







KGBERT论文阅读
Abstract
一、目前存在的问题:
- Bert预训练语言模型:通用语言表示( General Language Representation ),缺乏特定领域的知识( Domain-Specific Knowledge )。
- 知识噪音问题:过多的知识整合可能会使句子偏离其正确含义
二、K-BERT创新点
(1) 提出了一种具有知识图(KG)的知识支持的语言表示模型(K-BERT)即 Knowledge-Enabled Language Representation Model. 通过配备KG轻松地将领域知识注入到模型中,而无需自我预训练,因为它能够从预训练的BERT加载模型参数。
(2)在特定领域的任务(包括金融、法律和医学)中,K-BERT显著优于BERT,这表明K-BERT是解决需要专家的知识驱动问题的最佳选择(Knowledge-driven problems that require experts)。
- 三元组作为领域知识被注入到句子中;
- 引入了软定位(softposition)和可见矩阵(visible matrix)来限制知识的影响
Introduction
一、BERT
- BERT(Devlin等人2018)是无监督预训练语言表示模型,在大规模开放域语料库上进行预训练,以获得通用语言表示,然后在特定的下游任务中进行微调,以吸收特定的领域知识。类似的还有GPT (Radford et al. 2018), and XLNet (Yang et al. 2019)
- 由于预训练和微调之间的领域差异,这些模型在知识驱动的任务中表现不佳。例如,在维基百科上预先训练的谷歌BERT在处理医疗领域的电子病历(EMR- Electronic Medical Record)分析任务时无法充分发挥其价值。
- 通过学习开放域语料库来刷新GLUE(Wang等人2018)基准的最新水平,但由于特定领域和开放领域之间的知识联系很少,可能会在某些特定领域的任务中失败。
- 解决这个问题的一种方法是,预先训练一个强调特定领域的模型,而不是使用公开提供的模型,然而,预训练耗时且计算成本高昂,这使得大多数用户无法接受。
- 尽管语言表示模型LR可以在预训练阶段注入特定领域的知识,但是知识的获取过程可能效率低下且昂贵。比如,如果我们希望模型获得“paracetamol可以治疗感冒”的知识,那么需要大量的“paracetamol”和“cold”在预训练语料库中联合出现。
二、专家的知识驱动
- 当阅读特定领域的文本时,普通人只能根据上下文理解单词,而专家则能够根据相关领域知识进行推断。
- 使模型成为领域专家:
(1)知识图谱kg在本体论的早期研究中是一个很好的解决方案。随着知识的改进成为结构化形式,许多领域的kg都得到了构建。例如:在医学领域SNOMED-CT (Bodenreider 2008),在中文概念HowNet (Dong, Dong, and Hao 2006)。
(2)知识集成:如果知识图谱可以集成到LR模型中,为模型配备领域知识,提高模型对特定领域任务的性能,同时大规模降低预训练的成本。此外,由于注入的知识是可手动编辑的,因此生成的模型是具有更大的可解释性的。 - 知识集成的两个挑战:
(1)异构嵌入空间HES:在kg中,文本中的单词和kg中的实体的嵌入向量是以不同的方式获取的,使其向量空间不一致。
(2)知识边缘噪声KN:过多的知识引入可能会使句子偏离其正确含义。
应对措施:提出了一种Knowledge-enabled Bidirectional Encoder Representation from Transformers (K-BERT),K-BERT可以加载任何的预训练Bert模型,由于其参数相同。kbert通过配备kg,无需预训练轻松地将领域知识注入模型中。K-BERT的这一特性对于计算资源有限的用户来说非常方便。 - 在12个中国NLP任务的实验结果表明,K-BERT在特定领域的任务上获得了优异的性能。
本文的贡献如下:
- 提出了一种知识赋能的LR模型,即K-BERT,它与BERT兼容,可以在没有HES和KN问题的情况下结合领域知识;
- 随着KG的精妙地注入,K-BERT不仅在特定领域的任务上显著优于BERT,而且在开放领域的许多任务上也优于BERT;
- K-BERT的代码和自主开发的知识图放于https://github.com/autoliuweijie/K-BERT。
Related Work
- BERT的优化工作主要集中在预训练过程和编码器上。
(1)在预训练方面: Baidu-ERNIE(Sun等人2019)和 BERT-WWM(Cui等人2019)采用全词掩蔽而非单字符掩蔽来预训练汉语语料库中的BERT。SpanBERT(Joshi等人2019)通过屏蔽连续随机跨度来扩展BERT,并提出了跨度边界目标。RoBERTa(Liu等人2019)通过三种方式优化了BERT的预训练,即删除下一句预测的目标、动态改变掩蔽策略和使用更多更长的句子进行训练。
(2)在编码器方面:XLNet(Yang等人2019)将BERT中的Transformer替换为Transformer XL(Dai等人2019),以提高其处理长句的能力。THU-ERNIE(Zhang等人2019)将BERT的编码器修改为聚合器,用于单词和实体的相互集成。 - 预训练的LR模型与KG的融合
(1)THU-ERNIE(Zhang et al 2019)是融合实体信息的这一方向的先驱,但实体之间的关系被它忽略了;
(2)COMET(Bosselut等人2019)使用KG中的三元组作为语料库来训练GPT(Radford等人2018)进行常识学习,这非常低效。
3.KG与单词向量的融合
(1)Wang等人(2014)基于word2vec的思想,提出了一种将实体和单词联合嵌入同一连续向量空间的新方法(Mikolov等人2013)。
(2)Toutanova等人(2015)提出了一个模型,该模型捕捉文本关系的组成结构,并以联合方式优化实体、知识库和文本关系表示。
(3)Han、Liu和Sun(2016)应用卷积神经网络和KG完成任务,共同学习文本和知识的表示。
这些方法的主要缺点是它们仍然基于“word2vec+transE”的思想(Bordes等人)。尽管他们使用联合表示的方法使实体和单词的向量空间更接近,但仍然存在HES问题。更重要的是,对于拥有数百万个实体的KGs,这种想法使实体表非常大,因为它超过了GPU的内存大小,因此无法使用。
Methodology
- 符号说明
一个句子s = {w0, w1, w2,…, wn}作为标记(Token)序列,其中n表示此句的长度。在本文中,英语标记取word级,而中文标记取character级。每个标记(token)wi都包含在词汇表V中,即wi∈V, KG记为K,是三元组ε = (wi, rj, wk)的集合,其中wi和wk是实体,rj∈V表示为实体之间的关系。所有三元组的单位都是KG,即ε∈K。 - 模型架构
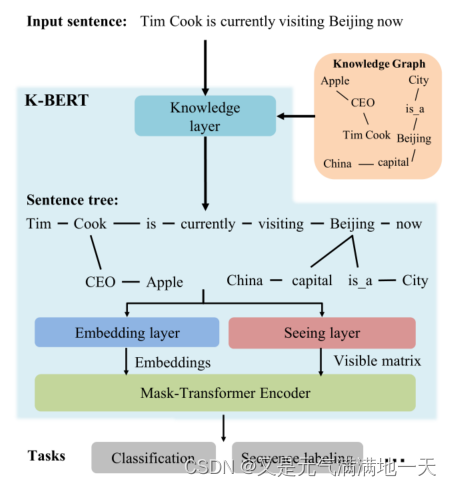
(图片说明)K-BERT的模型架构:与其他RL模型相比,K-BERT具有可编辑的KG,可根据其应用领域进行调整。例如,对于电子病历分析,我们可以使用一个医疗KG来授予具有医疗知识的K-BERT,
- K -BERT的模型架构由四个模块组成,分别是知识层Knowledge Layer、嵌入层Embedding Layer、观察层Seeing Layer和掩模转换器Mask-Transformer。
- 对于输入的句子,知识层首先从KG中往原句注入相关的三元组,将其转化为知识丰富的句子树。然后将句子树同时输入至Embeddin层和Seeing层。然后转换为token级embedding表示和可见矩阵visible matrix。使用可见矩阵来控制每个token的可见区域,防止由于太多的知识注入而改变原始句子的含义。
-
知识层Knowledge Layer
(1)知识层(KL)用于句子知识注入和句子树转换。
(2)具体来说,给定一个输入句子s = {w0, w1, w2,…, wn}和KG-K,输出句子树t = {w0, w1,…, wi{(ri0, wi0),…, (rik, wik),…, wn}。该过程可分为两个步骤:知识查询(K-Query)和知识注入(K-Inject)。
(3)在K-Query中,将句子中涉及的所有实体名称从K中选择出来,查询其对应的三元组。K-Query可以表述为如下: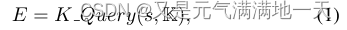
其中E = {(wi, ri0, wi0),…, (wi, rik, wik)}是对应三元组的集合。
(4)K-Inject通过将E中的三元组拼接到相应的位置,将查询到的E注入到句子s中,生成句子树t, t的结构如图3所示。
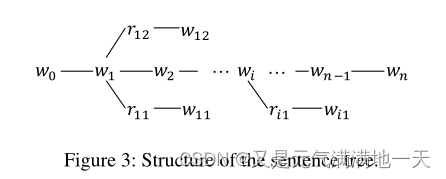
句子树可以有多个分支,但其深度固定为1,这意味着三元组中的实体名称不会迭代派生分支,K-Inject公式为如下:
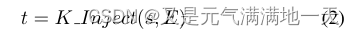
-
嵌入层Embedding Layer
(1)嵌入层的作用是将句子树转换为嵌入表示,并将其输入到Mask-Transformer中。
(2)与BERT相似的是,K-BERT的嵌入表示是三个部分的总和:标记嵌入token、位置嵌入soft-position和段segment嵌入。但不同的是,K-BERT的嵌入层的输入是一个句子树,而不是一个标记token序列。

因此,如何在保留句子树结构信息的前提下,将句子树转化为序列是KBERT的关键。
(3)Token embedding:与BERT一致,本文采用Google BERT提供的词汇表。通过一个可训练的查找表,将句子树中的每个token转换为一个维数为H的嵌入向量。此外,K-BERT还使用[CLS]作为分类标记,并使用[MASK]来mask tokens。K-BERT和BERT的token嵌入的区别在于,句子树中的token需要在嵌入操作之前重新排列。在我们的重新排列策略中,分支中的令牌被插入到相应的节点之后,而后续的令牌被向后移动。
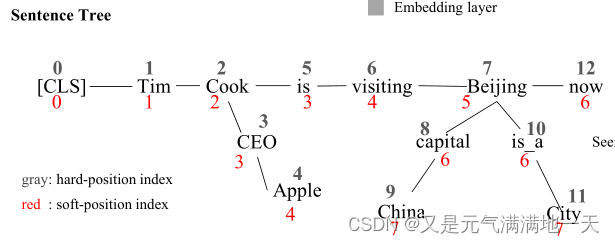
如上图所示,句子树被重新排列为“Tim Cook CEO Apple is visiting Beijing capital China is a City now”。这一过程虽然简单,但却使句子无法读懂,丢失了正确的结构信息。解决办法为通过软位置 soft-position和可见矩阵 visible matrix来求解。
(4)soft-position embedding:对于BERT,如果没有位置嵌入position-embedding,它将相当于一个词袋模型,导致结构信息(即token的顺序)的缺乏。BERT输入句子的所有结构信息都包含在位置嵌入中,这允许我们将缺失的结构信息添加回不可读的重排句子中。举例:在重排之后,[CEO] 和 [Apple] 插入 [Cook]和[is]之间, 但是[is] 的主语应该为 [Cook]而不是[Apple]。为了解决这个问题,只需要将[is]的位置数设置为3而不是5。在计算self-attention score 中的 transformer encoder时,[is]是在[Cook]的下一个位置。然而,存在问题为[is]和[CEO]的位置号都为3,在计算self-attention score时,它们的位置很接近,但实际上它们之间并没有联系。解决这个问题的方法是“Mask-Self-Attention”。
(5)Segment embedding:和BERT一样,K-BERT在包含多个句子时也使用分段嵌入来识别不同的句子。例如,当两个句子{w00, w01,…, w0n}和{w10, w11,…, w1m}组合成一个句子{[CLS], w00, w01,…, w0n, [SEP], w10, w11,…, w1m}(用[SEP])。对于组合句,用一组段标记{A, A, A, A,…, A,B,B,…B}。在分段嵌入中,上图第一句中的所有标记都被标记为“A”。
-
观察层Seeing Layer
(1)K-BERT和BERT最大的区别就是此层,也是这个方法如此有效的原因。
(2)K-BERT的输入是一个句子树,其中的分支是从KG获得的知识。然而,知识带来的风险是,它可能导致原句的意思发生变化,即KN问题。例如,在图2的句子树中,[China]只修饰了[Beijing],与[Apple]没有任何关系。因此,[Apple]的表示不应受到[China]的影响。并且,用于分类的[CLS]标签不应该绕过[Cook]来获取[Apple]的信息,因为这样会带来语义变化的风险。为了防止这种情况发生,K-BERT使用一个可见矩阵M来限制每个token的可见区域,这样[Apple]和[China], [CLS]和[Apple]彼此就不可见了。可见矩阵M定义为如下:

Wi-Wj表示Wi和Wj在同一个分支中,Wi /Wj则表示不是在同一分支中。I和j是hard-position index。在 hard-position中,句子树中的token被平铺成一个token嵌入序列 -
Mask-Transformer
(1)可见矩阵M在一定程度上包含了句子树的结构信息。BERT中的Transformer编码器不能接收M作为输入,因此我们需要将其修改为Mask-Transformer,可以根据M修改限制self-attention区域。Mask-Transformer是一个由多个mask-self-attention块组成的堆栈。作为BERT,将层数(i.e.,mask-self-attention blocks)表示为L,hidden size为H,mask-self-attention head表示为A。

(2)Mask-Self-Attention
为了利用M中的句子结构信息防止错误的语义变化,我们提出了一个 mask-self-attention,它是self-attention的延伸。从形式上讲,mask-self-attention是如下:
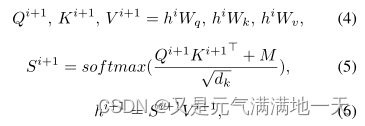
Wq、Wk和Wv是可训练的模型参数,hi是第i个mask-self-attention的隐藏状态,dk是比例因子1,M为seeing层计算的可见矩阵。如果wk对wj是不可见的,那么Mjk将把注意力评分Si+1(jk)屏蔽为0,这意味着wk对wj的隐藏状态没有贡献。为了抵消点积量级增大的影响,笔者将点积乘以1/√dk。
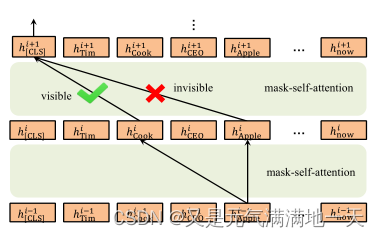
如图4所示,hi[Apple]对hi+1 [CLS]没有影响,因为[Apple]对[CLS]是不可见的。但是hi+1 [CLS]可以通过hi+1 [Cook]间接获取hi−1 [Apple]的信息,因为[Apple]对[Cook]可见,[Cook]对[CLS]可见。这个过程的好处是[Apple]丰富了[Cook]的表征,但不直接影响原句的意思。
Experiments
详细介绍了12个中文NLP任务的K-BERT微调结果,其中8个是开放域任务,4个是特定域任务。
- 预训练语料
本文采用了两个中文语料库进行预训练,即wikiz和WebtextZh。
(1)WikiZh:指中文维基百科语料库,用于训练中文BERT 。维基百科包含了100万个结构良好的中文条目,1.2亿句句子,大小1.2G。
(2)WebtextZh:是一个大型的、高质量的中文问答语料库,有410万条条目,大小3.7G。WebtextZh中的每个条目都属于一个主题,共有28000个主题。 - 知识图谱
本文采用三个中文KG, CN-DBpedia4, HowNet5和MedicalKG
(1)CN-DBpedia (Xu et al . 2017)是复旦大学知识工作实验室开发的一个大型开放域百科KG,涵盖了数千万个实体和数亿个关系。本文通过剔除实体名长度小于2或包含特殊字符的三元组,对官方CN-DBpedia进行了改进。改进的CN-DBpedia总共包含517万个三元组。
(2)HowNet是一个关于汉语词汇和概念的大型语言知识库(Dong, Dong, and Hao 2006),其中每个汉语单词都有被称为义位的语义单位注释。如果我们把{词、包含、义位}作为一个三元组,那么HowNet就是一种语言KG。类似地,我们通过消除实体名称长度小于2或包含特殊字符的三元组来改进官方的HowNet。经过改进的HowNet总共包含52,576个三元组。
(3)MedicalKG是我们自主开发的中医概念KG,包含四种缩略词(症状、疾病、部位和治疗)。MedicalKG总共包含13,864个三元组,是K-BERT的一部分,是开源的。 - Baselines
(1) Google BERT:该模型在wikipedia上进行了预训练,并由谷歌发布(Devlin et al 2018)。
(2)K-BERT的重新实现,在WikiZh和WebtextZh上进行了预训练。 - 参数设置和训练细节
为了反映KG在RL模型中的作用,根据Goole-BERT的基本版本将K-BERT和BERT配置为相同的参数设置。将(mask-)self-attention层数和头数分别表示为L和A,将嵌入向量的hidden维数表示为H。具体有如下:模型配置:L = 12, A = 12, H = 768。BERT和KBERT的可训练参数总数相同(110M),这意味着它们在模型参数上是相互兼容的。
在K-BERT预训练阶段,所有设置都与BERT一致。在预训练阶段,不会给K-BERT增加任何KG值。因为KG将两个相关的实体名称绑定在一起,使得预先训练的两个实体的词向量非常接近甚至相等,导致语义丢失。因此,在预训练阶段,K-BERT和BERT是等价的,后者的参数可以分配给前者。KG将在微调 fine-tuning和推断 inferring阶段启用。 - 开放域任务
首先比较了KBERT和BERT在8个中文开放域NLP任务中的性能。在这8个任务中,Book review、Chnsenti-corp, Shopping, and Weibo是单句分类任务;XNLI、LCQMC 是两句分类任务,NLPCC-DBQA是问答匹配任务,MSRA-NER 是命名实体识别(NER)任务:
(1)Book review:本数据集包含来自豆瓣11的2万条好评和2万条差评;
(2)Chnsenticorp :是一个酒店评论数据集,共有12000条评论,其中6000条好评和6000条差评;
(3)Shopping:是一个在线购物评论数据集,包含40000条评论,其中包括21111条正面评论和18889条负面评论;
(4)Weibo:是新浪微博情感标注的数据集,包含6万个积极样本和6万个消极样本。
(5)XNLI:是一个跨语言语言理解数据集,其中每个条目包含两个句子,任务是确定它们的关系(“蕴涵”、“矛盾”或“中立”);
(6)LCQMC:是一个大型中文问题匹配语料库。这个任务的目标是确定这两个问题是否有相似的意图;
(7)NLPCC-DBQA:是一个预测给定文档中每个问题答案的任务;
(8)MSRA-NER:是微软发布的NER数据集。这个任务是识别文本中的实体名称,包括人名、地名、组织名称等。
上面的每个数据集都被分为三个部分:train, dev和test。我们使用train部分对模型进行微调,然后在dev和test部分评估其性能。实验结果如表1和表2所示,结果可分为三类:
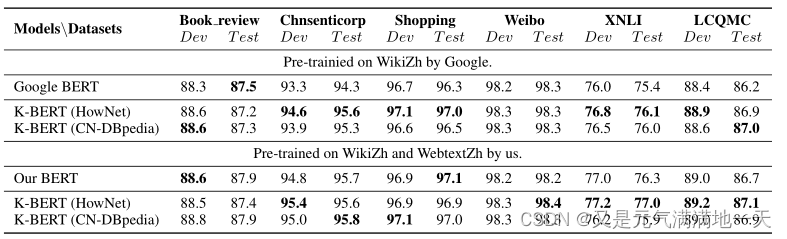
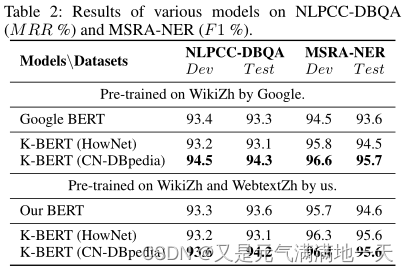
- 结果
(1)KG对情感分析任务(i.e., Book review, Chnsenticorp, Shopping and Weibo)的影响不显著,因为句子的情感可以在不需要任何知识的情况下通过情感词汇来判断;
(2)语言KG(HowNet)在语义相似任务(i.e., XNLI and LCQMC)上的表现优于百科式encyclopedic KG;
(3)对于问答和NER任务(即NLPCC-DBQA和MSRA-NER),百科式KG (CN-DBpedia)比语言式(HowNet)KG更适合。
(4)使用额外的语料库(WebtextZh)也可以带来性能提升,但不如KG显著。如表2 MSRA-NER所示,CN-DBpedia将F1从93.6%提高到95.7%,而WebtextZh仅将F1提高到94.6%。 - 特定领域的任务
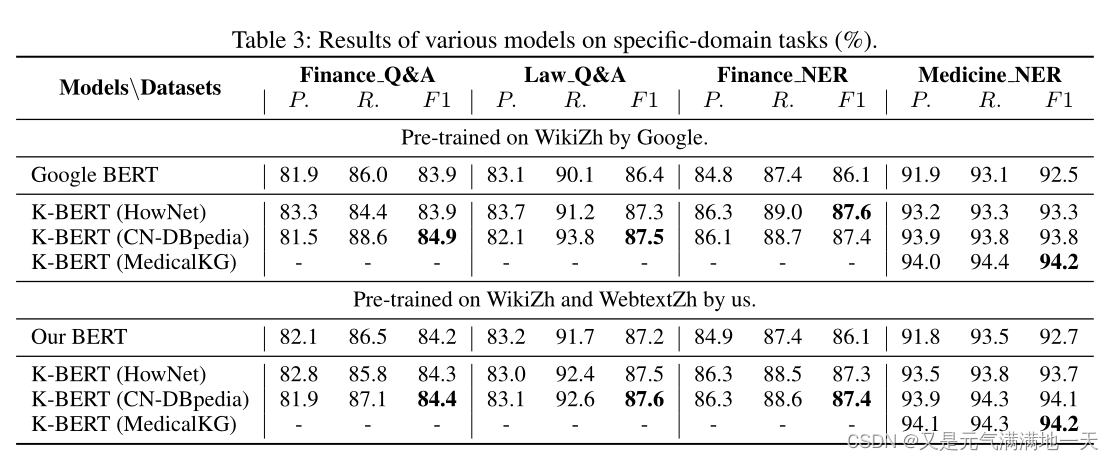
K-BERT真正发挥作用的任务是在特定的领域,因为KG善于给出具有领域知识的LR模型。
(1)特定领域的Q&A:从百度知道(ZhiDao)上抓取了大约77万和3.6万份金融和法律领域的问答样本,包括问题、网友答案和最佳答案。
在此基础上,我们构建了金融问答和法律问答两个数据集。任务是从网友的回答中选出问题的最佳答案。
(2)特定领域的NER Finance NER14是一个数据集,包括3000篇手动标记的超过65,000个名称实体(人物、地点和组织)的财经新闻文章。医学NER是CCKS 201715中发布的临床命名实体识别(CNER)任务。目标是从电子医疗记录中提取与医疗相关的实体名称
(3)特定领域的数据集被分为三个部分:train, dev和test,分别用于微调、选择和测试模型。各型号的测试结果如表3所示,其中P、R、f1分别为Precision、Recall、F1-score。与BERT相比,K-BERT在域任务方面有显著的性能提升。对于F1, K-BERT与CN-DBpedia结合可以使所有任务的性能提高1 ~ 2%。独特受益于之KG的领域知识。此外,从表3中的Medicine NER可以观察到,使用MedicalKG的性能改善非常明显。从这些结果中,我们可以得出这样的结论:KG对于特定于域的任务非常有帮助。
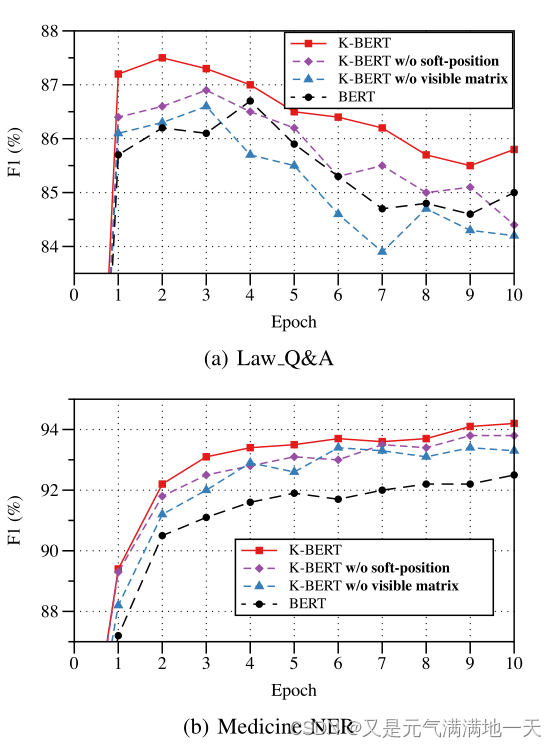
通过两个领域特定任务(法律问答和医学NER)探讨软位置和可见矩阵对K-BERT的影响。“w/o软位”是指用硬位代替软位微调K-BERT。“w/o可见矩阵”意味着所有标记彼此可见。BERT等于没有KG的K-BERT。
如下图所示,我们观察到:
(1)在两种任务中,没有软位置和可见矩阵时,K-BERT的性能都有所下降;
(2)在Law Q&A中,无可见矩阵的K-BERT比BERT差,证实了KN的存在,即不恰当的添加知识会导致性能下降;
(3)在Law Q&A种,K-BERT在epoch 2达到峰值,而BERT在epoch 4,证明K-BERT的收敛速度比BERT快。
总的来说,我们可以得出结论,软位置和可见矩阵可以使K-BERT对KN干扰的鲁棒性更强,从而更有效地利用知识。
结论
(1)在本文中,我们提出K-BERT方法来实现知识图的语言表示,实现常识或领域知识的能力。具体来说,K-BERT首先将KG的知识注入到句子中,使句子成为知识丰富的句子树。其次,采用软位置和可见矩阵控制知识范围,防止知识偏离其本义。
(2)尽管HES和KN存在挑战,但我们的研究在12个开放/特定领域的NLP任务上揭示了有希望的结果。实证结果表明,KG方法对知识驱动的特定领域任务特别有帮助,可以用于解决需要领域专家的问题。此外,K-BERT与BERT的模型参数兼容,这意味着用户可以直接在K-BERT上采用已有的经过预训练的BERT参数(如谷歌BERT、Baidu-ERNIE等),而无需自己进行预训练。
(3)这些积极的结果指向未来的工作:
第一:改进K-Query,使其能够基于上下文过滤不重要的三元组;
第二:将该方法扩展到其他LR模型,如ELMo (Peters等,2018),XLNet (Yang等,2019)等;















 596
596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









