






文章目录
李宏毅机器学习第十四周Transformer
摘要
本文首先针对上周学习的GCN中的数学知识——傅里叶变换,进行了较为细致的学习。然后,本文简单介绍了transformer模型,transformer框架是一种可用于多种用途的神经网络模型,可以分为两个部分encoder、decoder。经典的transformer模型采用了交叉注意力机制、masked multi-head self-attention等技术在多种任务上取得了较好的效果。transformer模型可以进一步的由guided attention, beam search等多种方法进行优化。之后,为了进一步的了解transformer模型,阅读了题为Image De-Raining Transformer的论文,其主要提出用于图像除雨任务的模型IDT。该模型中建立了分层encoder-decoder去雨结构。此外,为了提取局部和非局部信息,提出了互补的基于窗口的transformer模块与空域transformer模块。其还提出了相关位置增强多头注意力机制,对位置信息单独建模。最后本文完成了HW4,介绍了各种标准下的关键修改并给出相关代码,主要完成了strong baseline的代码运行
Abstract
This article first introduces the Fourier transform in detail for the mathematical knowledge in GCN learned last week. Then this article briefly introduces the transformer architecture. The transformer framework is a neural network model that can be used for a variety of purposes, which can be divided into two parts: encoder and decoder. The classic transformer model adopts cross-attention mechanism, masked multi-head self-attention and other techniques to achieve good results on a variety of tasks. The transformer model can be further optimized by guided attention, beam search and other methods. After that, in order to further understand the transformer model, read the paper entitled Image De-Raining Transformer, which mainly proposes a model IDT for image de-rain tasks. A hierarchical encoder-decoder rain removal structure is established in this model. In addition, in order to extract local and non-local information, this paper proposes the complementary window-based transformer module and the spatial transformer module. It also proposes a mechanism of relative position enhancement multi-head attention, and this mechanism can model position information separately. Finally, this article completes HW4, introduces the key modifications under various standards and gives related code, and mainly completes the code operation of strong baseline.
零、数学基础——傅里叶变换

一、李宏毅机器学习Transformer
1. seq2seq模型的应用
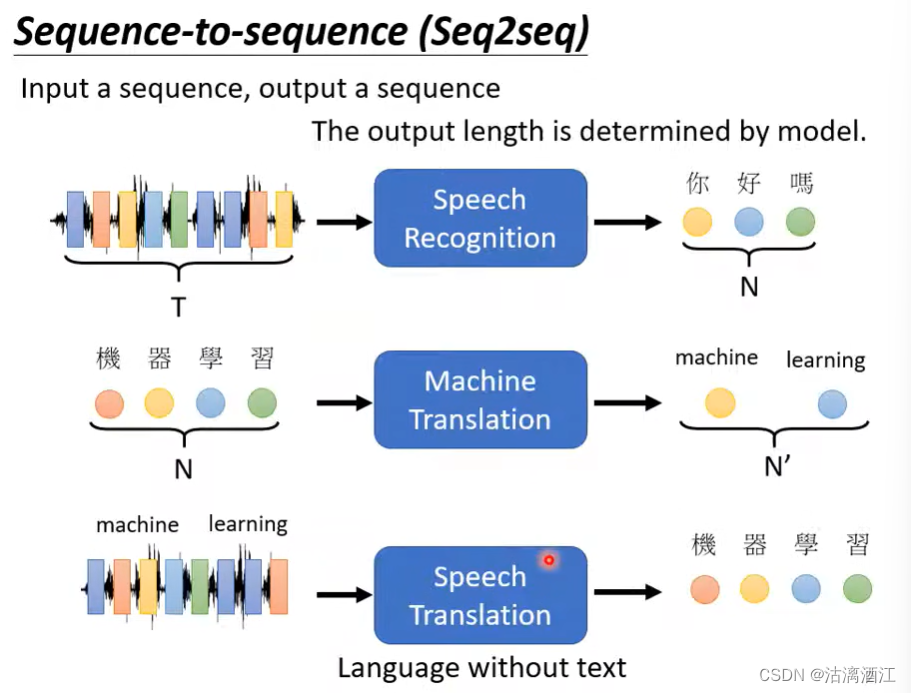
Seq2seq:Input a sequence, output a sequence
语音辨识:声音讯号 → \rightarrow →中文字段
机器翻译:中文字段 → \rightarrow →英文字段
语音翻译:外文声音讯号 → \rightarrow →中文字段,数据集:local soap operas
上述过程是可以实现的,下面是一个从台语声音讯号向中文文字转换的实验结果,除了在部分复杂情况(如倒装)不太准确以外,在较为简单的部分可以达到较好的效果

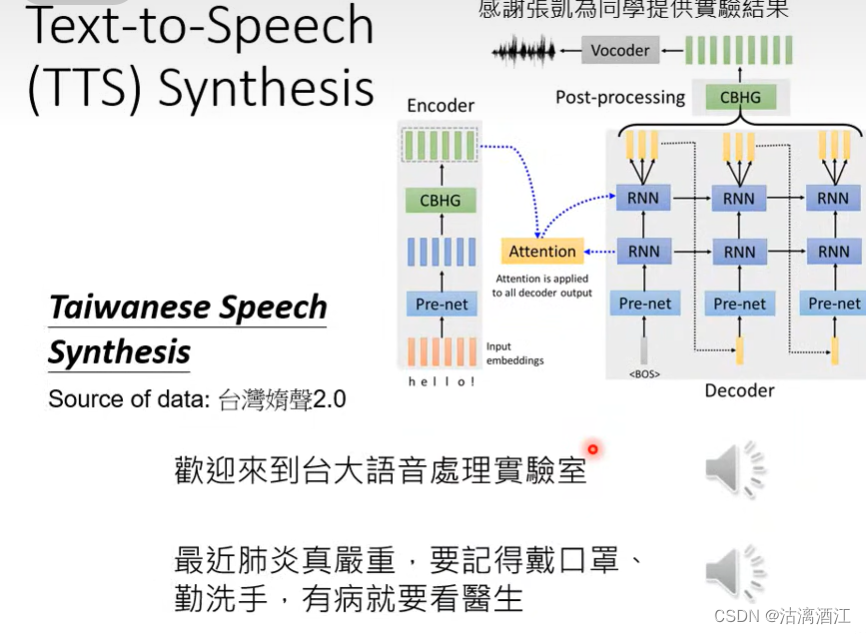
相应的若将上述过程逆置,即做一个从中文文字向台语声音讯号的转换也是可行的,下图为实验结果
同样的也可以将seq2seq的模型应用于对话机器人,输入为一段文字,输出为一段文字
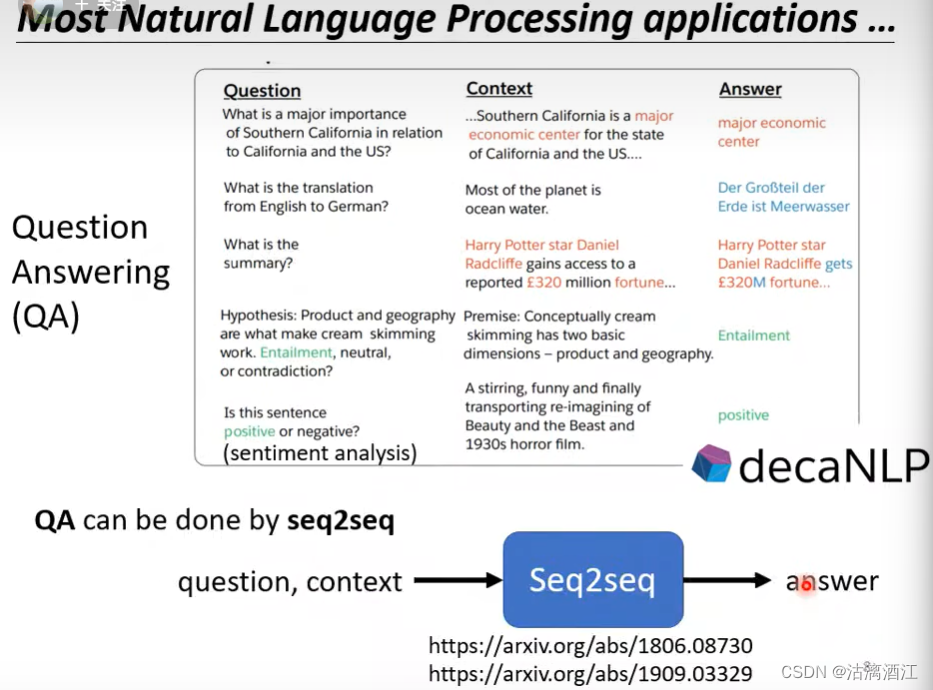
seq2seq在NLP领域应用较为广泛,可以将大部分任务看作QA,例如摘要、翻译、情绪分析等
但对大部分NLP任务而言,针对任务客制化模型会得到更好的结果
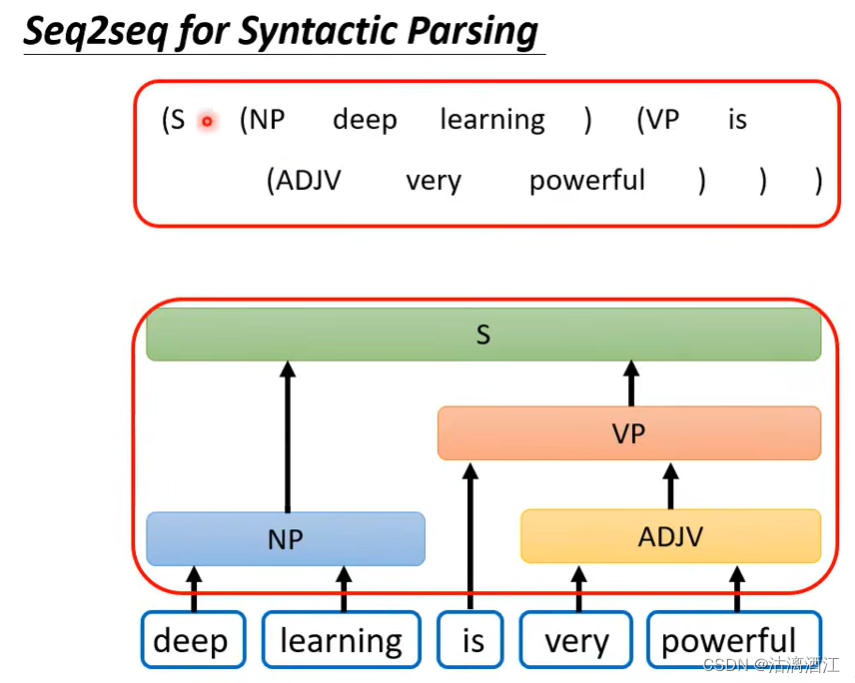
对于语法解析任务,其输出为语法树,尽管这并不是序列输出。但可以将其数据结构进行一定的调整,调整后形式即为下图最上面的文段,从而将语法解析任务转换为seq2seq的任务。Grammer as a Foreign Language
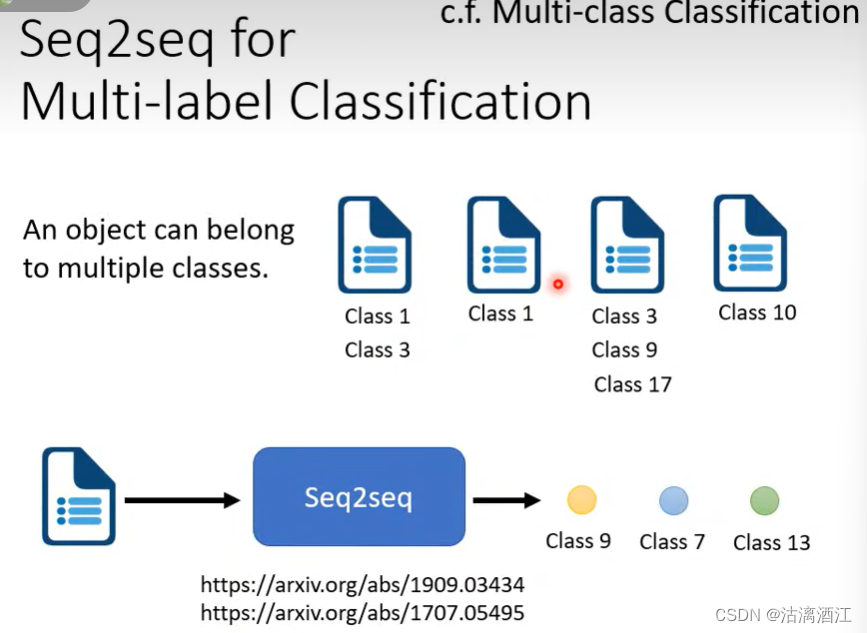
多标签分类任务也可以用seq2seq模型处理,例如论文的关键词
注:该任务与下图右上角的多类别分类不同,可以将多类别分类理解为single-label multi-class classificaiton
物体检测也可以使用seq2seq模型解决,本文不再阐述细节,相关内容参照下图中给出的文献
上文中给出了使用该类模型可以完成的任务,可以看出其强大之处,以下简单解释这类模型的大致框架
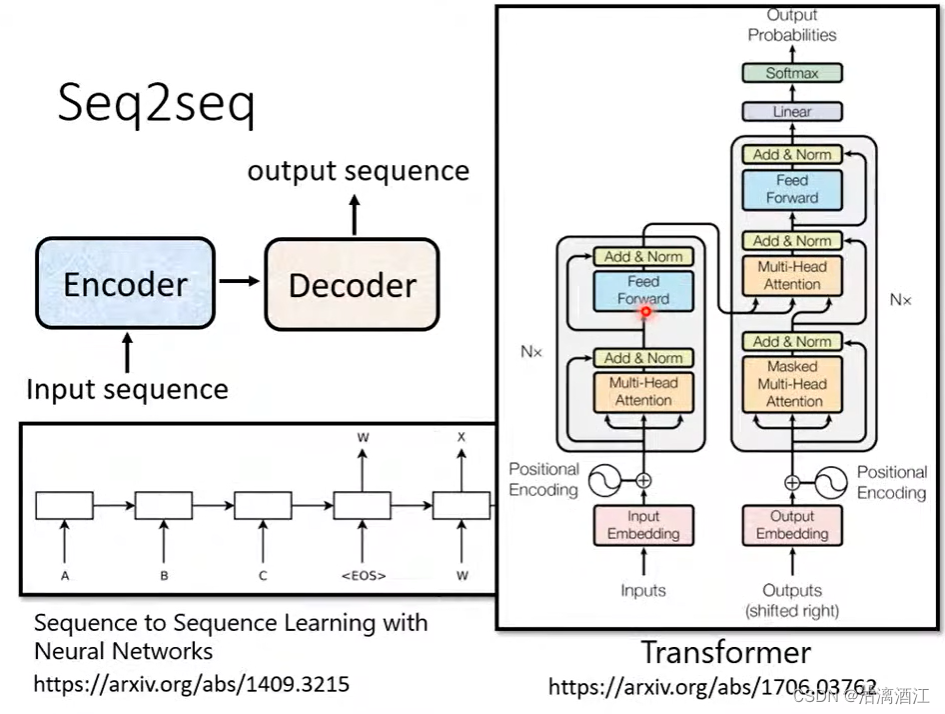
2. framework of seq2seq model
该模型输入输出均为一个序列,而其内部可以大致分为encoder编码器、decoder解码器
这种结构的模型最初由下图左下角的文章提出,而右下角则将这类模型发扬光大
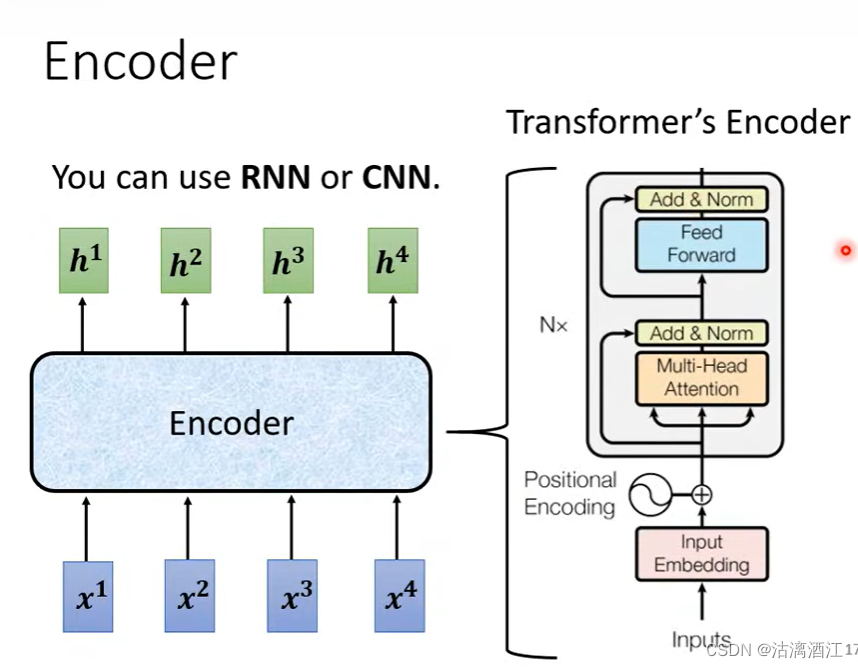
2.1 encoder
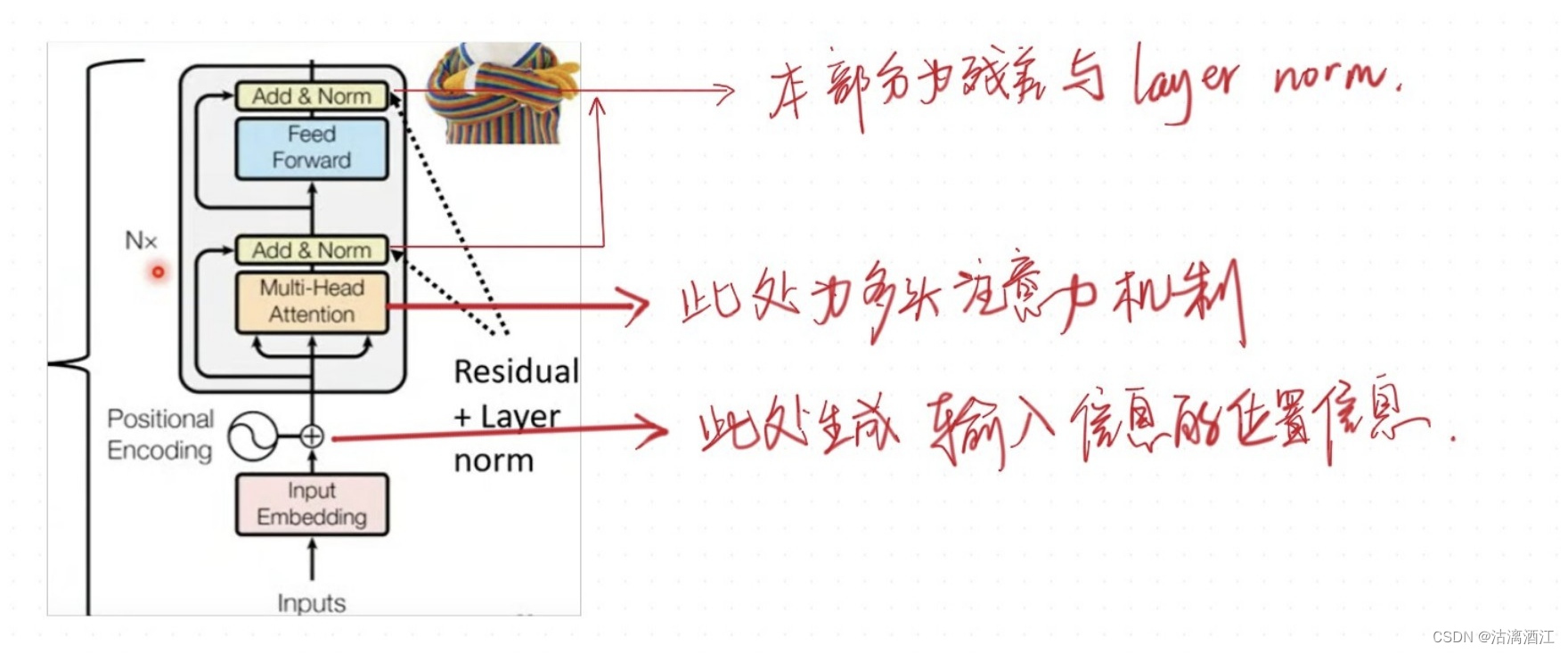
首先从编码器部分开始,其大致结构如下图左下角,输入输出均为一个向量组。这类任务可以使用self-attention、RNN或CNN完成,而transformer选用的是self-attention。下图右半边给出了transformer编码器的框架,以下针对这一部分进行更细的解释
encoder中间由多个block构成,而单个block由多层layer构成,其输入输出也是向量组,大致结构如下
v e c t o r − s e q → s e l f − a t t e n t i o n → f u l l y c o n n e c t i o n → v e c t o r − s e q vector-seq\rightarrow self-attention\rightarrow fully\ connection\rightarrow vector-seq vector−seq→self−attention→fully connection→vector−seq
transformer会将经过self-attention处理的数据a与未经处理的数据b相加,即residual残差,之后进行layer norm。而在fully connection部分同样的对结果作残差后标准化。
残差的基本思路:经过网络处理的数据的表达效果并不一定是提高的,因此将该部分数据与未经处理的数据相加后标准化,该操作可以一定程度上回滚神经网络,从而避免效果变得过差
layer norm:首先计算向量中各元素组成的正态分布的均值m与标准差 σ \sigma σ(各元素并不一定来自同一正态分布),然后进行标准化操作 x i ′ = x i − m σ \displaystyle x'_i=\frac{x_i-m}\sigma xi′=σxi−m。详细内容参照下图中文献
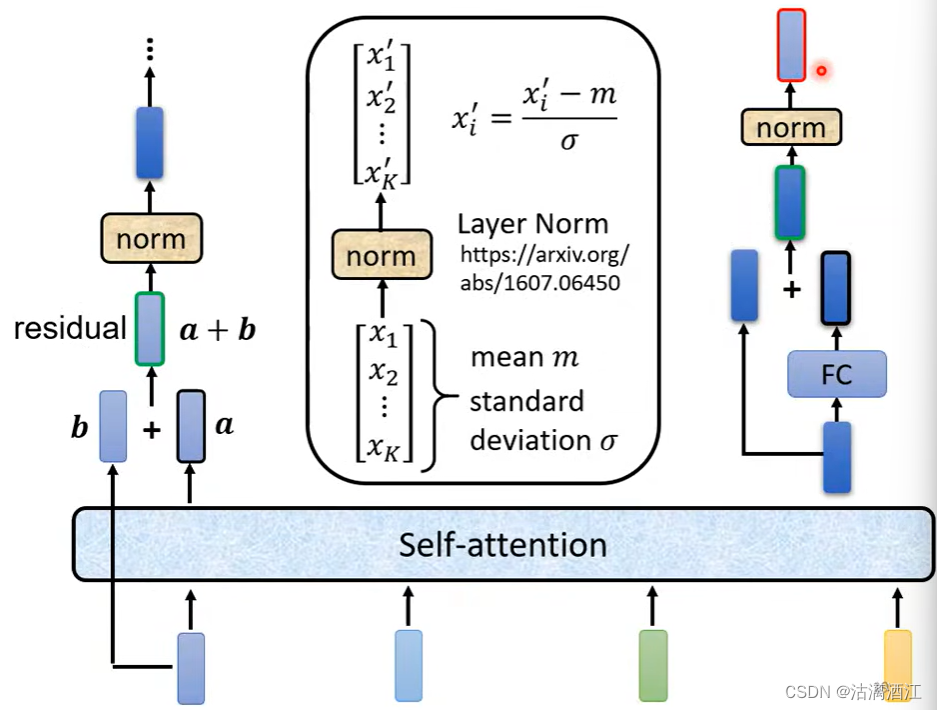
在进行了上述讲解之后,可以看出transformer encoder所进行的操作大致如下,其中蓝色方框为feed forward,其操作为两次线性变换,第一次线性变换从低维到高维,第二次将高维信息还原至低维,公式如下:其中max相当于ReLU
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
feed forward的作用可以理解为通过线性变换,先将数据映射到高纬度空间,在映射到低纬度空间从而提取更深层次的特征
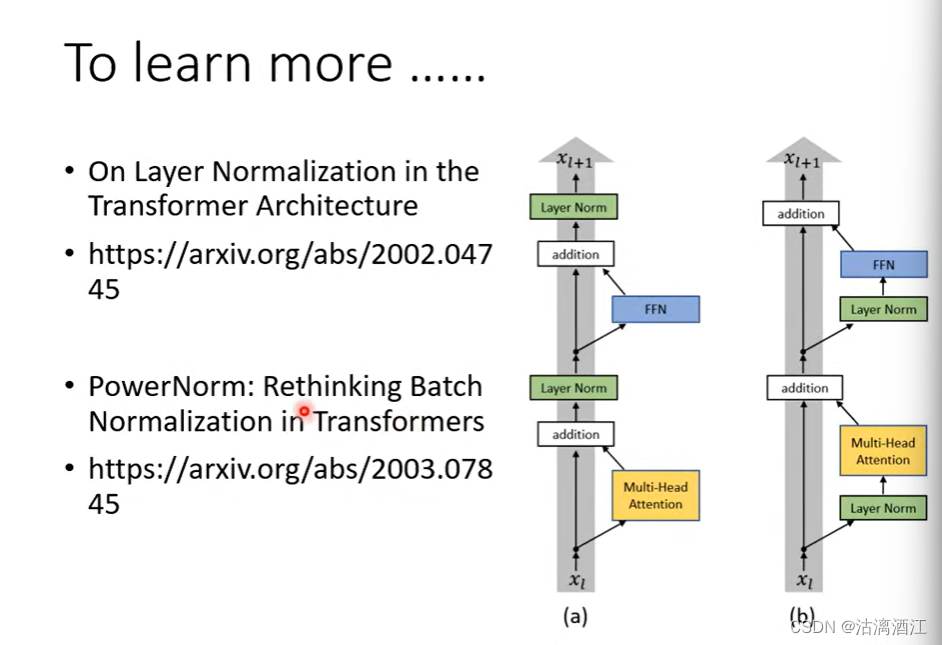
上述介绍了encoder结构是基于transformer模型,除此之外也有很多优秀的模型在该部分做了其他的操作。下图中左侧为transformer的结构,而右侧为针对其进行的改进。更多的细节参照下文中第一篇文献。而下图中第二篇文献,首先解释了为什么layer norm在transformer中优于batch norm,并在此基础上提出了新的归一化方法power norm
2.2 decoder
数据在经过encoder处理后输入decoder,而autogressive decoder则是一种较为常见的encoder。
encoder需要做的工作是解析encoder生成的vector sequence,从而生成输出。
除了向量组输入decoder以外,在起始时刻还需要输入begin of sentence(可以看作代表起始的标识符),这是一个特殊的token。而decoder在读取标识符后,会生成一个经过softmax处理的one-hat vector,即可以看作每个可能输出的概率分布,其中最高的就是输出。
每次的输出结果会作为下一次的token,然后由decoder进行处理,重复上述过程。就像在RNN中做的那样,可以将上次的输出看作本次的memory。
但相应的由于上述过程是迭代进行的,decoder应该对于错误的输出具有一定的纠错能力,从而提高模型的稳定性,尽量避免一步错步步错。即error propagation的问题。该部分将在本文后续内容中讲解

下面简单的介绍decoder内部的结构
相较于encoder,decoder主要区别在于多了n层的multi-head attention与Add&Norm。而其首个multi-head attention layer是带有mask的,而该层的差异在于其在处理时仅考虑在其前面(即已经阅读部分)数据及其本身。以下简单解释masked self-attention

从数据处理过程来理解上述过程,如下图,在生成 b 2 b^2 b2时,仅使用第二个位置的query矩阵,与第一个、第二个位置的key矩阵计算其注意力,而不处理后续第三第四位置的数据。
采用这种处理方法的原因是在顺序阅读过程中不可能直接看到全文的内容。即本次输出的生成应当基于前面位置输出
在上述过程中,并没有给出结束生成过程的方法,这会导致序列会一直生成下去。正如起始标识符那样,可以在分布中添加终止标识符stop token,在机器输出该标识符后会终止序列生成过程。

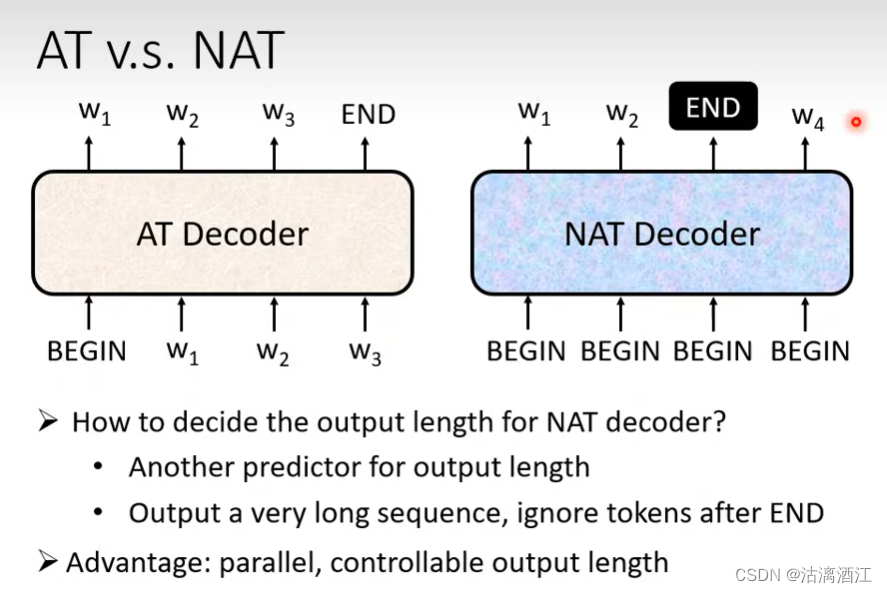
decoder-non-autoregressive(NAT)
AT,即上述内容的decoder,是根据token顺序的生成输出。而NAT decoder则是直接生成所有输出。
而NAT控制序列长度的方式有两种,一种是另外构造一个用于预测长度的预测器,另一种是输出一个非常长的序列,其中输出分布中包含end token。其优点为并行化、输出长度可控。尽管nat decoder有诸多优点,但其表现往往不如at decoder
cross attention
了解了nat之后,将注意力转回刚才decoder中被遮住的那部分网络,其被称作cross attention,下面解释该部分的操作
首先由encoder生成key矩阵和value矩阵,而decoder中的masked self-attention生成query矩阵。然后根据attention机制生成注意力向量,注意力向量与value矩阵叉乘,根据weight sum得到结果向量v。这个过程即cross attention。而其结果将输入fully connection

下图将cross attention的过程可视化,其中注意力越强的位置颜色越深,由此可以看出注意力随着迭代增加逐渐从起始位置向末尾移动。
 Training
Training
训练使用的数据集是由声音讯号及其标签组成的,而误差则是该位预测向量与该位的实际标签的one-hat vector的cross entropy,训练的目标是将所有cross entropy的总和尽可能的minimize。除此外,末尾需要输出end token。
也可以用teacher forcing,将decoder的输入替换为真实值

3. More Tips
3.1 copy mechanism
可以使用chat-bot,其作用是将文字中可能需要在回答中使用的陌生字段,直接复制到回答中的适当位置。在这个过程中模型学到的信息是复制的操作而非复制的内容。该方法可以用于summarization任务
3.2 guided attention
有monotonic attention、localtion-aware attention等方法,通常应用于单调排列的任务
对于这种任务一般希望注意力能够从左到右依次的移动,但实际上可能如下图中那样没有按照序列顺序进行,此时应用上述方法

3.3 beam search
对于下图中的二叉树,需要搜索其中期望最高的路径。若采用贪婪算法,则声称下图中红色路径,其在局部最优、但不一定全局最优,而beam search的算法思路是以尽可能逼近全局最优的路径行进,即对于第一个选择,其可能选择B。
但上述内容并不绝对,对于decoder,在生成过程中通常一定的随机性

3.4 Reinforcement learning
在decoder部分,是根据单个标签的预测值与实际值之间的交叉熵计算损失,但由于整个序列是相关的,因此可能在计算时考虑整个序列能够得到更好的结果。然而此时并不一定有较为合适的损失函数,对于这种情况可以选择将损失函数看作强化学习(Reinforcement learning)问题,直接使用该类模型进行训练。

3.5 scheduled sampling
由于训练过程中直接给出了正确的输入,而测试过程中decoder生成的并不一定是正确的输出,此时出现了exposure bias的问题。对于这种问题可以使用scheduled sampling进行解决。简单来说,这个方法在训练过程中会给decoder一些错误的输入,从而提高模型的稳定性。但在transformer中直接使用该方法并不一定能得出较好的结果,因此多位学者对该领域进行了一定的研究。在下图中给出了多个文献,包括了该方法的原始文献与在transformer模型的基础上对该方法进行改进的文献。

二、文献阅读
1. 题目
题目:Image De-Raining Transformer
作者:J. Xiao, X. Fu, A. Liu, F. Wu and Z. -J. Zha
期刊:IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 12978-12995, 1 Nov. 2023
2. abstract
该论文提出了一种有效且高效的基于transformer的图像去雨架构。首先,在网络架构中引入了视觉任务的一般先验,即局部性和层次性,这样该模型就可以在不进行昂贵的预训练的情况下实现出色的去训练性能。其次,设计了互补的基于窗口的变换器和空间变换器,以增强局部性,同时捕获长程依赖关系。此外,为了弥补自注意的位置盲性,作者建立了一个单独的代表空间来建模位置关系,并设计了一个新的相对位置增强的多头自注意。
This paper mainly propose an effective and efficient transformer-based architecture for the image de-raining. First, general priors of vision tasks have been introduced, i.e., locality and hierarchy, into the network architecture so that the model can achieve excellent de-raining performance without costly pre-training. Secondly, the complementary window-based transformer and spatial transformer has been designed to enhance locality while capturing long-range dependencies. Besides, to compensate for the positional blindness of self-attention, authors establish a separate representative space for modeling positional relationship, and design a new relative position enhanced multi-head self-attention.
3. 网络架构
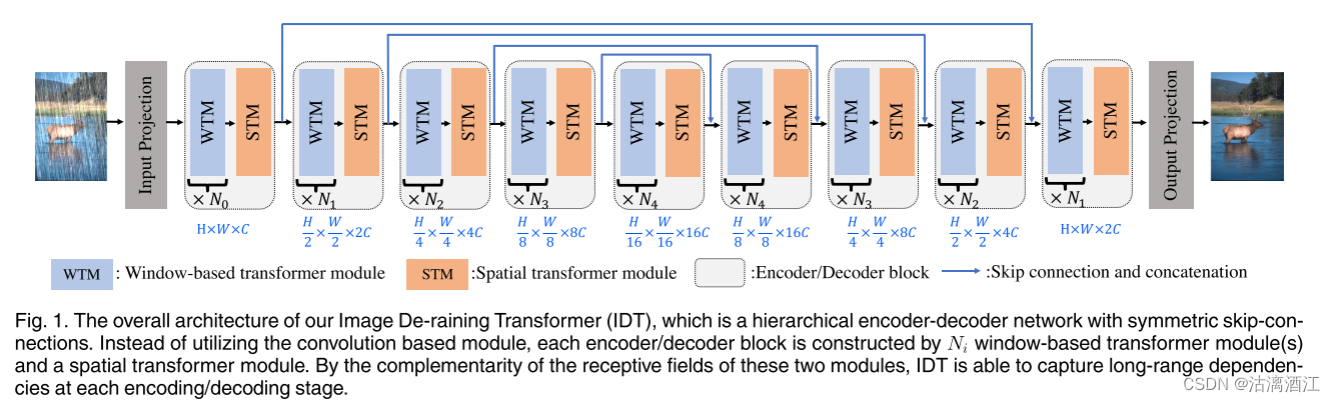
IDT整体架构如上图所示,是一个具有长程跳跃连接的对称分层编码器-解码器网络。首先,输入映射器将输入图像转换为嵌入,输入映射器由标准
3
×
3
3\times3
3×3卷积层和后面的非线性激活函数组成。然后,投影的特征被馈送到网络主干,该主干由编码器/解码器块的顺序堆叠构成。每个编码器/解码器块以一定的空间分辨率运行。对于编码阶段,空间分辨率逐渐减小2,而通道维度则扩大相同倍,而对于解码阶段,则相反。每个编码器/解码器块是由Ni个基于窗口的Transformer模块和空间Transformer模块构成。最后,由输出映射器将特征映射至原始尺寸,输出映射器包括标准的
3
×
3
3\times3
3×3卷积层。
3.1 Relative Position Enhanced Multi-Head Self-Attention
首先重新表述图像的多头自注意力,然后详细阐述所提出的相对位置增强多头自注意力(REMSA)。
对于图像数据,标记排列在2D平面而不是1D序列中。令 X ∈ R H × W × D x X\in R^{H\times W\times D_x} X∈RH×W×Dx 为由每个具有 D x D_x Dx维度的$ H\times W $标记组成的输入张量。为了保持符号整洁,
引入了一个2D索引向量: i f t = ( i , j ) , t h e n X t ⇔ X i , j if\ t=(i,j),\ then\ X_t \Leftrightarrow\ X_{i,j} if t=(i,j), then Xt⇔ Xi,j。
自注意力层将X映射到新的2Dtoken平面
Z
∈
R
H
×
W
×
D
z
Z\in R^{H\times W\times D_z}
Z∈RH×W×Dz
Z
t
,
:
=
∑
k
∈
G
softmax
(
A
)
t
,
k
(
X
W
v
)
k
.
:
Z_{t,:}=\sum_{k\in G}\text{softmax}(A)_{t,k}(XW_v)_{k.:}
Zt,:=k∈G∑softmax(A)t,k(XWv)k.:
其中G表示全局空间:
[
1
,
…
,
H
]
×
[
1
,
…
,
W
]
1
[1,\dots,H]\times[1,\dots,W]^1
[1,…,H]×[1,…,W]1表示任意索引,
即 a : = b : ⇔ a i = b i a_:=b_:\Leftrightarrow a_i=b_i a:=b:⇔ai=bi , 对于任意合法索引 i 成立。
张量A测量参与标记之间的兼容性,通常通过缩放点积函数计算:
A
=
X
W
Q
(
X
W
K
)
T
D
k
A=\frac{XW_Q(XW_K)^T}{\sqrt{D_k}}
A=DkXWQ(XWK)T
W
Q
,
W
K
∈
R
D
x
×
D
k
a
n
d
W
V
∈
R
D
x
×
D
z
W_Q, W_K\in R^{D_x\times D_k}\ and\ W_V \in R^{D_x\times D_z}
WQ,WK∈RDx×Dk and WV∈RDx×Dz是线性投影的参数矩阵。
将自注意力以多头版本实现,该版本下联合注意力来自不同位置的不同表示子空间的信息:
Z
=
Concat
h
∈
[
1
,
…
,
N
h
]
[
softmax
(
A
h
)
(
X
W
V
h
)
]
W
O
Z=\text{Concat}_{h\in[1,\dots,N_h]}[\text{softmax}(A^h)(XW_V^h)]W_O
Z=Concath∈[1,…,Nh][softmax(Ah)(XWVh)]WO
其中
N
h
N_h
Nh是头数,
W
O
W_O
WO是线性变换的参数矩阵
A
h
A_h
Ah表示头h的兼容性张量,其形式为
A
h
=
X
W
Q
h
(
X
W
K
h
)
D
k
A^h=\frac{XW_Q^h(XW_K^h)}{\sqrt{D_k}}
Ah=DkXWQh(XWKh)
其中
W
Q
h
,
W
K
h
∈
R
D
x
×
D
k
a
n
d
W
V
h
∈
R
D
x
×
D
z
W^h_Q,\ W^h_K \in R^{D_x\times D_k}\ and\ W^h_V \in R^{D_x\times D_z}
WQh, WKh∈RDx×Dk and WVh∈RDx×Dz 是头 h 的参数矩阵。
对于多头自注意力,经常设置 W V ∈ R D x × D z N h a n d W O ∈ R D z × D z W_V\in R^{D_x\times\frac{D_z }{N_h}}\ and\ W_O\in R^{D_z\times D_z} WV∈RDx×NhDz and WO∈RDz×Dz
上述即为多头自注意力机制的运行逻辑。
Swin Transformer通过将相对位置偏差引入兼容性张量A来解决位置不可知的问题:
Z
t
,
:
=
∑
k
∈
G
softmax
(
A
+
B
)
t
,
k
(
X
W
V
)
k
,
:
Z_{t,:}=\sum_{k\in G}\text{softmax}(A+B)_{t,k}(XW_V)_{k,:}
Zt,:=k∈G∑softmax(A+B)t,k(XWV)k,:
其中
B
∈
R
H
×
W
×
H
×
W
B \in R^{H\times W\times H\times W}
B∈RH×W×H×W是相对偏差张量,按查询和键的位置进行索引,即
(
query
x
,
query
y
,
key
x
,
key
y
)
(\text{query}_x,\text{query}_y,\text{key}_x,\text{key}_y)
(queryx,queryy,keyx,keyy)。
由于沿每个轴的相对位置分别位于 [ − H + 1 , H − 1 ] a n d [ − W + 1 , W − 1 ] [-H+1,H-1]\ and\ [-W+ 1,W-1] [−H+1,H−1] and [−W+1,W−1]范围内,因此较小尺寸的偏置矩阵 B ^ ∈ R ( 2 H − 1 ) × ( 2 W − 1 ) \hat B\in R^{(2H-1)\times (2W-1)} B^∈R(2H−1)×(2W−1) 被参数化,并且B中的值取自 B ^ \hat B B^ 。
为位置建模建立了一个单独的值表示,并提出了相对位置增强多头自注意力(REMSA)。 REMSA的数学公式为:
Z
t
,
:
=
∑
k
∈
G
softmax
(
A
+
B
)
t
,
k
(
X
W
V
)
k
,
:
+
∑
k
∈
G
w
t
−
k
⊙
(
X
W
P
)
k
,
:
Z_{t,:}=\sum_{k\in G}\text{softmax}(A+B)_{t,k}(XW_V)_{k,:}+\sum_{k\in G}w_{t-k}\odot(XW_P)_{k,:}
Zt,:=k∈G∑softmax(A+B)t,k(XWV)k,:+k∈G∑wt−k⊙(XWP)k,:
其中
W
P
∈
R
D
x
×
D
z
W_P \in R^{D_x\times D_z}
WP∈RDx×Dz 是参数矩阵,旨在将X转换为新的表示形式,该形式以相对位置混合信息
w t − k w_{t-k} wt−k是索引为 t − k t-k t−k的相对位置的权重张量。保留了等式中的相对位置偏差B。 赋予模型更多的灵活性,因为当模型调整参数使得 B = 0 B = 0 B=0 时,它会降级为传统的基于内容的注意力。
为了增强模型泛化性并简化实现,沿每个轴剪切到
σ
∈
N
\sigma\in N
σ∈N的最大绝对距离,即对于
w
t
−
k
w_{t-k}
wt−k,将索引
t
−
k
t-k
t−k限制在
[
−
σ
,
…
,
σ
]
×
[
−
σ
,
…
,
σ
]
[-\sigma,\dots,\sigma]\times[-\sigma,\dots,\sigma]
[−σ,…,σ]×[−σ,…,σ]由
N
(
σ
)
N(\sigma)
N(σ)定义。然后,上式可以重新表述为
Z
t
,
:
=
∑
k
∈
G
softmax
(
A
+
B
)
t
,
k
(
X
W
V
)
k
,
:
+
∑
k
∈
N
(
σ
)
w
k
⊙
(
X
W
P
)
t
+
k
,
:
Z_{t,:}=\sum_{k\in G}\text{softmax}(A+B)_{t,k}(XW_V)_{k,:}+\sum_{k\in N(\sigma)}w_{k}\odot(XW_P)_{t+k,:}
Zt,:=k∈G∑softmax(A+B)t,k(XWV)k,:+k∈N(σ)∑wk⊙(XWP)t+k,:
通过对最大绝对距离的裁剪,可以算出等式右边的第二项对应于内核大小
(
2
σ
+
1
)
×
(
2
σ
+
1
)
(2\sigma+1)\times (2\sigma+1)
(2σ+1)×(2σ+1)的基于标记的卷积。因此,它可以在当前的深度学习加速器上高效实现。
为了节省计算和内存,将卷积分解为深度卷积以收集token之间的空间信息,然后进行token线性投影,其目的是交换token内部的信息。

上图展示了REMSA的详细计算图。新颖的自注意力机制可以轻松扩展到多头版本:对每个头并行执行上述自注意力,连接输出,最后通过线性变换映射出综合结果
3.2 Window-Based Transformer Module
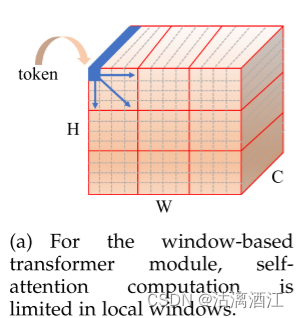
上图中token由灰色虚线划分,自注意力机制在红色实现划分的窗口内执行。基于窗口的Transformer模块旨在捕获局部窗口内的局部关系。
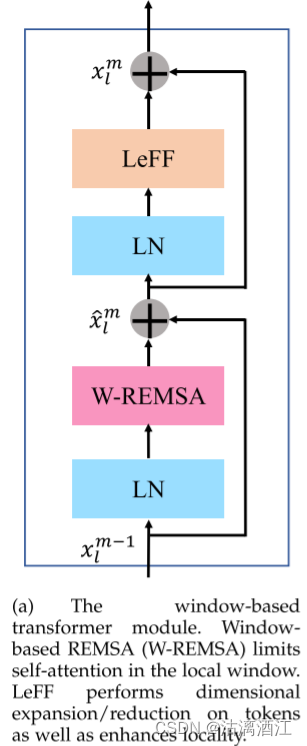
上图给出了基于窗口的Transformer模块的结构。该模块有两个子模块。第一个是基于窗口的相对位置增强型多头自注意力(W-REMSA),其目的是捕获token之间的交互。第二个是局部增强前馈网络(LeFF),其中包含两个逐点多层感知器(MLP)之间的3×3深度卷积。
此外,在自注意力之前采用层标准化,并应用LeFF和残差连接来简化学习。
基于窗口的Transformer模块可以表示为
x
^
l
m
=
x
l
m
−
1
+
W-REMSA
(
LN
(
x
l
m
−
1
)
)
x
l
m
=
x
^
l
m
+
LeFF
(
LN
(
x
^
l
m
)
)
\hat x_l^m=x_l^{m-1}+\text{W-REMSA}(\text{LN}(x_l^{m-1}))\\ x_l^m=\hat x_l^m+\text{LeFF}(\text{LN}(\hat x_l^m))
x^lm=xlm−1+W-REMSA(LN(xlm−1))xlm=x^lm+LeFF(LN(x^lm))
其中$\hat xm_l and xm_l $分别表示块l中第m个基于窗口的Transformer模块的W-REMSA子模块和LeFF子模块的输出特征
3.2.1 W-REMSA
受Swin Tranformer的启发,局部性是通过非重叠窗口实现的。如上图所示,特征图被划分为不重叠的窗口,并且从本地窗口获取的token参与REMSA的计算。
3.2.1 LeFF
令
x
^
l
m
∈
R
H
×
W
×
C
\hat x^m_l\in R^{H\times W\times C}
x^lm∈RH×W×C表示块l中第 m 个基于窗口的 Transformer 模块的LeFF子模块的输入,进行线性映射,然后进行GELU激活 ,以将token的embedding扩展为
z
l
m
∈
R
H
×
W
×
k
C
z^m_l\in R^{H\times W\times kC}
zlm∈RH×W×kC的高维,其中k是扩展比。然后,执行内核大小为
3
×
3
3\times 3
3×3和GELU的深度卷积,输出为
z
^
l
m
∈
R
H
×
W
×
k
C
\hat z^m_l \in R^{H\times W\times kC}
z^lm∈RH×W×kC。最后,将经过映射的token重新映射到
x
l
m
∈
R
H
×
W
×
C
x^m_l \in R^{H\times W\times C}
xlm∈RH×W×C的初始维度。综上所述,LeFF 的上述过程可以表示为
z
l
m
=
GELU
(
MLP
(
x
^
l
m
)
)
z
^
l
m
=
z
l
m
+
GELU
(
DW
−
Conv
(
z
l
m
)
)
x
l
m
=
MLP
(
z
^
l
m
)
z^m_l=\text{GELU}(\text{MLP}(\hat x_l^m))\\ \hat z_l^m=z_l^m+\text{GELU}(\text{DW}-\text{Conv}(z_l^m))\\ x_l^m=\text{MLP}(\hat z_l^m)
zlm=GELU(MLP(x^lm))z^lm=zlm+GELU(DW−Conv(zlm))xlm=MLP(z^lm)
3.3 Spatial TransformerModule
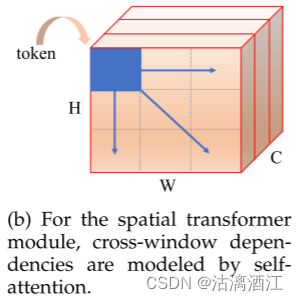
上图显示了空间Transfomer模块,通过建模跨窗口依赖性来补充局部性。
为了节省计算和内存,空间Transfomer模块中的token包含来自同一窗口和同一通道的特征点(上图中的蓝色方块)。空间Transfomer模块中的自注意力是在空间上进行的,因此捕获了局部窗口的空间依赖性(上图中的蓝色箭头)。如下图所示,空间Transfomer模块包括空间REMSA(S-REMSA)和LeFF。 S-REMSA通过实现跨局部窗口的交互来获得非局部感受野。与自注意力正交,LeFF用于沿深度混合特征。与基于窗口Transformer模块类似,采用残差连接和层归一化来简化学习。空间变换器计算为
x
^
l
N
i
=
x
l
N
i
+
S-REMSA
(
LN
(
x
l
N
i
)
)
y
l
=
x
^
l
N
i
+
LeFF
(
LN
(
x
^
l
N
i
)
)
\hat x_l^{N_i}=x_l^{N_i}+\text{S-REMSA}(\text{LN}(x_l^{N_i}))\\ y_l=\hat x_l^{N_i}+\text{LeFF}(\text{LN}(\hat x_l^{N_i}))
x^lNi=xlNi+S-REMSA(LN(xlNi))yl=x^lNi+LeFF(LN(x^lNi))
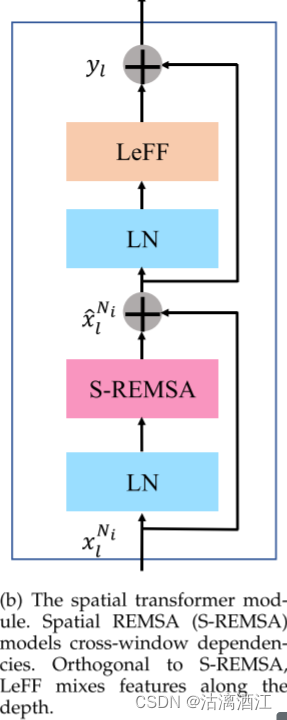
其中 x l N i x^{N_i}_l xlNi表示块l中最后一个基于窗口的Transfomer模块的输出, x ^ l N i \hat x^{N_i}_l x^lNi是S-REMSA子模块的输出, y l y_l yl是块l的最终输出。假设局部窗口大小为 p × p p\times p p×p,token数量为 H p × W p \frac H p\times \frac W p pH×pW,每个令牌的维度为 p × p × C p\times p\times C p×p×C
计算复杂度为 Θ ( H 2 W 2 p 4 × p 2 C ) = Θ ( ( H 2 W 2 C ) p 2 ) \Theta(\frac{H^2W^2}{p^4}\times p^2C)=\Theta(\frac{(H^2W^2C)}{p^2}) Θ(p4H2W2×p2C)=Θ(p2(H2W2C))
空间Transfomer模块的总体复杂性是 Θ ( p 2 H W C + H 2 W 2 C p 2 ) \Theta(p^2HWC+\frac{H^2W^2C}{p^2}) Θ(p2HWC+p2H2W2C)
根据算术和几何平均值不等式, p 2 H W C + H 2 W 2 C p 2 ≥ 2 ( H W ) 3 2 C p^2HWC+\frac{H^2W^2C}{p^2} \geq 2(HW)^\frac32C p2HWC+p2H2W2C≥2(HW)23C,并且如果 p = ( H W ) 1 4 p=(HW)^\frac14 p=(HW)41,则等式成立
总体而言,总计算成本可为 Θ ( ( H W ) 3 2 C ) \Theta((HW)^\frac32C) Θ((HW)23C),与IPT的 Θ ( ( H W ) 3 2 C ) \Theta((HW)^\frac32C) Θ((HW)23C)相比显著降低。
3.4 Loss Function
在这项工作中,为了证明IDT的有效性,控制损失函数并采用单负SSIM损失直接对训练过程进行监督
L
(
B
^
,
B
)
=
−
SSIM
(
B
^
,
B
)
L(\hat B,B)=-\text{SSIM}(\hat B,B)
L(B^,B)=−SSIM(B^,B)
4. 文献解读
4.1 Introduction
卷积架构具有内在的局限性,无法消除复杂和长期的雨化影响。卷积运算将数据本地化,但图像去雨化任务需要从非局部区域提取特征。此外,卷积以内容不可知的方式混合信息,基于相对位置而非特定输入内容。而目前基于transformer进行的研究又受到到局部感受野的限制。此外,对于图像等高度结构化的数据,他们较少关注位置信息,从而导致忽略图像的内在结构。
研究表明需要对大规模数据集进行预训练。同时为了降低预训练成本,需要将视觉任务的共同特性(层次性与局部性)合并到transformer中,并建立分层encoder-decoder去雨化结构。该论文设计了互补的基于窗口的transformer模块与空域transformer模块(the complementary window-based transformer module&spatial transformer module),这能在增强局部性的同时捕获远程依赖信息。文中还设计了REMSA(relative position enhanced multi-head self-attention),从而建立了位置信息的单独表示空间。最终设计出了IDT(Image De-rainingTransformer),该模型可以灵活的考虑位置关系以及输入内容。
4.2 创新点
4.2.1 分层encoder-decoder去雨化结构
文中将视觉任务的共同特性(层次性与局部性)合并到 Transformer 中,以避免昂贵的预训练,并建立分层编码器-解码器去雨架构。
4.2.2 Special Transformer Moudles
降雨影响的空间大小往往存在很大差异。因此,除雨模型必须从局部和非局部区域提取特征。该论文设计了互补的基于窗口的transformer模块与空域transformer模块(the complementary window-based transformer module&spatial transformer module)。具体来说,基于窗口的模块处理局部窗口内的特征,空域模块通过以通道方式建模跨窗口交互来补充局部感受野。
4.2.3 REMSA
此外,作为 Transformer 的关键组成部分,self-attention 擅长捕获复杂的内容依赖关系,同时忽略位置信息。为了弥补位置盲性,进一步设计了REMSA(relative position enhanced multi-head self-attention),它为位置建模建立了单独的表示空间,位置建模可以补充和增强自注意力
4.2.4 IDT
采用跳跃连接方案来桥接具有相同分辨率的编码器块和相应的解码器块,以消除内容信息丢失。
编码器/解码器模块由 N i ∈ [ 0 , 1 , 2 , 3 , 4 ] N_{i\in[0,1,2,3,4]} Ni∈[0,1,2,3,4] 个级联的基于窗口的Transformer模块和空间Transformer模块组成。基于窗口的Transformer模块旨在捕获局部窗口内的局部关系,而空间Transformer模块通过建模跨窗口依赖性来补充局部性。因此,IDT 可以增强局部性并在每个编码/解码阶段获得全局感受野。
4.3 实验过程
4.3.1 参数设置
在我们的默认设置中, N 0 ; N 1 ; N 2 ; N 3 ; N 4 N_0;N_1;N_2;N_3;N_4 N0;N1;N2;N3;N4 设置为 ( 3 , 3 , 2 , 2 , 1 ) (3,3,2,2,1) (3,3,2,2,1),9个块的头数设置为 ( 1 , 2 , 4 , 8 , 16 , 16 , 8 , 4 , 2 ) (1,2,4,8,16,16,8,4,2) (1,2,4,8,16,16,8,4,2),初始通道C为32,扩展比设置为4。采用Adam优化器,批量大小为8。训练图像被随机裁剪成 128 × 128 128\times 128 128×128块。在训练期间,随机应用水平和垂直翻转以进行数据增强。学习率固定为 1 × 1 0 − 4 1\times 10^{-4} 1×10−4,并在 4 × 1 0 − 5 4\times 10^{-5} 4×10−5次迭代时降至 1 × 1 0 − 5 1\times 10^{-5} 1×10−5。训练我们的网络大约需要 5 × 1 0 5 5\times 10^{5} 5×105次迭代。在测试过程中,将测试图像裁剪成不重叠的 128 × 128 128\times 128 128×128个 块,并且为了进行公平的比较,在相同的处理测试集上对所有基于CNN的方法进行评估。考虑分辨率为 ( H , W ) (H,W) (H,W)的图像,IDT的计算复杂度为 Θ ( ( H W ) 3 2 ) \Theta((HW)^\frac32) Θ((HW)23)。然而,如果输入图像被裁剪为固定大小的块,并且单个块的处理时间仅取决于块的大小,并且与 ( H , W ) (H,W) (H,W)无关。块总数为 H W p 2 \frac{HW}{p^2} p2HW,其中 p × p p\times p p×p是块的大小。因此,可以在 Θ ( H W ) \Theta(HW) Θ(HW)中处理图像。
4.3.2 数据集
考虑六个公共的雨痕数据集,即Rain200H、Rain200L、DDN-Data、DID-Data、SPAData、Internet-Data。
雨滴和雨痕数据集:RainDS-Syn和RainDS-Real。
雨滴数据集:AGANData
4.3.3 评估指标
遵循先前的除雨方法,采用峰值信噪比(PSNR)和结构相似性(SSIM)来评估模型性能。根据亮度通道(即YCbCr空间的Y通道)评估PSNR和SSIM。
4.3.4 实验过程
定量分析
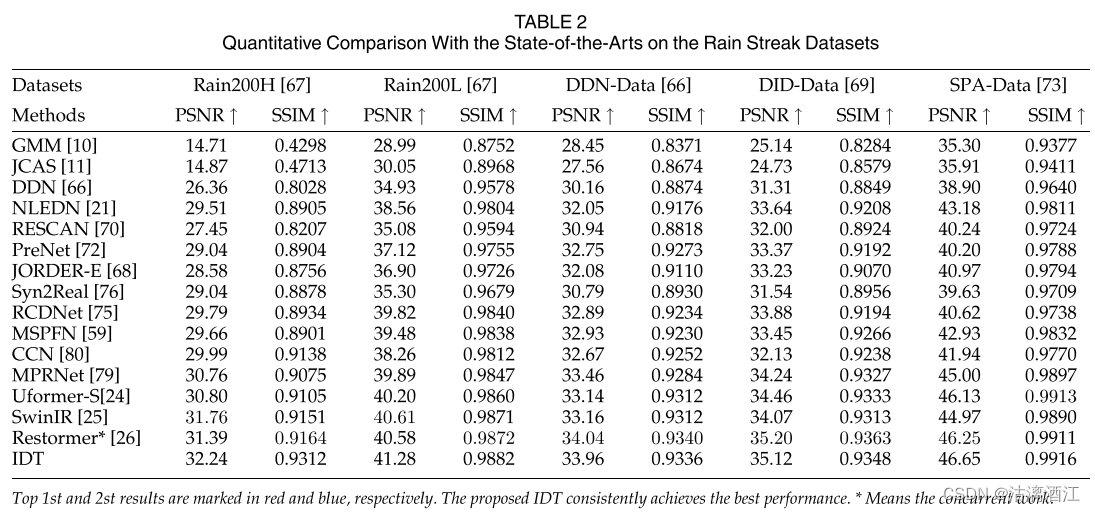
上表分别报告了雨痕去除。在去除雨纹方面,IDT的性能显着优于当前的除雨算法。
此外,通过引入非局部模块获得非局部感受野的NLEDN相比,IDT取得了显着的改进。
此外,IDT 在大多数数据集上都超越了基于Transformer的方法。
可以看出,与当前最先进的技术相比,IDT 获得了一致的性能提升。
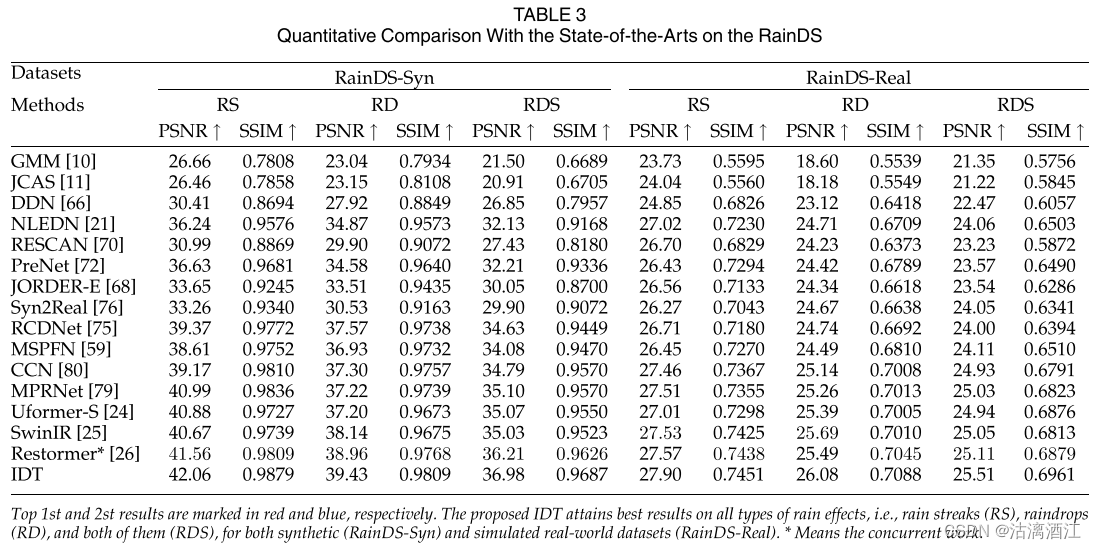
上表分别报告了联合雨滴和雨痕去除以及雨滴去除的PSNR和SSIM定量结果,IDT 比最先进的方法取得了显着的改进。
可以看出,IDT 在合成数据集 (RainDS-Syn) 和模拟现实世界数据集 (RainDSReal) 的所有类型降雨效应上都取得了最佳结果。与典型的基于 CNN 的方法相比,进步要明显得多。
这些广泛的结果从经验上证明,在单图像去雨任务中,基于Transformer的架构能够比现有的基于CNN的方法获得更好的性能。
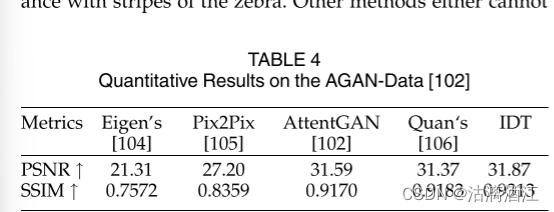
上表显示了在AGAN-Data数据集上的各模型的定量结果
定性分析
对多种下雨情况的除雨结果进行了定性比较,包括大雨条纹、小雨条纹、联合雨滴和雨条纹以及真实场景,验证IDT的有效性。

上图展示了从Rain200H中选择的示例。雨天图像包含大雨条纹,这些雨条纹表现出与斑马条纹相似的外观。其他方法要么无法清除雨纹,要么严重破坏图像细节。得益于灵活而强大的表示能力,IDT可以从局部和非局部区域中提取更具区分性的特征。因此,它在清除雨纹的同时保留更多的图像细节方面取得了最佳的可视化效果。

上图显示了来自SPA-Data的真实世界图像的去雨结果,IDT可以去除雨水伪影,同时呈现更多细节。为了评估模型的泛化能力,在现实世界的互联网数据上评估在 Rain200H上训练的模型。

上图所示,与其他方法相比,IDT取得了最令人赏心悦目的结果。对于联合雨滴和雨条纹去除,IDT 能够去除这些复杂的雨点伪影并恢复干净的背景。相比之下,其他除雨方法要么未处理雨水效果,要么导致背景模糊。
消融研究——REMSA
与之前将位置信息聚合到内容(绝对位置编码)或注意力图(相对位置编码)中的方法不同,该论文将位置建模视为一个独立的模块,并建立单独的值表示空间来捕获位置依赖性。通过从最终模型中删除单独表示和相对位置偏差来验证它们的有效性。
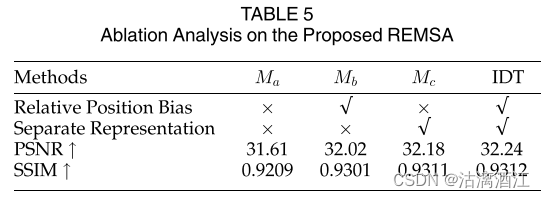
上表所示, M a M_a Ma是基本的Transformer模型,没有任何位置信息。 M b , M c M_b,M_c Mb,Mc分别代表使用相对位置偏差和单独表示的两种变体。
其说明移除位置信息 (Ma) 会导致 PSNR (> 0:6dB) 和 SSIM (> 0:01) 显著下降。此外,来自相同价值代表空间的基于内容的部分可能有更多的改进。
此外,单独表示(Mc)可能比相对位置偏差(Mb)带来更多的改进。最后,同时配备两者的模型取得了最佳效果。
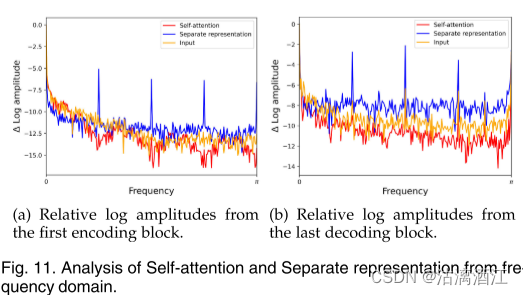
对频域分离表示的函数进行了分析。具体来说,分别通过自注意力和分离表示对输入特征和生成特征执行离散傅里叶变换(DFT)。
如上图所示,自注意力近似充当低通滤波器,这可能有助于过滤高频噪声。然而,抑制高频不可避免地会导致图像纹理的损失。相比之下,单独表示可以补充自注意力的低通特性,并为高频纹理提供补救措施。表明分离表示可以利用位置信息并保留高频结构信息。值得注意的是,分离表示可以有效地实现为卷积。这些结果意味着卷积可以补充自注意力,这与最近关于多头自注意力(MSA)的低通特性以及卷积和MSA的互补性的研究一致。
消融研究——剪裁距离 σ \sigma σ的影响
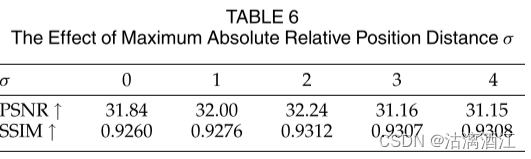
结果如上表所示。当 σ = 2 \sigma=2 σ=2时,模型获得最佳性能,当 σ > 2 \sigma>2 σ>2 时,模型似乎无法获得进一步的改进。
消融研究——Spatial Transformer Module 的验证
分别用基于窗口的Transformer模块(W-IDT)和移位窗口Transformer模块(SW-IDT)替换空间Transformer模块。值得注意的是,W-IDT只能在每个编码阶段对本地窗口内的依赖关系进行建模,而SW-IDT能够捕获相邻窗口的关系。因此,可以根据感受野的大小对这些模型进行排序:W-IDT < SW-IDT < IDT。

这些变体在基准Rain200H上的评估如上表所示。基于这些结果得出以下结论:
- IDT 在PSNR和SSIM方面获得了最佳性能,验证了空间变换模块的有效性。
- 性能排序为W-IDT < SW-IDT < IDT,与感受野大小的排序一致。这些结果为非局部感受野有利于单幅图像去雨提供了证据。

为了减轻对输入内容的依赖,从Rain200H中随机挑选100个测试图像,然后在空间Transformer模块中记录平均注意力图,即 s o f t m a x ( A + B ) softmax(A+B) softmax(A+B)。考虑来自第一个、第二个编码块和最后一个解码块的注意力图,即使在第一个编码块中,模型也能学习捕获非局部关系。当涉及第二个编码块时,注意力图表现出不规则且非局部模式。类似地,对于最后一个解码块,捕获了遥远且复杂的关系。
模型有效性
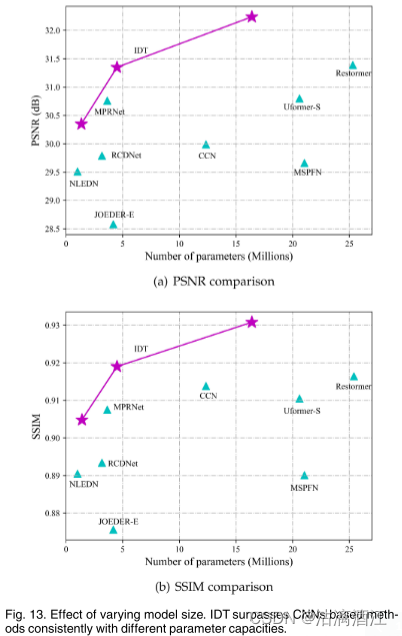
模型大小:将图1中的C设置为8、16和32,分别对应模型大小1.4M、4.5M和16.4M。在Rain200H上进行评估,并与几种性能最好的方法进行比较,如上图所示。随着模型的增大,效果有明显提升,且IDT的性能相较于相同大小的其他模型有一定的优势

失败次数&运行时间:将IDT (C=32)与其他方法进行比较,如上表所示。可以看出,IDT实现了相对较低的计算成本。与基于CNN的方法(例如MPRNet和MSPFN)相比,IDT可以以较小的 失败次数获得更好的性能。
与IPT的比较结果

如上表所示,IDT可以以更小的成本实现与IPT相称或更好的性能。
4.4 结论
4.4.1 CNN和Transformer的优缺点
CNN的内在结构意味着CNN包含很强的归纳偏差,即局部性和平移不变性,这可能有利于计算机视觉任务。
然而,Transformer表现出更强大的表达能力,因为它们可以提取基于位置和基于内容的特征,而 CNN 则仅依赖于位置来建模关系。
此外,傅立叶变换特征表明,自注意力往往充当低通滤波器,而CNN可以通过保留一些有用的高频分量来补充它,这与最近的发现一致。
4.4.2 IDT
提出了一种基于Transformer的分层架构,为了模拟远程依赖关系,设计了空间Transformer模块来补充基于局部窗口的Transformer模块。因此,网络可以在每个编码/解码阶段从非局部区域提取和融合特征。此外,所提出的相对位置增强型多头自注意力(REMSA)为基于内容和位置的注意力提供了更大的灵活性。在包含各种降雨伪影的几个具有挑战性的合成和现实世界除雨数据集上评估了所提出的 IDT,并且IDT比其他最先进的方法表现出极大的优越性
三、HW4——Speaker Classificaiton
识别经过处理的声音讯号(数据处理部分代码已经给出),确定该段声讯由哪个人发出
处理后data_size为batch_size * seq_length*dim
simple baseline:使用了TransformerEncoder层
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layer=2)
out=self.encoder(out)
mdedium baseline:源代码中d_model:40,相较于预测的n_spks:600,因此调整d_model:224。TransformerEncoder使用3层TransformerEncoderLayer。设置dropout=0.2。FC层从2更改至1,并加入BatchNorm。更改为step:100000
def __init__(self, d_model=224, n_spks=600, dropout=0.2):
super().__init__()
self.prenet = nn.Linear(40, d_model)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model,
dim_feedforward=d_model*2, nhead=2, dropout=dropout)
self.encoder = nn.TransformerEncoder(self.encoder_layer,
num_layers=3)
self.pred_layer = nn.Sequential(
nn.BatchNorm1d(d_model),
nn.Linear(d_model, n_spks),
)
Strong Baseline:将transformerEncoder修改为ComformerBlock
!pip install conformer
from conformer import ConformerBlock
# 模型中的主要改动
def __init__(self, d_model=224, n_spks=600, dropout=0.25):
super().__init__()
self.prenet = nn.Linear(40, d_model)
self.encoder = ConformerBlock(
dim = d_model,
dim_head = 4,
heads = 4,
ff_mult = 4,
conv_expansion_factor = 2,
conv_kernel_size = 20,
attn_dropout = dropout,
ff_dropout = dropout,
conv_dropout = dropout,
)
self.pred_layer = nn.Sequential(
nn.BatchNorm1d(d_model),
nn.Linear(d_model, n_spks),
)

Boss Baseline:将mean pooling修改为self-attention pooling,使用简单的additive margin softmax,将batch size从32修改至64,将step修改为200000
class SelfAttentionPooling(nn.Module):
def __init__(self, input_dim):
super().__init__()
self.W = nn.Linear(input_dim, 1)
def forward(self, batch_rep):
att_w = F.softmax(self.W(batch_rep).squeeze(-1), dim=-1).unsqueeze(-1)
utter_rep = torch.sum(batch_rep * att_w, dim=1)
return utter_rep
from torch.autograd import Variable
class AMSoftmax(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input, target, scale=5.0, margin=0.35):
cos_theta = input
target = target.view(-1, 1) # size=(B,1)
index = cos_theta.data * 0.0 # size=(B,Classnum)
index.scatter_(1, target.data.view(-1, 1), 1)
index = index.byte()
index = Variable(index).bool()
output = cos_theta * 1.0 # size=(B,Classnum)
output[index] -= margin
output = output * scale
logpt = F.log_softmax(output, dim=-1)
logpt = logpt.gather(1, target)
logpt = logpt.view(-1)
loss = -1 * logpt
loss = loss.mean()
return loss
其他可参考的修改,使用正常的additive margin softmax,最后使用ensemble+TTA
前者提升有限。后者与可见要求相悖,因为其要求使用单个模型达到boss baseline
小结
本文主要内容
本文首先针对上周学习的GCN中的数学知识——傅里叶变换,进行了较为细致的学习。然后了解了transformer架构,该架构可以分为两个部分encoder、decoder。随后介绍了多种可以用于优化transformer的多种方式。本周完成的第二个主要任务是阅读了题为Image De-Raining Transformer的论文,其主要提出了用于图像除雨任务的模型IDT。该模型中建立了分层encoder-decoder去雨结构。此外,论文中提出了互补的基于窗口的transformer模块与空域transformer模块。其还提出了相关位置增强多头注意力机制,对位置信息单独建模。最后本文完成了HW4,介绍了各种标准下的关键修改并给出相关代码,主要完成了strong baseline的代码运行
encoder部分:先将输入向量化,进行位置编码,输入自注意力块,最后输入FC层。
自注意力块:首先输入多头注意力层,然后进行残差计算,即将处理后与未处理数据相加后进行归一化处理。该部分再encoder中有多个。残差计算有多种选择方式,本文中仅介绍transformer中的方式。
decoder部分:该部分以AT decoder的形式进行,即上次的结果为下次的token。其与encoder的主要区别是首个多头注意力层是带有遮罩的。带遮罩的层再处理数据时仅考虑已经阅读的部分及其本身,且其注意力机制是交叉的,键值矩阵使用encoder中的,查询矩阵使用遮罩层的。
下周计划
完成自注意力机制类别总结课程。尝试手算transformer模型,以增强对该模型的理解。继续阅读transformer相关的论文,可能会完成hw5。
参考文献
[1] Oriol Vinyals, et al. “Grammar as a Foreign Language.” arXiv.Org, 9 June 2015, arxiv.org/abs/1412.7449.
[2] J. Xiao, X. Fu, A. Liu, F. Wu and Z. -J. Zha, “Image De-Raining Transformer,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 12978-12995, 1 Nov. 2023, doi: 10.1109/TPAMI.2022.3183612.

















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









