







文章目录
python | Pandas/bokeh 实现交互数据可视化报告
前言
- 这是一篇写给过去自己的教程, 如果你跟四个月前的我一样, 对编程几乎没认知, 也可以看懂.
- 这也是一篇写给未来自己的备忘, 以后重现这个项目, 或做类似项目时, 不需重构思路, 也不需再次检索已经检索过的内容.
- 时间报告见: Time Report
- 设计原理见: Time Report’s Report 时间报告的报告 | Li Guanghe’s blog
需求
- 图文展示一年中时间分配
- 类型频率及持续时间
tools
Python
Python 做数据分析有完整的工具链条.
往深, 可以实现 Deep Learning 的项目(Scikitlearn/Tensorflow)
往浅, 也可以实现表格(二维矩阵)的处理
本次即使用较浅的部分,处理表格(虽然只有一张, 但很长)
Pandas
数据科学最小工具链
| python | numpy | pandas | Matplotlib(/bokeh) | Scikit-Learn(/tensorflow) |
|---|---|---|---|---|
| list | array | matrix | plot | |
| . | . | index,column,column,column | . | |
| l=[,] | a=[[,] | index, | ||
| . | [,]] | index, | ||
| l | np.xxx | pd.dataframe(np.xxx) | plot.xxx.(pd.dataframe(np.xxx),x,x) | |
| NumPy’s Structured Arrays | Pandas df operates like a tructured array | Visualization with Matplotlib |
Bokeh
matplotlib 和 bokeh 选哪个?
- Jupyter 常见可视化框架的选择
- 我希望导出 html并且可交互, 故选择 bokeh.
- 内部显示的话, matplotlib也很顺手, 有时会现用它展示, 再重新用 bokeh写一次.
需求->代码实现
以需求为底, 逐步拆解到实现.
处理 .csv 格式的表格
- 导入, 并将其转化为 DataFrame(以下简称df, pandas 可以处理的数据形式. 如上表格显示, 与 list 相似,也是数据形式, 但可以被 pandas 处理. pandas.DataFrame.from_csv
- 导出也可为 .csv, 因在本项目中不需要导出表格, 故省略.
- 举例
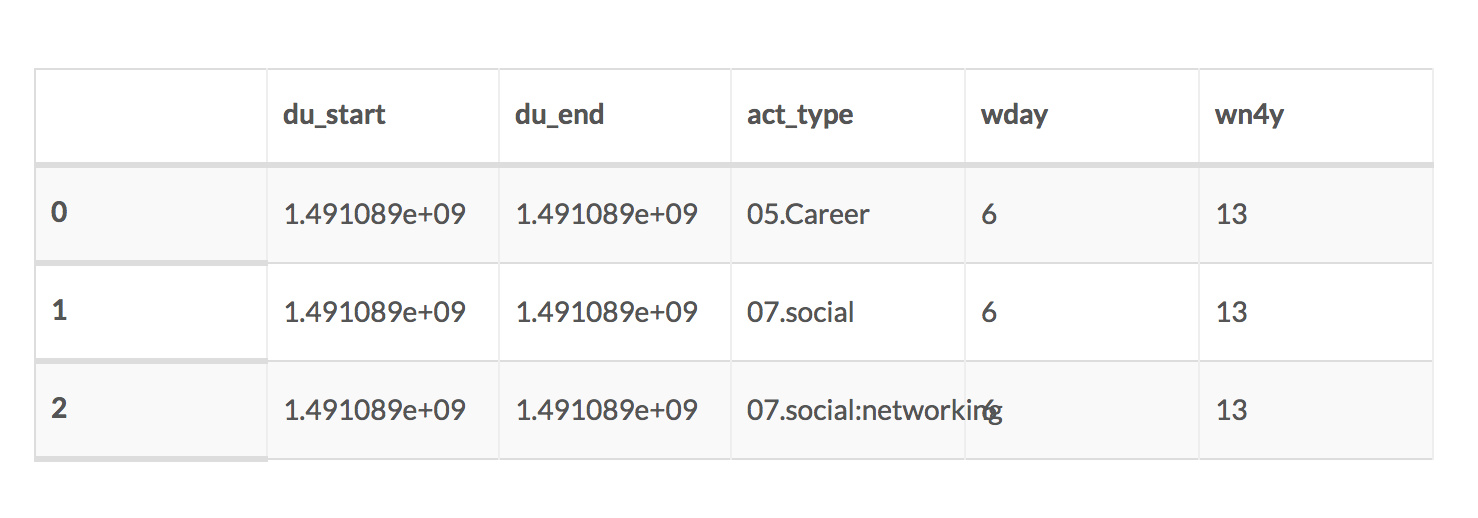
- 原始数据格式如下:
du_start,du_end,act_type,wday,wn4y
1491088707.0,1491088708.0,05.Career,6,13
1491088708.0,1491088865.0,07.social,6,13
- 转换后格式如下:
import pandas as pd
df = pd.read_csv('/Users/liguanghe/atl4dama/src/_rp4lgh/df_isocalendar4lgh.csv')
df.head(3) #显示头部, 还可以显示尾部 tail(), 显示描述 describ() ,括号里填写数字, 即可限定显示多少行
计算各类型每周总用时
目标: 上述列表转化成如下列表
- columns 是各类别
- index 是 week
- values 是 总用时 即每类别每周的总用时
df3[44:45]

实现
- 增加列, 这列的内容可以根据前面各列的数据, 计算得出.
- lambda
- pandas.DataFrame.apply
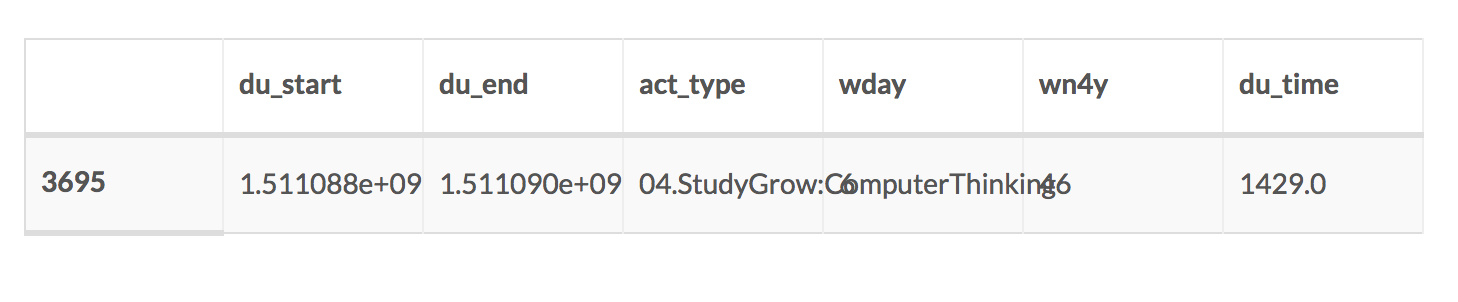
- du_start 是开始的秒数, du_end 是结束的秒数. du_time 即结束减去开始, 即持续时间.
df['du_time'] = df.apply(lambda x: x.du_end-x.du_start, axis=1)
df.tail(1)
- df中 某一列, 去掉重复的元素后, 有哪些, 可用来分类和计数.
- 计算有多少类行为, 这些行为都在 act_type 这一列中.
- 计算有多少周 都在 wn4y 这一列中.
import numpy as np
UniqueAct = df.act_type.unique()
- 按照某一列中特有的某一元素 提取行,
- eg:要从 df 中提取出 在 act_type 中都是 sleep 的行 重组一个矩阵. c = df[df[‘act_type’].isin([‘sleep’])
- 在矩阵 c中提取出 在wn4y 中都是 14 的行 重组一个矩阵 c[c[‘wn4y’].isin([‘14’] 即第14周的所有 sleep 的数据.
- 某一列求和 np.sum(df).[‘columnA’], eg: np.sum((c[c[‘wn4y’].isin([week])])[‘du_time’] 及某一行为某一周的总秒数, /60/60, 可得小时.
- 使用 for in 循环, 即可将所有行为不同周的总小时数计算出来. 添加到 list l. 同时列出 list a(行为) , list w(week). 将三个列表连在一起, 形成新的矩阵. d4 = {‘act’:a, ‘week’:w,‘sum’:l} pd.DataFrame(d4)
- 矩阵里的元素只取小数点后一位 .round(1)
l = []
a = []
w = []
for i in UniqueAct:
c = df[df['act_type'].isin([i])]
Uniqueweeks = df.wn4y.unique()
for week in Uniqueweeks:
a.append(i)
w.append(week)
l.append(np.sum((c[c['wn4y'].isin([week])])['du_time'])/60/60)
d4 = {
'act':a,
'week':w,
'sum':l}
to= (pd.DataFrame(d4).round(1)).set_index('act')
- 将某一列的内容变成 columns 另外一列的内容变成 index, 第三列的内容作为 values的方法.
- 以’ act’作为 index, pandas 针对 index 提供检索的功能 .loc[]
- eg: ((pd.DataFrame(d4).round(1)).set_index(‘act’)).loc['sleep] 即在所有 index 中检出行为 在这个基础上, 再使用 .set_index(‘week’), 将周作为 index
- 事先建立一个纵轴为52周的矩阵, 在这个矩阵后面添加过滤过的矩阵.
ls = list(range(52))
df3=pd.DataFrame(ls)
for act in UniqueAct:
df3[act]= (to.loc[act]).set_index('week')
df3.tail(1)
分类制表
有了按照类型分周的总用时的矩阵 df3,可根据自己的希望的分类选择类型, 组建新表. 下面是特有的类型
df3.columns
Index([ 0, '05.Career',
'07.social', '07.social:networking',
'09.HealthFun:sport', '12.sleep:noonsleep',
'04.StudyGrow:reading', '11.traffic',
'04.StudyGrow:writer', '04.StudyGrow:ComputerThinking',
'09.HealthFun:fun', '08.familylife:washingbeauty',
'12.sleep', '08.familylife:families',
'08.familylife:dinner', '08.familylife:generalAffair',
'04.StudyGrow', '04.StudyGrow:law',
'08.familylife:finance', '09.HealthFun',
'09.HealthFun:fantasy'],
dtype='object')
- select data with loc Indexing and Selecting Data
- 举例, 睡眠包括午睡和晚上的睡眠
sl =df3.loc[:,['12.sleep','12.sleep:noonsleep']]# :指所有的index,即所有的行, ['','']是要选择的 column, 即列
sl[44: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









