







文章目录
爬虫的五个步骤:
- 1.需求分析
- 2.寻找网址
- 3.下载网站的返回内容(需要用到:requests)
- 4.通过网站的返回内容找到需要爬取的数据(需要用到:正则表达式re,XPATH-lxml)
- 5.存储找到的数据内容(需要用到:MySQL)
其中,步骤1、2是我们自己根据自己的需要去分析设定的,步骤3、4、5是需要自己写程序来执行的。
需求分析
假如需求是:爬取十万张美女图片:
- 首先我们需要的图片
- 其次是美女图片,准确定位需求,不然什么照片都爬取下来,肯定是不符合要求的
- 就以下图为例:
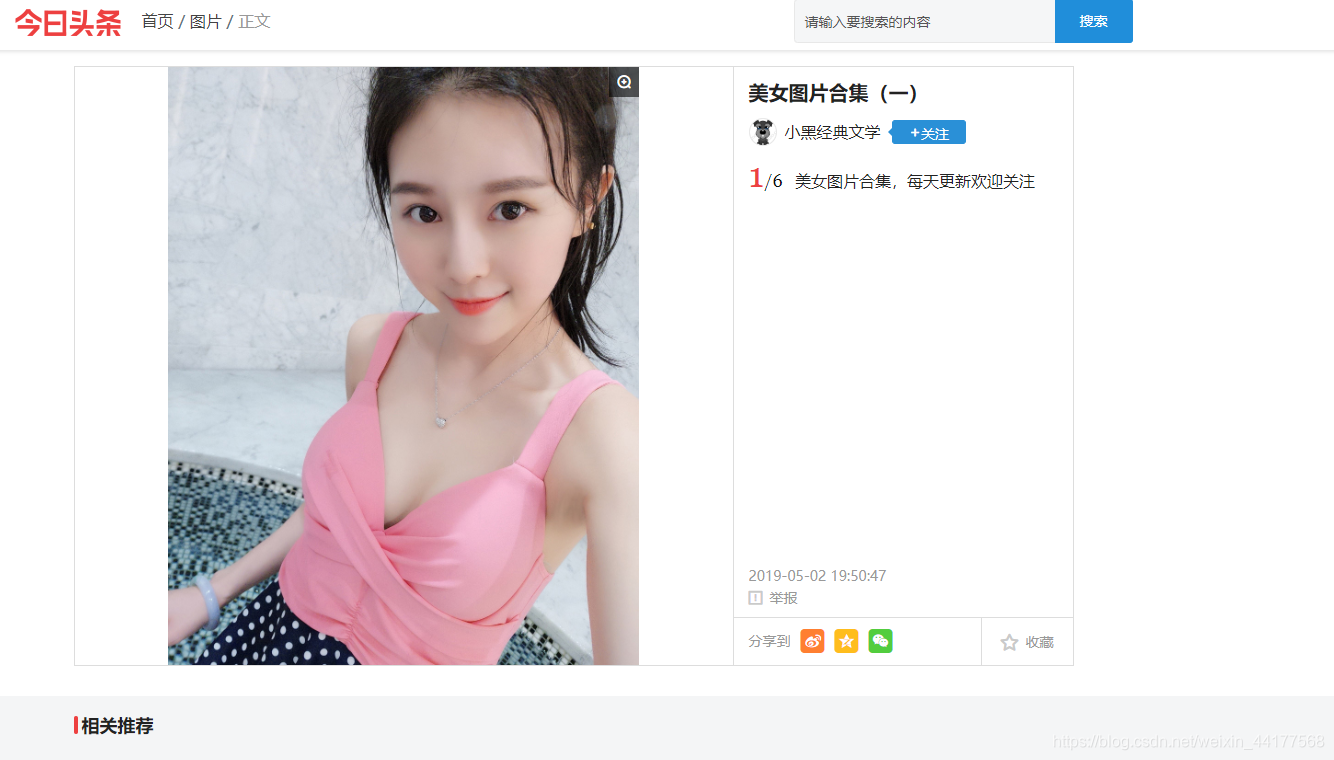
寻找网址(URL)
今日头条上面就有很多的照片,所以在今日头条中直接搜:美女图片,如上图
下载网站的返回内容
我们在图片上点击鼠标右键,再点击Inspect(检查),就可以弹出网页的HTML,
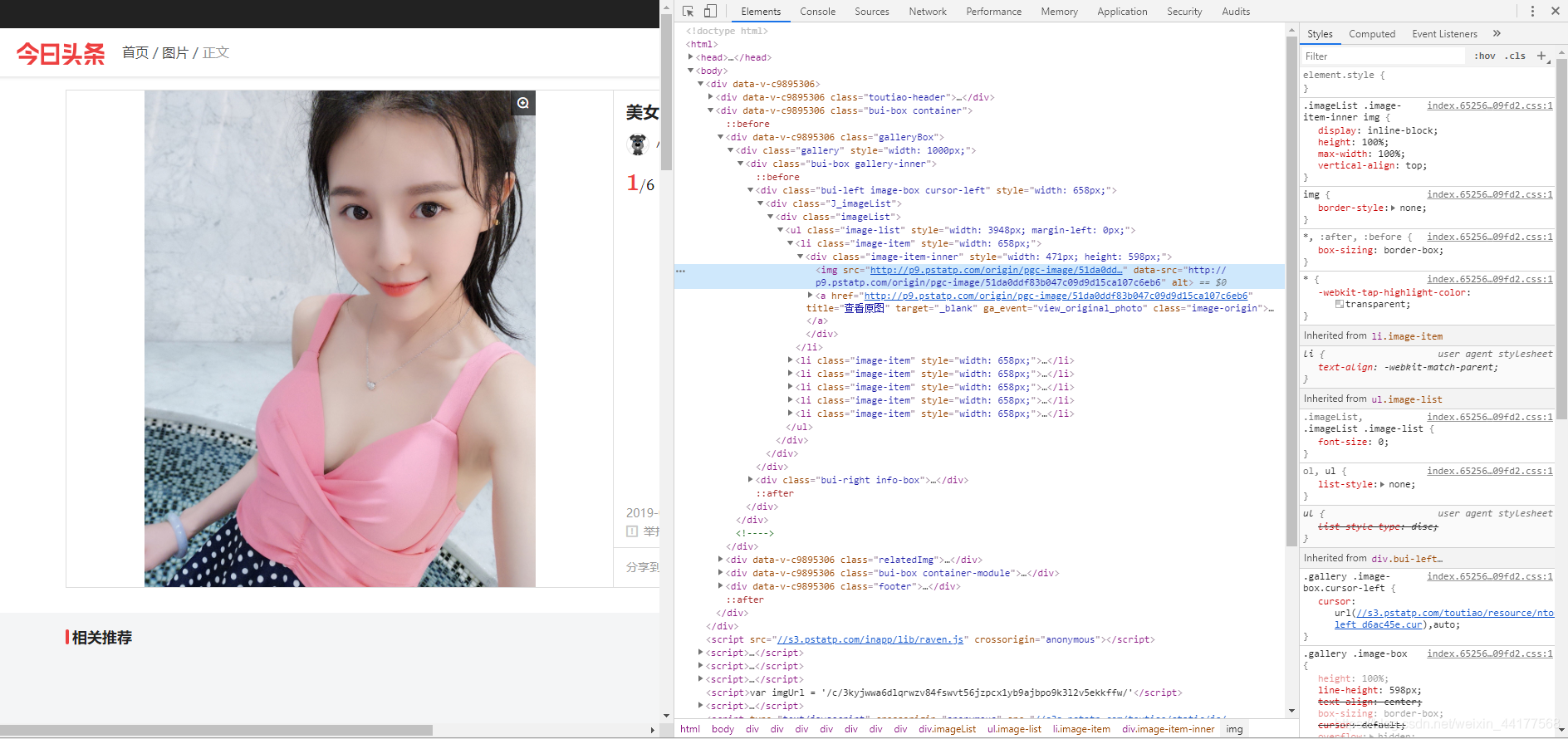
通过网站的返回内容找到需要爬取的数据:
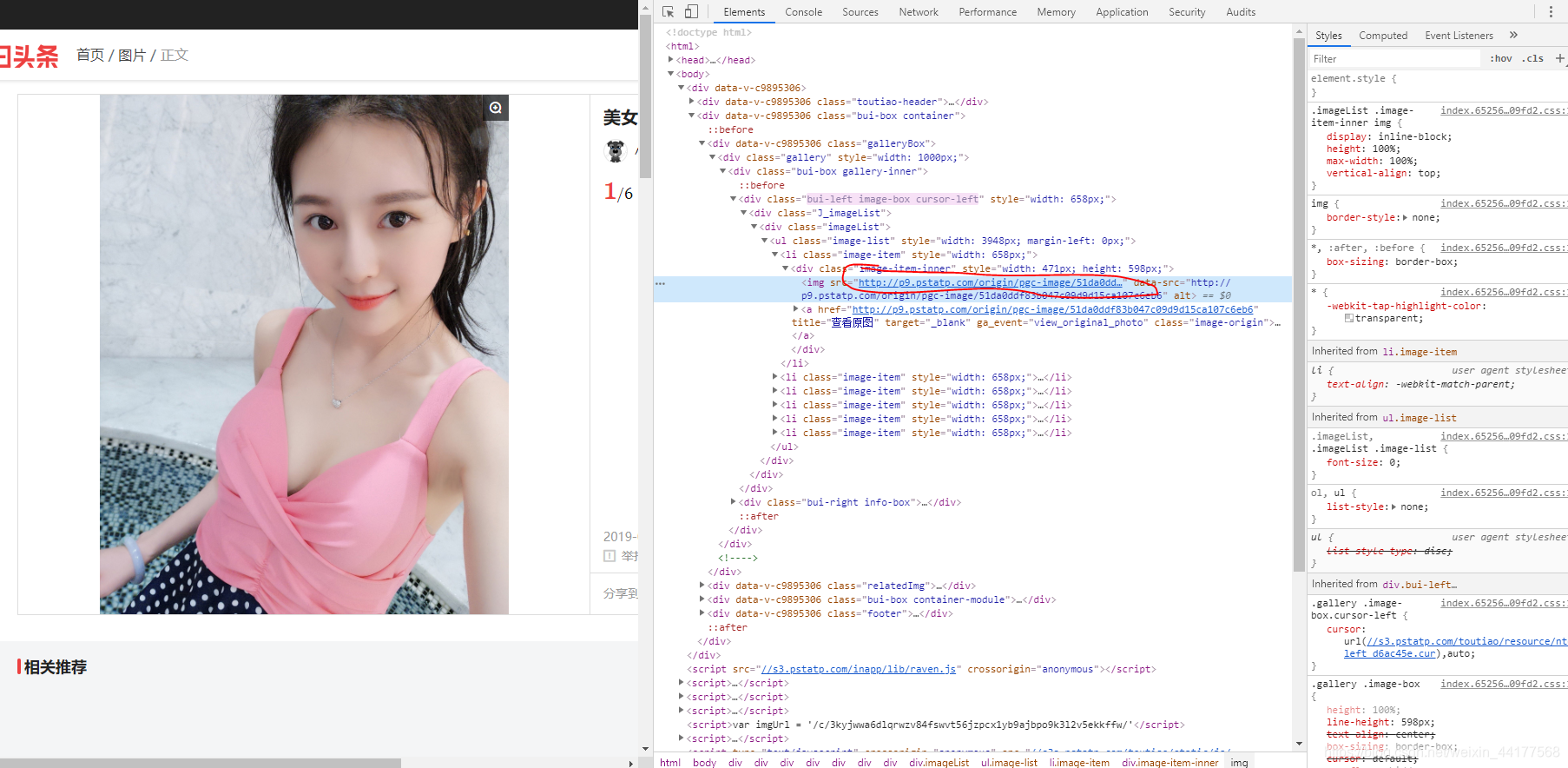
其中标红的部分,就是我们要找的图片的地址
存储找到的数据内容:
我们将标红的地址复制出来,在新的标签页打开,然后下载存储,就完成了一张图片的获取。

总结:
1、先考虑需求
2、考虑在哪里可以下载到
3、找到对应的HTML
4、找到我们最终需要的图片jpg
5、存储jpg文件

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









