









数据还是采用这个例子里的数据,具体背景也同上。
添模型构建——使用逻辑回归构建模型,lightGBM进行特征筛选
lightGBM模型介绍请看这个链接:集成学习——Boosting算法:Adaboost、GBDT、XGBOOST和lightGBM的简要原理和区别
具体代码如下:
导入模块
# 导入模块
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.metrics import roc_auc_score, roc_curve, classification_report
from sklearn import metrics
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
import math
读取数据
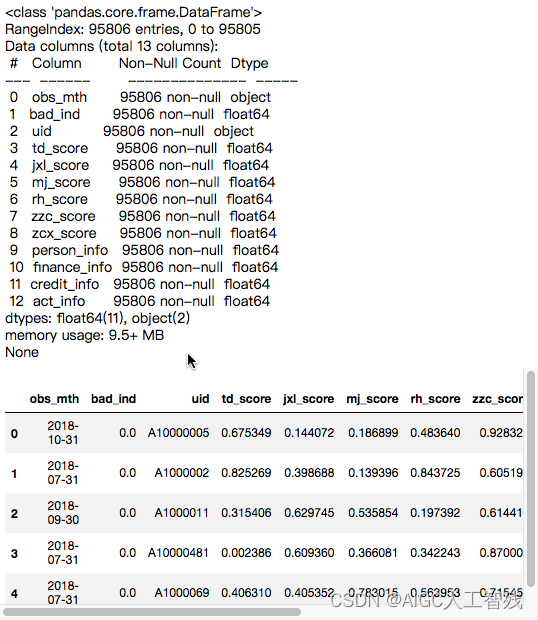
df = pd.read_csv('Bcard.txt')
print(df.info())
df.head()
划分训练集和测试集
# 划分测试集和验证集
train = df[df.obs_mth!='2018-11-30'].reset_index().sort_values('obs_mth', ascending=False)
val = df[df.obs_mth == '2018-11-30'].reset_index()
train.head()
将训练集的数据进行分组
# 按照时间先后顺序分为5组
train['rank'] = [i for i in range(train.shape[0])]
train['rank'] = pd.cut(train['rank'], bins=5, labels=[i for i in range(5)])
train['rank'].value_counts()

获取特征
ft_lst = train.columns
ft_lst=ft_lst.drop(['index','rank','bad_ind','obs_mth','uid'])
ft_lst

定义模型函数
# 先定义lgb模型函数
def lgb_test(train_X,train_y,test_X,test_y):
from multiprocessing import cpu_count
lgb_clf = lgb.LGBMClassifier(learning_rate=0.05,n_estimators=100)
lgb_clf.fit(train_X, train_y, eval_set=[(train_X, train_y), (test_X, test_y)], eval_metric='auc', early_stopping_rounds=100)
lgb.plot_metric(lgb_clf,metric='auc')
# print(lgb_clf.n_features_)
return lgb_clf, lgb_clf.best_score_['valid_1']['auc']
进行特征交叉筛选
# 使用lightgbm进行特征交叉筛选
feature_lst = []
ks_train_lst = []
ks_test_lst = []
# 按照组别对其进行特征筛选
for rk in set(train['rank']):
test_df = train[train['rank']==rk]
train_df = train[train['rank']!=rk]
train_X = train_df[ft_lst]
train_y = train_df.bad_ind
test_X = test_df[ft_lst]
test_y = test_df.bad_ind
model,auc = lgb_test(train_X,train_y,test_X,test_y)
feature = pd.DataFrame({
'name':model.booster_.feature_name(),
'importance':model.feature_importances_
}).set_index('name')
feature_lst.append(feature)
pred_y_train = model.predict_proba(train_X)[:,1]
pred_y_test = model.predict_proba(test_X)[:,1]
train_fpr, train_tpr,_ = roc_curve(train_y, pred_y_train)
test_fpr, test_tpr, _ =roc_curve(test_y, pred_y_test)
train_ks = abs(train_fpr-train_tpr).max()
test_ks = abs(test_fpr-test_tpr).max()
train_auc = metrics.auc(train_fpr, train_tpr)
test_auc = metrics.auc(test_fpr, test_tpr)
ks_train_lst.append(train_ks)
ks_test_lst.append(test_ks)
计算ks
print('train_ks', np.mean(ks_train_lst))
print('test_ks', np.mean(ks_test_lst))
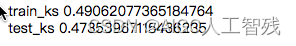
进行特征筛选
# 将5组特征值组合取平均值,并取大于20的特征
feature_importance = pd.concat(feature_lst, axis=1).mean(axis=1)
lst = feature_importance[feature_importance>20].index.to_list()
lst

使用模型构建评分卡
# 使用lightgbm构建评分卡
X= train[lst]
y = train.bad_ind
evl_X = val[lst]
evl_y = val.bad_ind
# 训练集的分类评估
model, auc = lgb_test(X,y, evl_X, evl_y)
y_pred = model.predict_proba(X)[:,1]
train_fpr, train_tpr,_ = roc_curve(y, y_pred)
train_ks = abs(train_fpr-train_tpr).max()
train_auc = metrics.auc(train_fpr, train_tpr)
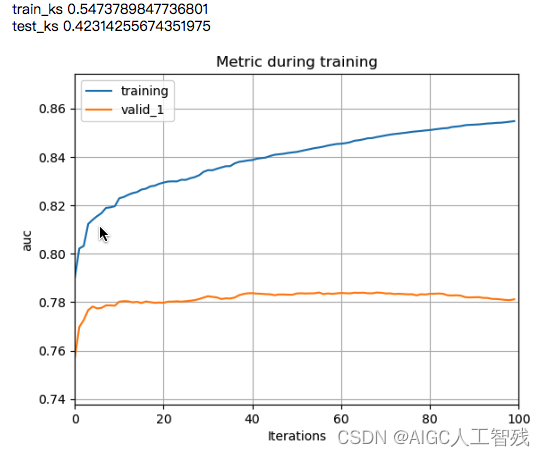
print('train_ks',train_ks)
# 测试集的分类评估
y_pred = model.predict_proba(evl_X)[:,1]
test_fpr,test_tpr,_ = roc_curve(evl_y, y_pred)
test_ks = abs(test_fpr-test_tpr).max()
test_auc = metrics.auc(test_fpr, test_tpr)
print('test_ks',test_ks)
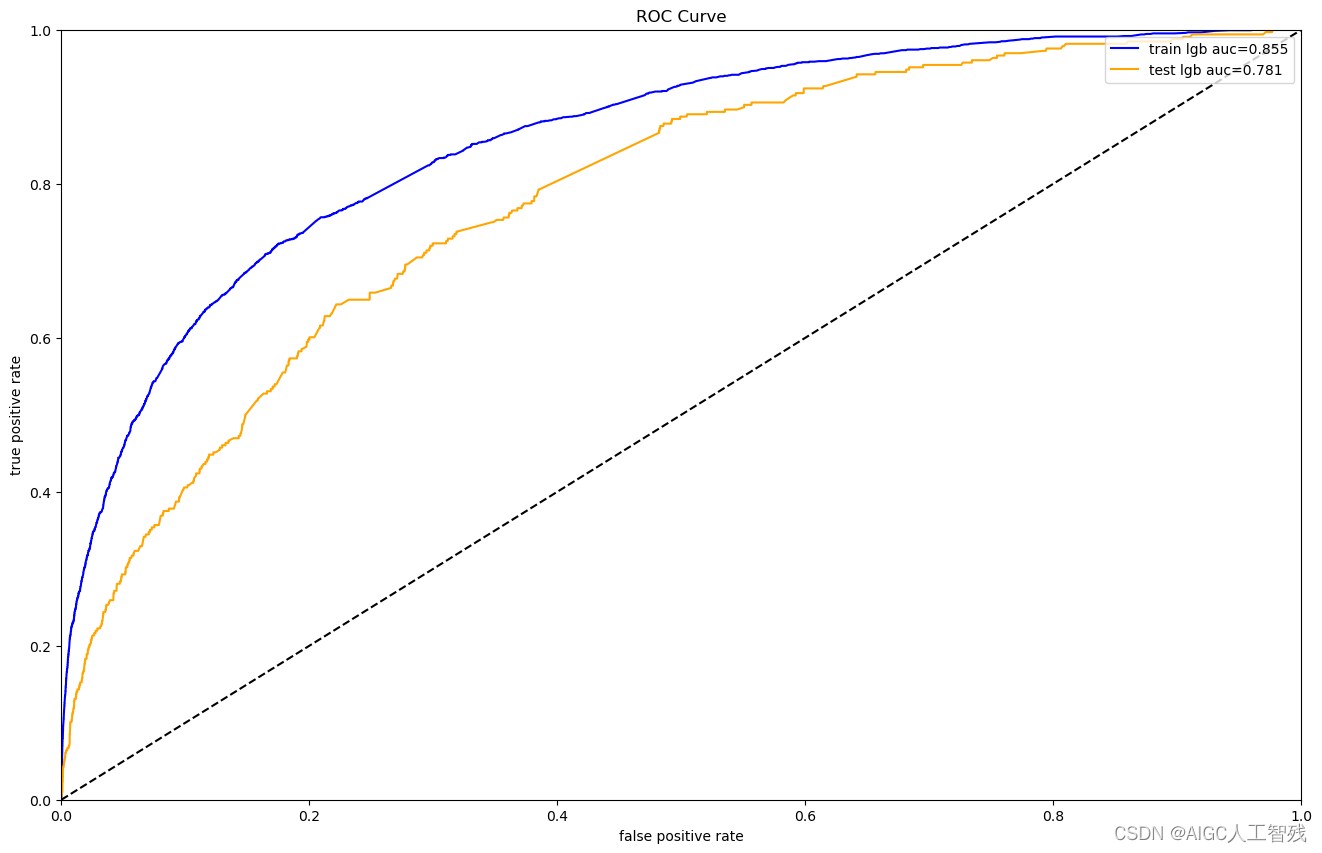
绘制roc曲线
# 绘制roc曲线
plt.figure(figsize=(16,10))
plt.plot(train_fpr, train_tpr,color='blue', label='train lgb auc=%0.3f'%train_auc)
plt.plot(test_fpr,test_tpr,color='orange', label='test lgb auc=%0.3f'%test_auc)
plt.plot([0,1],[0,1],'--', color='black')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,1)
plt.ylim(0,1)
plt.title('ROC Curve')
plt.legend(loc=1)
plt.show()
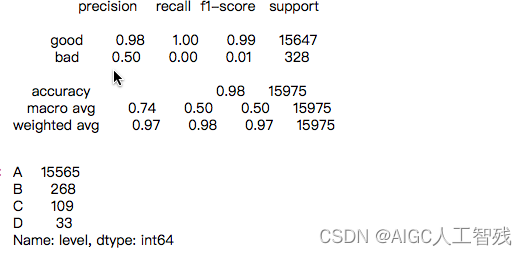
跟评分卡公式对其进行评分并划分等级
# 由于lightgbm没有回归系数,所以我们采用原始的评分卡公式
def score(p):
score = 550+50*math.log2((1-p)/p)
return score
val['p'] = model.predict_proba(evl_X)[:,1]
val['score'] = val.apply(lambda x:score(x.p), axis=1)
print(classification_report(evl_y,model.predict(evl_X), target_names=['good','bad']))
# 根据评分进行分级
def level(score):
level = ''
if score <= 600:
level = "D"
elif score <= 640 and score > 600 :
level = "C"
elif score <= 680 and score > 640:
level = "B"
elif score > 680 :
level = "A"
return level
val['level'] = val.apply(lambda x:level(x.score), axis=1)
val.level.value_counts()
验证ks
# 验证ks
fpr,tpr,_ = roc_curve(evl_y, val['score'])
ks = abs(fpr-tpr).max()
print(ks)
0.42314255674351975
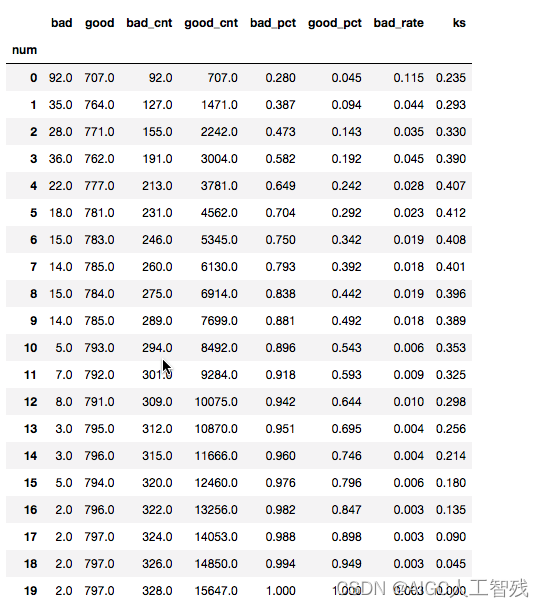
# 生成报告
temp = pd.DataFrame()
temp['bad_rate_pred'] = val['p']
temp['real_bad'] = evl_y
temp.sort_values('bad_rate_pred', inplace=True, ascending=False)
temp['num'] = [i for i in range(temp.shape[0])]
temp['num'] = pd.cut(temp.num, bins=20, labels=[i for i in range(20)])
report = pd.DataFrame()
report['bad'] = temp.groupby('num').real_bad.sum()
report['good'] = temp.groupby('num').real_bad.count()-report['bad']
report['bad_cnt'] = report['bad'].cumsum()
report['good_cnt'] = report['good'].cumsum()
good_total = report['good_cnt'].max()
bad_total = report['bad_cnt'].max()
report['bad_pct'] = round(report['bad_cnt']/bad_total,3)
report['good_pct'] = round(report['good_cnt']/good_total,3)
report['bad_rate'] = report.apply(lambda x:round(x.bad/(x.good+x.bad), 3), axis=1)
def cal_ks(x):
ks = x.bad_pct - x.good_pct
return round(math.fabs(ks),3)
report['ks'] = report.apply(cal_ks, axis=1)
report
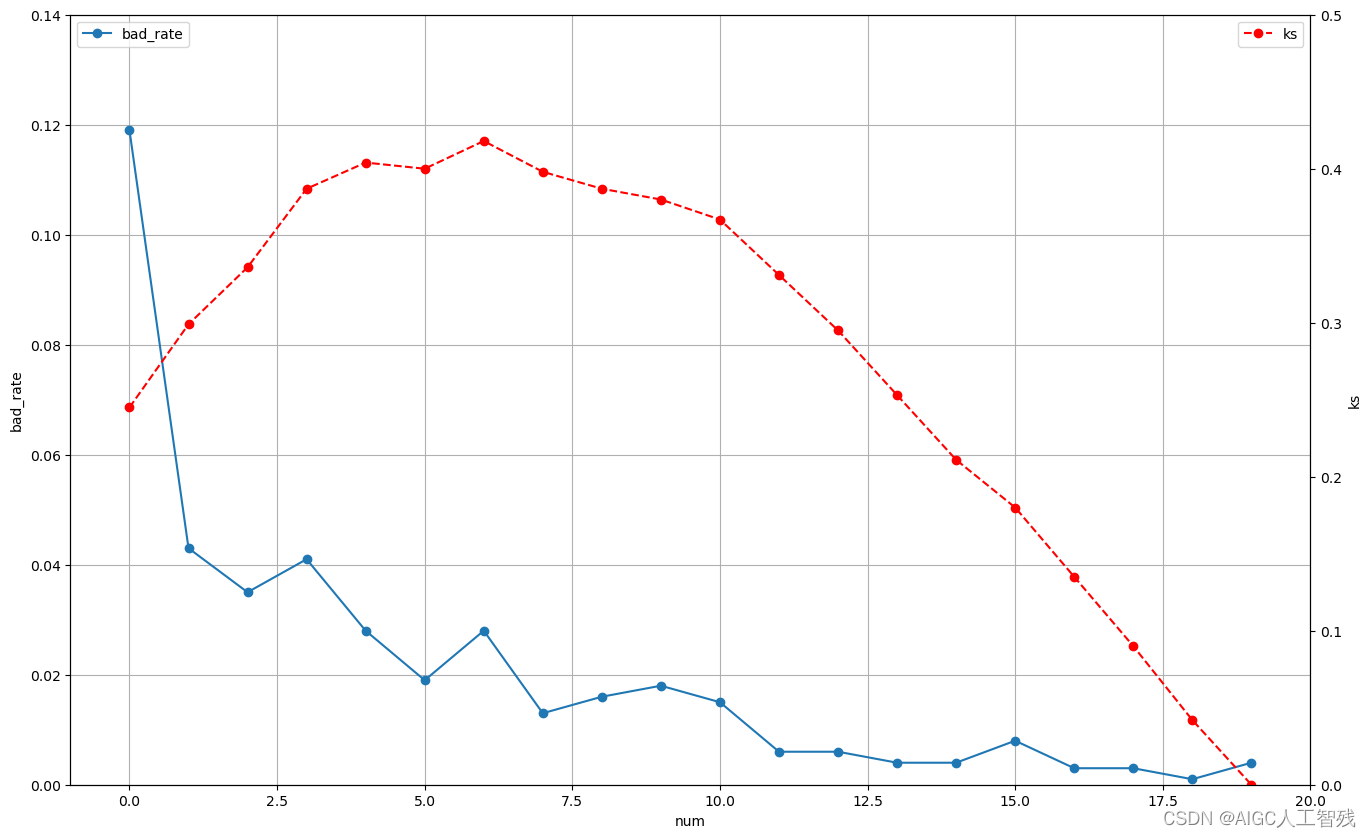
绘制bad_rate和ks折线图
# 绘制bad_rate和KS的折线图
fig = plt.figure(figsize=(16,10))
ax = fig.add_subplot(111)
ax.plot(range(20), report['bad_rate'],'-o',label='bad_rate')
ax2 = ax.twinx()
ax2.plot(range(20), report['ks'],'--o',color='r',label='ks')
ax.grid()
ax.set_xlim(-1,20)
ax.set_ylim(0,0.14)
ax2.set_ylim(0,0.5)
ax.set_ylabel('bad_rate')
ax2.set_ylabel('ks')
ax.set_xlabel('num')
ax.legend(loc=2)
ax2.legend(loc=0)
















 1933
1933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











