义模型,您可以使用 MODEL.ROI_RELATION_HEAD.PREDICTOR。
对于Neural-MOTIFS 模型:
MODEL.ROI_RELATION_HEAD.PREDICTOR MotifPredictor
对于(Iterative-Message-Passing(IMP))迭代消息传递(IMP)模型(请注意,SGCls 中的 SOLVER.BASE_LR 应更改为 0.001,否则模型不会收敛):
MODEL.ROI_RELATION_HEAD.PREDICTOR IMPPredictor
对于VC-TREE 模型
MODEL.ROI_RELATION_HEAD.PREDICTOR VCTreePredictor
对于我们预定义的 Transformer 模型(请注意,Transformer 模型需要将 SOLVER.BASE_LR 更改为 0.001,SOLVER.SCHEDULE.TYPE 更改为 WarmupMultiStepLR,SOLVER.MAX_ITER 更改为 16000,SOLVER.IMS_PER_BATCH 更改为 16,SOLVER.STEPS 更改为 (10000, 16000)。) ,由史佳欣提供:
MODEL.ROI_RELATION_HEAD.PREDICTOR TransformerPredictor
默认设置位于 configs/e2e_relation_X_101_32_8_FPN_1x.yaml 和 maskrcnn_benchmark/config/defaults.py 下。 优先级是command > yaml > defaults.py
(PS:注意这里的默认位置,我们修改文件时都去这些路径里去修改)
定制你自己的模型 Customize Your Own Model
如果你想定制自己的模型,可以参考 maskrcnn-benchmark/modeling/roi_heads/relation_head/model_XXXXX.py 和 maskrcnn-benchmark/modeling/roi_heads/relation_head/utils_XXXXX.py 。 您还需要在 maskrcnn-benchmark/modeling/roi_heads/relation_head/roi_relation_predictors.py 中添加相应的 nn.Module。 有时您可能还需要通过 maskrcnn-benchmark/modeling/roi_heads/relation_head/relation_head.py 更改模块的输入和输出。
提出的基于有偏差训练的无偏差场景图生成的因果 TDE (The proposed Causal TDE on Unbiased Scene Graph Generation from Biased Training)
对于无偏因果 TDE,您还需要了解一些附加参数。 MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE 用于在推理(测试)时选择因果效应分析类型,其中“none”为原始似然,“TDE”为总直接效应,“NIE”为自然间接效应,“TE”为 总效果。 MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE 有两个选择“sum”或“gate”。 由于无偏因果 TDE 分析与模型无关,因此我们支持 Neural-MOTIFS、VCTree 和 VTransE。 MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER 用于选择这些模型进行无偏因果分析,有三种选择:motifs、vctree、vtranse。
请注意,在训练过程中,我们始终将 MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE 设置为“none”,因为因果效应分析仅适用于推理/测试阶段。
训练命令示例(Examples of the Training Command)
Training Example 1 : (PreCls, Motif Model)
因为我创建的glove路径如图所示:/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove
创建的checkpoints路径(MODEL.PRETRAINED_DETECTOR_CKPT):/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/pretrained_faster_rcnn/model_final.pth
第三条路径:/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --master_port 10025 --nproc_per_node=2 tools/relation_train_net.py --config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" MODEL.ROI_RELATION_HEAD.USE_GT_BOX True MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL True MODEL.ROI_RELATION_HEAD.PREDICTOR MotifPredictor SOLVER.IMS_PER_BATCH 12 TEST.IMS_PER_BATCH 2 DTYPE "float16" SOLVER.MAX_ITER 50000 SOLVER.VAL_PERIOD 2000 SOLVER.CHECKPOINT_PERIOD 2000 GLOVE_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove MODEL.PRETRAINED_DETECTOR_CKPT /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/pretrained_faster_rcnn/model_final.pth OUTPUT_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp
把PreCLs,Motif Model的训练命令拆解一下看(记得提前把路径修改好)
CUDA_VISIBLE_DEVICES=0,1 #这个命令用于指定在哪些GPU设备上运行训练。在这里,它指定了使用GPU 0和1。
python -m torch.distributed.launch #这是启动训练的Python命令,它使用了PyTorch分布式训练的模块来运行训练。
--master_port 10025 #指定了用于分布式训练的主机端口号,它在分布式训练中用于通信。
--nproc_per_node=2 #指定每个节点(可能是一个机器上的一个GPU设备)运行的进程数。在这里,每个节点运行2个进程。
tools/relation_train_net.py #这是要运行的Python脚本文件,该脚本用于训练深度学习模型。它似乎是一个与关系检测或场景图推理相关的模型训练脚本。
--config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" #这是要运行的Python脚本文件,该脚本用于训练深度学习模型。它似乎是一个与关系检测或场景图推理相关的模型训练脚本。
MODEL.ROI_RELATION_HEAD.USE_GT_BOX True #设置一个模型训练的参数,指示模型在训练中使用边界框数据。
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL True #设置另一个模型训练的参数,可能指示模型在训练中使用真实的对象标签数据。
MODEL.ROI_RELATION_HEAD.PREDICTOR MotifPredictor #设置模型中关于关系预测的部分,使用了名为"MotifPredictor"的预测器。
SOLVER.IMS_PER_BATCH 12 #设置每个训练批次中包含的图像数量为12。
TEST.IMS_PER_BATCH 2 #设置每个测试批次中包含的图像数量为2。
DTYPE "float16" #指定了数据类型,可能将数据类型设置为16位浮点数以节省内存。
SOLVER.MAX_ITER 50000 #设置训练的最大迭代次数为50000。
SOLVER.VAL_PERIOD 2000 #指定了多少次迭代后进行一次验证(测试)操作,这里设置为每2000次迭代进行一次。
SOLVER.CHECKPOINT_PERIOD 2000 #指定了多少次迭代后进行一次验证(测试)操作,这里设置为每2000次迭代进行一次。
GLOVE_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove #指定了GloVe词嵌入文件的路径,这可能是用于自然语言处理任务的词向量。
MODEL.PRETRAINED_DETECTOR_CKPT /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/pretrained_faster_rcnn/model_final.pth #指定了一个已经预训练的检测器模型的检查点文件的路径,这个检查点文件可能会被用于初始化模型的一部分。
OUTPUT_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp #指定了一个已经预训练的检测器模型的检查点文件的路径,这个检查点文件可能会被用于初始化模型的一部分。
我把三条路径都改成自己的路径了。
其中 GLOVE_DIR 是用于保存手套初始化的目录,MODEL.PRETRAINED_DETECTOR_CKPT 是要加载的预训练 Faster R-CNN 模型,OUTPUT_DIR 是用于保存检查点和日志的输出目录。 由于我们使用 WarmupReduceLROnPlateau 作为 SGG 的学习调度程序,因此不再需要 SOLVER.STEPS。
Training Example 2 : (SGCls, Causal, TDE, SUM Fusion, MOTIFS Model)
我们同样更改一下代码的三条路径,把路径都改成自己的。(之前试了测试代码二,发现用和测试代码一相同的路径跑不出来,所以一定要好好回到原英文帖子,好好对比一下这两条训练代码的路径,)
因为我创建的glove路径如图所示:/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove
创建的checkpoints路径(MODEL.PRETRAINED_DETECTOR_CKPT):/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/pretrained_faster_rcnn/model_final.pth
第三条路径:/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --master_port 10026 --nproc_per_node=2 tools/relation_train_net.py --config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" MODEL.ROI_RELATION_HEAD.USE_GT_BOX True MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False MODEL.ROI_RELATION_HEAD.PREDICTOR CausalAnalysisPredictor MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE none MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE sum MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER motifs SOLVER.IMS_PER_BATCH 12 TEST.IMS_PER_BATCH 2 DTYPE "float16" SOLVER.MAX_ITER 50000 SOLVER.VAL_PERIOD 2000 SOLVER.CHECKPOINT_PERIOD 2000 GLOVE_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove MODEL.PRETRAINED_DETECTOR_CKPT /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/pretrained_faster_rcnn/model_final.pth OUTPUT_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp
TDE
CUDA_VISIBLE_DEVICES=0,1
python -m torch.distributed.launch
--master_port 10026
--nproc_per_node=2
tools/relation_train_net.py
--config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml"
MODEL.ROI_RELATION_HEAD.USE_GT_BOX True
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False
MODEL.ROI_RELATION_HEAD.PREDICTOR CausalAnalysisPredictor
MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE none
MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE sum
MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER motifs
SOLVER.IMS_PER_BATCH 12
TEST.IMS_PER_BATCH 2
DTYPE "float16"
SOLVER.MAX_ITER 50000
SOLVER.VAL_PERIOD 2000
SOLVER.CHECKPOINT_PERIOD 2000
GLOVE_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove
MODEL.PRETRAINED_DETECTOR_CKPT /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/pretrained_faster_rcnn/model_final.pth
OUTPUT_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp
Evaluation
Examples of the Test Command
Test Example 1 : (PreCls, Motif Model)
继续更改:
因为我创建的glove路径如图所示:/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove
创建的checkpoints路径(MODEL.PRETRAINED_DETECTOR_CKPT):/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/pretrained_faster_rcnn/model_final.pth
第三条路径:/root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --master_port 10027 --nproc_per_node=1 tools/relation_test_net.py --config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" MODEL.ROI_RELATION_HEAD.USE_GT_BOX True MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL True MODEL.ROI_RELATION_HEAD.PREDICTOR MotifPredictor TEST.IMS_PER_BATCH 1 DTYPE "float16" GLOVE_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove MODEL.PRETRAINED_DETECTOR_CKPT /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp OUTPUT_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp
拆解一下这条命令:
CUDA_VISIBLE_DEVICES=0 #这个命令用于指定在哪个GPU设备上运行测试。在这里,它指定了使用GPU 0。
python -m torch.distributed.launch #这个命令用于指定在哪个GPU设备上运行测试。在这里,它指定了使用GPU 0。
--master_port 10027 #指定了用于分布式测试的主机端口号,用于进程间通信。
--nproc_per_node=1 #指定每个节点(可能是一个机器上的一个GPU设备)运行的进程数。在这里,每个节点运行1个进程,表明这是单个GPU上的测试任务
tools/relation_test_net.py #这是要运行的Python脚本文件,用于执行模型测试(推理)操作。它可能是与关系检测或场景图推理相关的测试脚本。
--config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" #指定了配置文件的路径,该配置文件包含了模型测试的各种参数设置和超参数。
MODEL.ROI_RELATION_HEAD.USE_GT_BOX True #设置一个模型测试的参数,可能指示模型在测试中使用真实的边界框数据。
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL True #设置另一个模型测试的参数,可能指示模型在测试中使用真实的对象标签数据。
MODEL.ROI_RELATION_HEAD.PREDICTOR MotifPredictor #设置模型中关于关系预测的部分,使用了名为"MotifPredictor"的预测器。
TEST.IMS_PER_BATCH 1 #设置每个测试批次中包含的图像数量为1,这意味着每次测试一个图像。
DTYPE "float16" #指定了数据类型,可能将数据类型设置为16位浮点数以节省内存,与训练代码中的设置相同。
GLOVE_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/glove #指定了GloVe词嵌入文件的路径,这可能是用于自然语言处理任务的词向量。
MODEL.PRETRAINED_DETECTOR_CKPT /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp #指定了用于初始化模型的检测器部分的检查点文件的路径,这个检查点文件可能来自之前的训练过程。
OUTPUT_DIR /root/autodl-tmp/Scene-Graph-Benchmark.pytorch/checkpoints/motif-precls-exmp #指定了模型测试结果的输出目录路径,测试结果可能包括模型输出、日志等。
Test Example 2 : (SGCls, Causal, TDE, SUM Fusion, MOTIFS Model)
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --master_port 10028 --nproc_per_node=1 tools/relation_test_net.py --config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" MODEL.ROI_RELATION_HEAD.USE_GT_BOX True MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False MODEL.ROI_RELATION_HEAD.PREDICTOR CausalAnalysisPredictor MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE TDE MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE sum MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER motifs TEST.IMS_PER_BATCH 1 DTYPE "float16" GLOVE_DIR /home/fengsiyuan/Scene-Graph-Benchmark.pytorch/glove MODEL.PRETRAINED_DETECTOR_CKPT /home/fengsiyuan/Scene-Graph-Benchmark.pytorch/checkpoints/causal-motifs-sgcls-exmp OUTPUT_DIR /home/fengsiyuan/Scene-Graph-Benchmark.pytorch/checkpoints/causal-motifs-sgcls-exmp
拆解一下命令:
CUDA_VISIBLE_DEVICES=0
python -m torch.distributed.launch
--master_port 10028
--nproc_per_node=1
tools/relation_test_net.py
--config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" MODEL.ROI_RELATION_HEAD.USE_GT_BOX True
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False
MODEL.ROI_RELATION_HEAD.PREDICTOR CausalAnalysisPredictor MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE TDE MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE sum MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER motifs
TEST.IMS_PER_BATCH 1
DTYPE "float16"
GLOVE_DIR /home/fengsiyuan/Scene-Graph-Benchmark.pytorch/glove
MODEL.PRETRAINED_DETECTOR_CKPT /home/fengsiyuan/Scene-Graph-Benchmark.pytorch/checkpoints/causal-motifs-sgcls-exmp
OUTPUT_DIR /home/fengsiyuan/Scene-Graph-Benchmark.pytorch/checkpoints/causal-motifs-sgcls-exmp
预训练因果 MOTIFS-SUM 模型的示例(Examples of Pretrained Causal MOTIFS-SUM models)
SGDet/SGCls/PredCls 上预训练的因果 MOTIFS-SUM 模型示例(批量大小 12): (SGDet Download), (SGCls Download), (PredCls Download)
对应结果(论文中使用的原始模型已经丢失,这些是新的模型,因此结果存在一些波动。更多结果可以在此寻找报告结果):
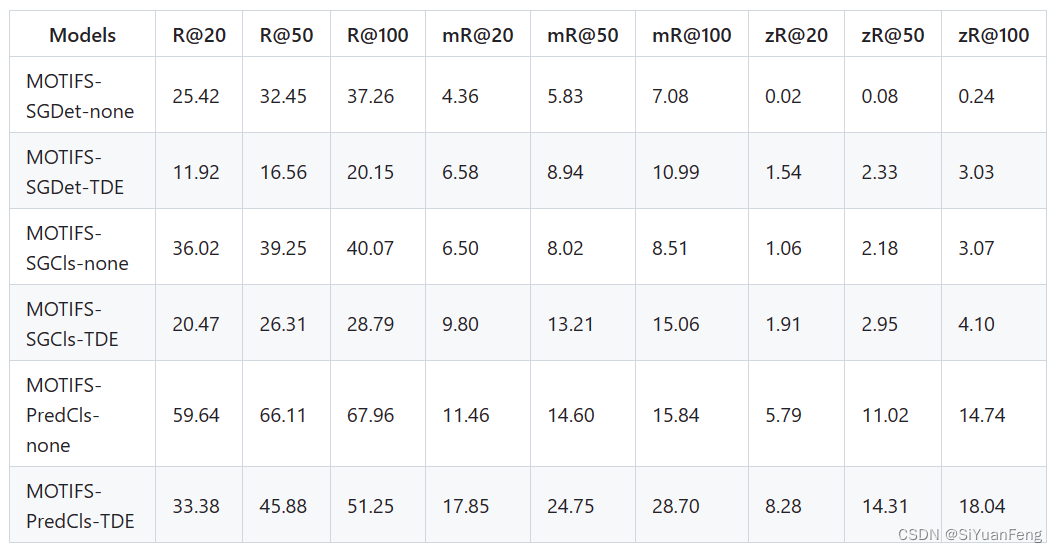
SGDet on Custom Images
请注意,对自定义图像的评估仅适用于 SGDet 模型,因为 PredCls 和 SGCls 模型需要额外的地面实况边界框信息。 要将场景图检测到您自己的图像上的 json 文件中,您需要打开开关 TEST.CUSTUM_EVAL 并向 TEST.CUSTUM_PATH 提供包含自定义图像的文件夹路径(或包含图像路径列表的 json 文件)。 仅允许 JPG 文件。 输出将作为 custom_prediction.json 保存在给定的 DETECTED_SGG_DIR 中。
Test Example 1 : (SGDet, Causal TDE, MOTIFS Model, SUM Fusion) (checkpoint)
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --master_port 10027 --nproc_per_node=1 tools/relation_test_net.py --config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" MODEL.ROI_RELATION_HEAD.USE_GT_BOX False MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False MODEL.ROI_RELATION_HEAD.PREDICTOR CausalAnalysisPredictor MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE TDE MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE sum MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER motifs TEST.IMS_PER_BATCH 1 DTYPE "float16" GLOVE_DIR /home/kaihua/glove MODEL.PRETRAINED_DETECTOR_CKPT /home/kaihua/checkpoints/causal-motifs-sgdet OUTPUT_DIR /home/kaihua/checkpoints/causal-motifs-sgdet TEST.CUSTUM_EVAL True TEST.CUSTUM_PATH /home/kaihua/checkpoints/custom_images DETECTED_SGG_DIR /home/kaihua/checkpoints/your_output_path
拆解一下这条test命令。
CUDA_VISIBLE_DEVICES=0
python -m torch.distributed.launch
--master_port 10027
--nproc_per_node=1
tools/relation_test_net.py
--config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" MODEL.ROI_RELATION_HEAD.USE_GT_BOX False
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False
MODEL.ROI_RELATION_HEAD.PREDICTOR CausalAnalysisPredictor
MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE TDE
MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE sum
MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER motifs
TEST.IMS_PER_BATCH 1
DTYPE "float16"
GLOVE_DIR /home/kaihua/glove
MODEL.PRETRAINED_DETECTOR_CKPT /home/kaihua/checkpoints/causal-motifs-sgdet
OUTPUT_DIR /home/kaihua/checkpoints/causal-motifs-sgdet
TEST.CUSTUM_EVAL True
TEST.CUSTUM_PATH /home/kaihua/checkpoints/custom_images
DETECTED_SGG_DIR /home/kaihua/checkpoints/your_output_path
Test Example 2 : (SGDet, Original, MOTIFS Model, SUM Fusion) (same checkpoint)
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --master_port 10027 --nproc_per_node=1 tools/relation_test_net.py --config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml" MODEL.ROI_RELATION_HEAD.USE_GT_BOX False MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False MODEL.ROI_RELATION_HEAD.PREDICTOR CausalAnalysisPredictor MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE none MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE sum MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER motifs TEST.IMS_PER_BATCH 1 DTYPE "float16" GLOVE_DIR /home/kaihua/glove MODEL.PRETRAINED_DETECTOR_CKPT /home/kaihua/checkpoints/causal-motifs-sgdet OUTPUT_DIR /home/kaihua/checkpoints/causal-motifs-sgdet TEST.CUSTUM_EVAL True TEST.CUSTUM_PATH /home/kaihua/checkpoints/custom_images DETECTED_SGG_DIR /home/kaihua/checkpoints/your_output_path
拆解一下这条命令:
CUDA_VISIBLE_DEVICES=0
python -m torch.distributed.launch
--master_port 10027
--nproc_per_node=1
tools/relation_test_net.py
--config-file "configs/e2e_relation_X_101_32_8_FPN_1x.yaml"
MODEL.ROI_RELATION_HEAD.USE_GT_BOX False
MODEL.ROI_RELATION_HEAD.USE_GT_OBJECT_LABEL False
MODEL.ROI_RELATION_HEAD.PREDICTOR CausalAnalysisPredictor
MODEL.ROI_RELATION_HEAD.CAUSAL.EFFECT_TYPE none
MODEL.ROI_RELATION_HEAD.CAUSAL.FUSION_TYPE sum
MODEL.ROI_RELATION_HEAD.CAUSAL.CONTEXT_LAYER motifs
TEST.IMS_PER_BATCH 1
DTYPE "float16"
GLOVE_DIR /home/kaihua/glove
MODEL.PRETRAINED_DETECTOR_CKPT /home/kaihua/checkpoints/causal-motifs-sgdet
OUTPUT_DIR /home/kaihua/checkpoints/causal-motifs-sgdet
TEST.CUSTUM_EVAL True
TEST.CUSTUM_PATH /home/kaihua/checkpoints/custom_images
DETECTED_SGG_DIR /home/kaihua/checkpoints/your_output_path
输出是一个 json 文件。 对于每个图像,场景图信息保存为包含 bbox(sorted)、bbox_labels(sorted)、bbox_scores(sorted)、rel_pairs(sorted)、rel_labels(sorted)、rel_scores(sorted)、rel_all_scores(sorted) 的字典,其中 最后的 rel_all_scores 给出每对对象的所有 51 个谓词概率。 数据集信息以 custom_data_info.json 形式保存在同一 DETECTED_SGG_DIR 中。
Visualize Detected SGs of Custom Images
要可视化检测到的自定义图像的场景图,您可以按照jupyter注释进行操作:visualization/3.visualize_custom_SGDet.jpynb。 我们的可视化代码的输入是 DETECTED_SGG_DIR 中的 custom_prediction.json 和 custom_data_info.json。 如果您成功运行上述自定义 SGDet 指令,它们将自动生成。 请注意,可能存在太多琐碎的边界框和关系,因此您可以通过更改参数 box_topk 和 rel_topk 选择 top-k bbox 和谓词以获得更好的场景图。
其他可能改善 SGG 的选项
对于某些模型(不是全部),打开或关闭 MODEL.ROI_RELATION_HEAD.POOLING_ALL_LEVELS 会影响谓词预测的性能,例如,关闭它会改善 VCTree PredCls,但不会改善相应的 SGCls 和 SGGen。 对于 VCTree 的报告结果,我们只需像其他模型一样为所有三个协议打开它。
对于某些模型(不是全部),Learning to Count Object 提出的疯狂融合将显着改善结果,看起来像 f(x1, x2) = ReLU(x1 + x2) - (x1 - x2)**2 。 它可用于组合“roi_heads/relation_head/roi_relation_predictors.py”中的主语和客体特征。 目前,我们的大多数模型只是将它们连接为“torch.cat((head_rep, tail_rep), dim=-1)”。
更不用说模型中的隐藏维度,例如“MODEL.ROI_RELATION_HEAD.CONTEXT_HIDDEN_DIM”。 由于时间有限,我们没有充分探索该项目中的所有设置,如果您通过简单地更改我们的超参数之一来改善我们的结果,我不会感到惊讶
来自有偏差训练的任何无偏差 TaskX 的提示和技巧
反事实推理不仅适用于SGG。 事实上,我的同事Yulei发现反事实因果推理在无偏见的VQA中也具有巨大的潜力。 我们相信这种反事实推理也可以应用于许多具有重大偏见的推理任务。 它基本上只运行模型两次(一次用于原始输出,另一次用于干预输出),后一次获得应从最终预测中减去的有偏差先验。 但您需要牢记三个提示:
- 最重要的事情始终是因果图。 您需要找到正确的因果图,其中包含导致有偏差的预测的可识别分支。 如果因果图不正确,剩下的就没有意义了。 请注意,因果图并不是对现有网络的总结(而是构建网络的指导),您应该根据因果图修改您的网络,但反之则不然。
- 对于因果图中具有多个输入分支的节点,选择正确的融合函数至关重要。 我们测试了很多融合函数,只发现 SUM 融合和 GATE 融合始终运行良好。 在大多数情况下,像元素产生式这样的融合函数不适用于 TDE 分析,因为来自多个分支的因果影响不再能够线性分离,这意味着它不再是可识别的“影响”。
- 对于因果图中具有多个输入分支的最终预测,可能还需要为每个分支添加辅助损失,以稳定每个独立分支的因果影响。 因为当这些分支具有不同的收敛速度时,这些硬分支很容易被学习为依赖于最快/最稳定的收敛分支的不重要的微小浮动。 辅助损耗使得不同分支具有独立且平等的影响力。
经常被询问的问题
- Q: 无法加载给定的检查点。 A:要加载的模型是基于
OUTPUT_DIR路径中的last_checkpoint文件。 如果您无法加载给定的保留检查点,可能是因为last_checkpoint文件仍然提供我的工作站中的路径而不是您自己的路径。 - Q: AssertionError on “assert len(fns) == 108073” A: 如果您正在处理 VG 数据集,这可能是由 maskrcnn_benchmark/config/paths_catlog.py 中的错误 DATASETS(数据路径)引起的。 如果您正在处理自定义数据集,只需注释掉断言即可。
- 问:model_motifs.py 中“l_batch == 1”出现断言错误 答:原始 MOTIFS 代码仅支持在 1 个 GPU 上进行评估。 由于我重新实现的主题是基于他们的代码,因此我保留此断言以确保它不会导致任何意外错误。
我在运行时对项目中的内容做的一些小修改
首先,对于文件:Scene-Graph-Benchmark.pytorch/tools/relation_test_net.py中的内容修改如下:
# 原始内容
save_dir = ""
logger = setup_logger("maskrcnn_benchmark", save_dir, get_rank())
logger.info("Using {} GPUs".format(num_gpus))
logger.info(cfg)
# 修改后内容
save_dir = "/home/fengsiyuan/Scene-Graph-Benchmark.pytorch/checkpoints" # 我们在这个dir里来保存相关的log文件
logger = setup_logger("maskrcnn_benchmark", save_dir, get_rank())
logger.info("Using {} GPUs".format(num_gpus))
logger.info(cfg)
主要修改的目的是为了能让logger文件可以打印内容并保存到checkpoints文件下。但是为了避免同时运行多个文件时,生成的log.txt内容相互覆盖,所以我们将Scene-Graph-Benchmark.pytorch/maskrcnn_benchmark/utils/logger.py文件的内容修改如下:
# 原始内容:
def setup_logger(name, save_dir, distributed_rank, filename="log.txt"):
logger = logging.getLogger(name)
logger.setLevel(logging.DEBUG)
# don't log results for the non-master process
if distributed_rank > 0:
return logger
ch = logging.StreamHandler(stream=sys.stdout)
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter("%(asctime)s %(name)s %(levelname)s: %(message)s")
ch.setFormatter(formatter)
logger.addHandler(ch)
if save_dir:
fh = logging.FileHandler(os.path.join(save_dir, filename))
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
logger.addHandler(fh)
return logger
# 修改如下:
def setup_logger(name, save_dir, distributed_rank, filename="log.txt"): #其实这个log.txt也可以改成我们想要的名字
logger = logging.getLogger(name)
logger.setLevel(logging.DEBUG)
if distributed_rank > 0:
return logger
ch = logging.StreamHandler(stream=sys.stdout)
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter("%(asctime)s %(name)s %(levelname)s: %(message)s")
ch.setFormatter(formatter)
logger.addHandler(ch)
if save_dir:
#****************代码修改部分*****************
file_path = os.path.join(save_dir, filename)
# Check if the file exists and create a new filename if necessary
base, extension = os.path.splitext(filename)
counter = 1
while os.path.exists(file_path):
new_filename = f"{base}{counter}{extension}"
file_path = os.path.join(save_dir, new_filename)
counter += 1
#fh = logging.FileHandler(os.path.join(save_dir, filename)) #这行代码也修改了,换了一个新的代码。
fh = logging.FileHandler(file_path)
#***************代码修改部分结束***************
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
logger.addHandler(fh)
return logger
同时我们将Scene-Graph-Benchmark.pytorch/maskrcnn_benchmark/data/build.py文件修改如下:
# 原本内容:
# make dataset from factory
dataset = factory(**args)
datasets.append(dataset)
# 修改内容:
dataset = factory(**args)
new_data = filter_test_data(dataset) #我们新创建的函数
datasets.append(new_data)
# 我们新创建的函数filter_test_data内容如下
def filter_test_data(dataset,save_path="/home/fengsiyuan/Scene-Graph-Benchmark.pytorch/checkpoints"):
# 定义保存文件的路径
save_file = os.path.join(save_path, 'filtered_data.pkl')
# 检查pickle文件是否存在
if os.path.exists(save_file):
print("Loading filtered data from:", save_file)
with open(save_file, 'rb') as f:
new_data = pickle.load(f)
return new_data
# 谓词数量
predicate_counts = Counter()
for i in range(len(dataset.relationships)):
for triplet in dataset.relationships[i]: # 统计和可视化都和修改无关,我们先统计和可视化出来
predicate_id = triplet[2] # 这里一定要注意,咱们的三元组,前两个是bbox的序号,最后一个才是谓词,所以和本地的代码不一样,谓词应该是triplet[2]
predicate_counts[predicate_id] += 1
print(predicate_counts)
# 谓词序号和英文名对应转换
rel_name_list = dataset.ind_to_predicates
predicate_names = [rel_name_list[id] for id in predicate_counts.keys()]
frequencies = list(predicate_counts.values())
# 绘制条形图
plt.figure(figsize=(10, 8))
plt.bar(predicate_names, frequencies, color='skyblue')
plt.xlabel('Predicate')
plt.ylabel('Frequency')
plt.title('Predicate Frequencies in Dataset')
plt.xticks(rotation=90)
plt.savefig('/home/fengsiyuan/Scene-Graph-Benchmark.pytorch/maskrcnn_benchmark/data/datasets/barplot.png') # 保存图片到文件
#plt.show()
# 开始随机选择数据并处理,把谓词平衡在max_frequency以下
max_frequency = 100
# 创建一个数据长度的索引列表,并随机打乱这些索引
indices = list(range(len(dataset.relationships)))
random.shuffle(indices)
new_predicate_counts = Counter()
new_data = copy.deepcopy(dataset) #new_data = dataset只是给dataset进行了一个新的引用方式,所以要用深复制才可以
for idx in indices:
triplets = dataset.relationships[idx]
new_triplets = []
for triplet in triplets:
predicate_id = triplet[2] # 谓词ID是三元组的第三个元素
if new_predicate_counts[predicate_id] < max_frequency:
new_triplets.append(triplet)
new_predicate_counts[predicate_id] += 1
if new_triplets:
new_data.relationships[idx] = np.array(new_triplets)
# 绘制新数据的条形图
new_frequencies = list(new_predicate_counts.values())
plt.figure(figsize=(10, 8))
plt.bar(predicate_names, new_frequencies, color='skyblue')
plt.xlabel('Predicate')
plt.ylabel('Frequency')
plt.title('Predicate Frequencies in Dataset')
plt.xticks(rotation=90)
plt.savefig('/home/fengsiyuan/Scene-Graph-Benchmark.pytorch/maskrcnn_benchmark/data/datasets/barplot2.png') # 保存图片到文件
# 数据处理完成后,将结果保存到pickle文件
print("Saving filtered data to:", save_file)
with open(save_file, 'wb') as f:
pickle.dump(new_data, f)
return new_data
最后,我们还可以关注一下这个文件里的内容
Scene-Graph-Benchmark.pytorch/maskrcnn_benchmark/config/paths_catalog.py
原始内容:
DATA_DIR = "/media/rafi/Samsung_T5/_DATASETS/"
DATASETS = {
修改内容:
DATA_DIR = "/home/fengsiyuan/Scene-Graph-Benchmark.pytorch/datasets/"
DATASETS = {
基本上只要改了这四个文件的内容就可以把嫁接着跑别的项目了。而且我们可以把新处理的数据的pickle文件直接拿来用,毕竟都是运行的maskrcnn的项目,在别的项目中也能运行起来

















 4381
4381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









