






1.任务描述
记录7个模型(逻辑回归、SVM、决策树、随机森林、GBDT、XGBoost和LightGBM)关于accuracy、precision,recall和F1-score、auc值的评分表格,并画出ROC曲线。
2.评分方法介绍
模型的‘好坏’是相对的,什么样模型是好的,不仅取决于算法和数据好决定于任务需求。性能度量反映了任务需求,在对比不同模型的能力时,不同的性能度量往往会导致不同的评判结果。
回归问题:
均方误差。
分类问题:(源自西瓜书)
- accuracy 精度
分类正确的样本占总样本的比例:
(概率密度p(.))
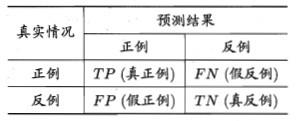
- precision 准确率(查准率)
预测为正例的样本中有多少是真正例。(西瓜书上的说法:挑出的瓜中(表示你认为是好瓜)有多少是好瓜。)
混淆矩阵:
- recall 召回率(查全率)
正例中有多少样本被成功预测为正例。(西瓜书上的说法:所有的好瓜中有多少比例被挑了出来)
查准率和查全率是一对矛盾的度量。
- P-R曲线
根据学习器的预测结果对样例进行排序,排在前面的为最可能的正例,排在最后面的是最不可能的正例。逐个吧样本作为正例进行预测,根据此时的查准率查全率可以得到查准率-查全率曲线(P-R曲线)
采用P-R曲线下的面积在一定程度上反应了查准率和查全率取得双高的比例。单这个值不容易估算。
平衡点(Break-Event Point,BEP)查准率=查全率的点。过于简化。
- F1-score
查准率和查全率的调和平均:
更一般的形式,表达出对查准率和查全率的不同偏好:
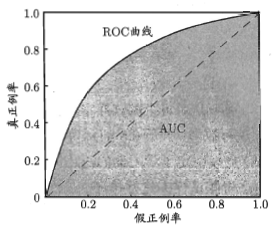
- auc值(Area Under ROC Curve)
ROC曲线下的面积.
估算方法:
(Xi,Yi)为ROC曲线按序连接的点。
AUC与排序误差有密切联系。排序误差为:
排序损失是ROC曲线之上的面积,则有:
- ROC曲线(Receiver Operating Characteristic)
受试者工作特征曲线:
纵轴是真正例率(True Positive Rate,TPR)【正例中有多少被预测为正例】
横轴是假正例率(False Positive Rate,FPR)【反例中有多少被预测为正例】
ROC图如下,对角线对应于随机猜测:
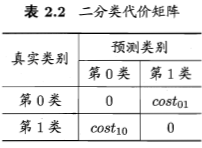
- 代价敏感错误率和代价曲线
不同类型的错误造成不同的损失,即非均等代价。
代价敏感错误率为:
代价曲线,横轴为正例概率代价,纵轴是归一化代价:
(横)
(纵)
(ROC曲线上的每一点对应代价曲线上的一条线段)

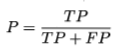

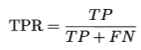
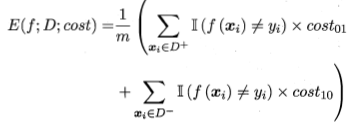
3.代码实现
- 包导入以及数据预处理
from pandas import Series,DataFrame
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn import tree
from sklearn.linear_model import LogisticRegression
import lightgbm as lgb
import xgboost as xgb
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import auc
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
#数据读入
data = pd.read_csv(r'data_all.csv')
#划分训练及和测试集
X = data.drop(['status'],axis = 1)
y = data['status']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3,random_state = 2018)
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)- 模型评价函数:
#评分和绘制ROC曲线
def model_evaluation(y_label,y_predict,y_predict_pro):
accuracy = accuracy_score(y_label,y_predict)
precision = precision_score(y_label,y_predict)
recall = recall_score(y_label,y_predict)
f1 = f1_score(y_label,y_predict)
auc = roc_auc_score(y_label,y_predict_pro)
fpr,tpr,thresholds = roc_curve(y_label,y_predict_pro)
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.show()
print 'accuracy:',accuracy
print 'precision:',precision
print 'recall:',recall
print 'f1_score:',f1
print 'roc_auc_score:',auc- 各个模型训练和评估
#SVM
clf_svm = svm.SVC(random_state = 2018)
clf_svm.fit(X_train,y_train)
#训练集预测标签和概率输出
train_svm_predict = clf_svm.predict(X_train)
train_svm_predict_pro = clf_svm.decision_function(X_train)
#测试集预测标签和概率输出
test_svm_predict = clf_svm.predict(X_test)
test_svm_predict_pro = clf_svm.decision_function(X_test)
#训练集评分
model_evaluation(y_train,train_svm_predict,train_svm_predict_pro)
#测试集评分
model_evaluation(y_test,test_svm_predict,test_svm_predict_pro)
#决策树
clf_tree = tree.DecisionTreeClassifier(random_state = 2018)
clf_tree.fit(X_train,y_train)
#训练集预测标签和概率输出
train_tree_predict = clf_tree.predict(X_train)
train_tree_predict_pro = clf_tree.predict_proba(X_train)[:,1]
#测试集预测标签和概率输出
test_tree_predict = clf_tree.predict(X_test)
test_tree_predict_pro = clf_tree.predict_proba(X_test)[:,1]
#训练集评分
model_evaluation(y_train,train_tree_predict,train_tree_predict_pro)
#测试集评分
model_evaluation(y_test,test_tree_predict,test_tree_predict_pro)
#LR
clf_lr = LogisticRegression(random_state=2018)
clf_lr.fit(X_train,y_train)
#训练集预测标签和概率输出
train_lr_predict = clf_lr.predict(X_train)
train_lr_predict_pro = clf_lr.predict_proba(X_train)[:,1]
#测试集预测标签和概率输出
test_lr_predict = clf_lr.predict(X_test)
test_lr_predict_pro = clf_lr.predict_proba(X_test)[:,1]
#训练集评分
model_evaluation(y_train,train_lr_predict,train_lr_predict_pro)
#测试集评分
model_evaluation(y_test,test_lr_predict,test_lr_predict_pro)
#随机森林
clf_rf = RandomForestClassifier(random_state = 2011)
clf_rf.fit(X_train,y_train)
#训练集预测标签和概率输出
train_rf_predict = clf_rf.predict(X_train)
train_rf_predict_pro = clf_rf.predict_proba(X_train)[:,1]
#测试集预测标签和概率输出
test_rf_predict = clf_rf.predict(X_test)
test_rf_predict_pro = clf_rf.predict_proba(X_test)[:,1]
#训练集评分
model_evaluation(y_train,train_rf_predict,train_rf_predict_pro)
#测试集评分
model_evaluation(y_test,test_rf_predict,test_rf_predict_pro)
#GBDT
clf_gbdt = GradientBoostingClassifier()
clf_gbdt.fit(X_train,y_train)
#训练集预测标签和概率输出
train_gbdt_predict = clf_gbdt.predict(X_train)
train_gbdt_predict_pro = clf_gbdt.predict_proba(X_train)[:,1]
#测试集预测标签和概率输出
test_gbdt_predict = clf_gbdt.predict(X_test)
test_gbdt_predict_pro = clf_gbdt.predict_proba(X_test)[:,1]
#训练集评分
model_evaluation(y_train,train_gbdt_predict,train_gbdt_predict_pro)
#测试集评分
model_evaluation(y_test,test_gbdt_predict,test_gbdt_predict_pro)
#XGBoost
clf_xgb = xgb.XGBClassifier()
clf_xgb.fit(X_train,y_train)
#训练集预测标签和概率输出
train_xgb_predict = clf_xgb.predict(X_train)
train_xgb_predict_pro = clf_xgb.predict_proba(X_train)[:,1]
#测试集预测标签和概率输出
test_xgb_predict = clf_xgb.predict(X_test)
test_xgb_predict_pro = clf_xgb.predict_proba(X_test)[:,1]
#训练集评分
model_evaluation(y_train,train_xgb_predict,train_xgb_predict_pro)
#测试集评分
model_evaluation(y_test,test_xgb_predict,test_xgb_predict_pro)
#lightGBM
clf_lgb = lgb.LGBMClassifier()
clf_lgb.fit(X_train,y_train)
#训练集预测标签和概率输出
train_lgb_predict = clf_lgb.predict(X_train)
train_lgb_predict_pro = clf_lgb.predict_proba(X_train)[:,1]
#测试集预测标签和概率输出
test_lgb_predict = clf_lgb.predict(X_test)
test_lgb_predict_pro = clf_lgb.predict_proba(X_test)[:,1]
#训练集评分
model_evaluation(y_train,train_lgb_predict,train_lgb_predict_pro)
#测试集评分
model_evaluation(y_test,test_lgb_predict,test_lgb_predict_pro)- 结果比较
| 模型 | accuracy | precision | recall | F1-score | auc值 |
| LR | 训练集:0.8049 测试集:0.7877 | 训练集:0.7069 测试集:0.6609 | 训练集:0.3789 测试集:0.3203 | 训练集:0.4934 测试集:0.4315 | 训练集:0.8198 测试集:0.7657 |
| SVM | 训练集:0.8428 测试集:0.7806 | 训练集:0.9147 测试集:0.7017 | 训练集:0.4113 测试集:0.2228 | 训练集:0.5674 测试集:0.3383 | 训练集:0.9218 测试集:0.7531 |
| 决策树 | 训练集:1.0 测试集:0.6854 | 训练集:1.0 测试集:0.3840 | 训练集:1.0 测试集:0.4150 | 训练集:1.0 测试集:0.3989 | 训练集:1.0 测试集:0.5956 |
| 随机森林 | 训练集:0.9811 测试集:0.7617 | 训练集:1.0 测试集:0.5629 | 训练集:0.9245 测试集:0.2367 | 训练集:0.9607 测试集:0.3333 | 训练集:0.9990 测试集:0.7096 |
| GBDT | 训练集:0.8623 测试集:0.7799 | 训练集:0.8837 测试集:0.6087 | 训练集:0.5192 测试集:0.3509 | 训练集:0.6541 测试集:0.4452 | 训练集:0.9207 测试集:0.7622 |
| XGBoost | 训练集:0.8512 测试集:0.7919 | 训练集:0.8645 测试集:0.6550 | 训练集:0.4820 测试集:0.3649 | 训练集:0.6189 测试集:0.4687 | 训练集:0.9186 测试集:0.7707 |
| LightGBM | 训练集:0.9958 测试集:0.7701 | 训练集:1.0 测试集:0.5689 | 训练集:0.9823 测试集:0.3565 | 训练集:0.9915 测试集:0.4383 | 训练集:1.0 测试集:0.7535 |
应该是因为参数的问题,模型之间差异不大,集成学习也没有体现出应有的优势。
- ROC结果
 (LR)
(LR) (SVM)
(SVM)
 (决策树)
(决策树) (随机森林)
(随机森林)
 (GBDT)
(GBDT) (XGBoost)
(XGBoost)
 (LightGBM)
(LightGBM)















 2126
2126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









